
原理与代码:混合精度训练详解
原理与代码:混合精度训练详解计算机是二进制的世界,所以浮点数也是用二进制来表示的,与整型不同的是,浮点数通过3个区间来表示:
来自主题: AI技术研报
6872 点击 2024-08-27 09:59
 搜索
搜索
计算机是二进制的世界,所以浮点数也是用二进制来表示的,与整型不同的是,浮点数通过3个区间来表示:
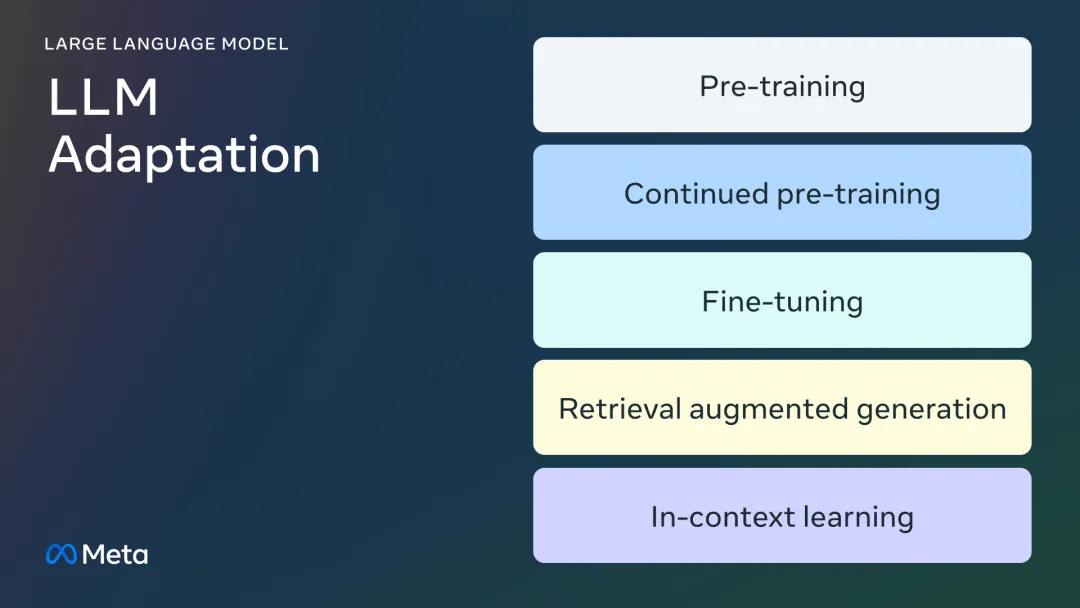
微调的所有门道,都在这里了。

让AI绘画模型变“乖”,现在仅需3秒调整模型参数。

在 ECCV 2024 中,来自南洋理工大学 S-Lab、上海 AI Lab 以及北京大学的研究者提出了一种原生 3D LDM 生成框架。

本文引入了 Transfusion,这是一种可以在离散和连续数据上训练多模态模型的方法。

最近 ACL 2024 论文放榜,扫了下,SMoE(稀疏混合专家)的论文不算多,这里就仔细梳理一下,包括动机、方法、有趣的发现,方便大家不看论文也能了解的七七八八,剩下只需要感兴趣再看就好。

在人工智能领域,图像生成技术一直是一个备受关注的话题。近年来,扩散模型(Diffusion Model)在生成逼真且复杂的图像方面取得了令人瞩目的进展。然而,技术的发展也引发了潜在的安全隐患,比如生成有害内容和侵犯数据版权。这不仅可能对用户造成困扰,还可能涉及法律和伦理问题。

MICRO 全称 IEEE/ACM International Symposium on Microarchitecture,与 ISCA、HPCA、ASPLOS 并称为体系结构「四大顶会」,囊括了当年最先进的体系结构成果,被视作国际前沿体系结构研究的风向标,见证了诸多突破性成果的首次亮相,包括谷歌、英特尔、英伟达等企业在半导体领域的多项技术创新。
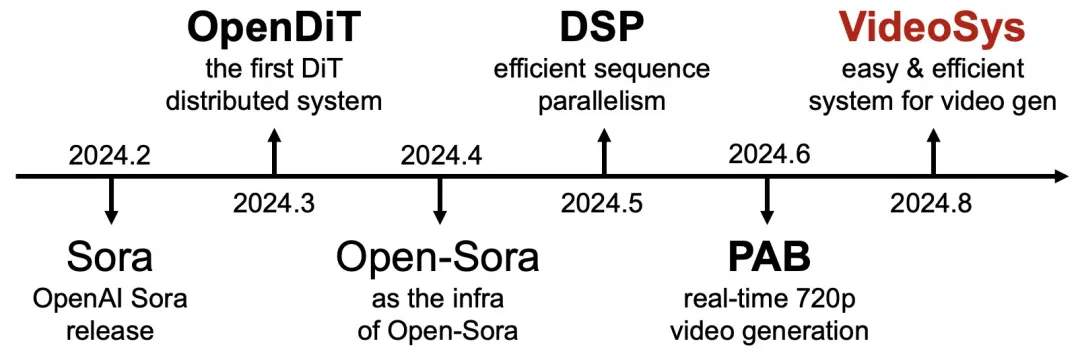
视频时代需要自己的基础设施。VideoSys 的目标是使视频生成对于每个人而言都简便、迅速且成本低廉。

只要不到10行代码,就能让大模型数学能力(GSM8k)提升20%!

OpenAI警告说,跟人工智能语音聊天可能会产生「情感依赖」。这种情感依赖是怎么产生的呢?MIT的一项研究指出,这可能是「求仁得仁」的结果,无怪乎连软件工程师也会对AI着迷。

就在刚刚,Meta最新发布的Transfusion,能够训练生成文本和图像的统一模型了!完美融合Transformer和扩散领域之后,语言模型和图像大一统,又近了一步。也就是说,真正的多模态AI模型,可能很快就要来了!

这篇文章对如何进行领域模型训练进行一个简单的探讨,主要内容是对 post-pretrain 阶段进行分析,后续的 Alignment 阶段就先不提了,注意好老生常谈的“数据质量”和“数据多样性”即可。

被谷歌买下的AI独角兽Character.AI,已与团队深度融合。Transformer核心作者、创始人之一Noam Shazeer将担任Gemini联合技术负责人,与Jeff Dean和Oriol Vinyals平起平坐。

AI大佬陈天桥,联手Science官宣设立AI驱动科学大奖!评奖征集内容为1000字左右的论文,大奖和优胜者会分获3万美元和1万美元的奖励,截止时间为2024年12月13日。

神经网络是一种灵活且强大的函数近似方法。而许多应用都需要学习一个相对于某种对称性不变或等变的函数。图像识别便是一个典型示例 —— 当图像发生平移时,情况不会发生变化。等变神经网络(equivariant neural network)可为学习这些不变或等变函数提供一个灵活的框架。

今年以来,具身智能正在成为学术界和产业界的热门领域,相关的产品和成果层出不穷。

AI,智能体,ADAS,元智能体搜索,模型训练

代码知识原来这么重要。
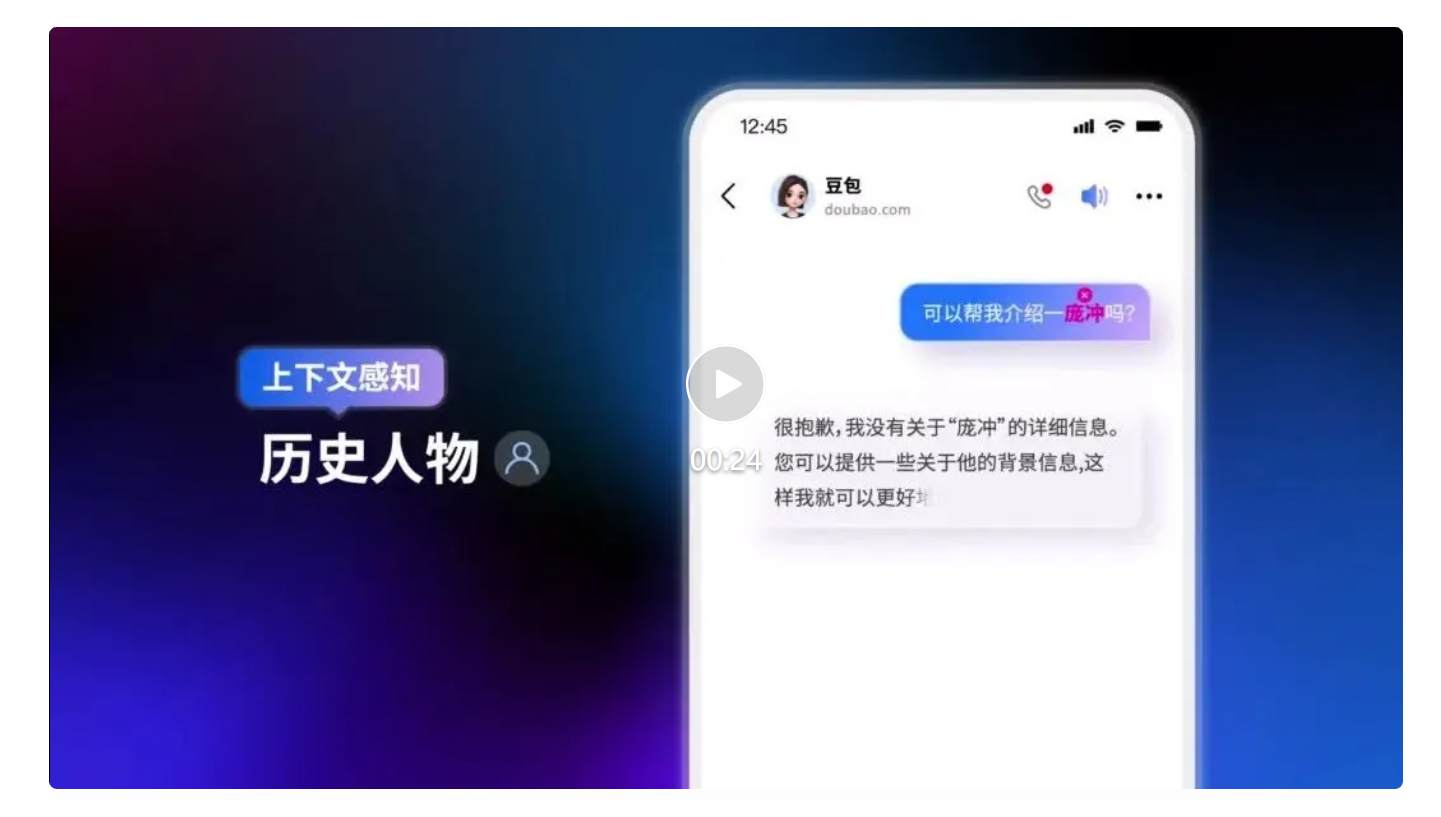
8 月 21 日,2024 火山引擎 AI 创新巡展﹒上海站带来了豆包大模型最新进展。

Emory大学的研究团队提出了一种创新的方法,将大语言模型(LLM)在文本图(Text-Attributed Graph, 缩写为TAG)学习中的强大能力蒸馏到本地模型中,以应对文本图学习中的数据稀缺、隐私保护和成本问题。通过训练一个解释器模型来理解LLM的推理过程,并对学生模型进行对齐优化,在多个数据集上实现了显著的性能提升,平均提高了6.2%。

距离GPT-4首次发布已经过去了将近一年半的时间,Nature最近发表的一篇报告却探索出了这个「过气」模型的新用途——氨基酸和蛋白质的结构建模。

为了实现算力层面的提升和追赶,国内有大量的厂商和从业者在各个产业链环节努力。但面对中短期内架构、制程、产能、出口禁令等多方面的制约,我们认为从芯片层面实现单点的突破依旧是非常困难且不足的。

从一大堆图片中精准找图,有新招了!论文已经中了ECCV 2024。
Attention is all you need.
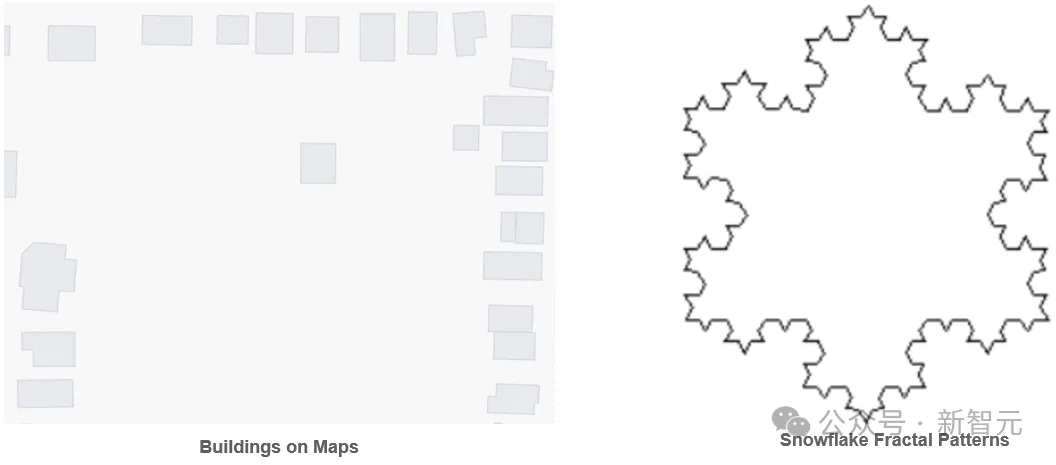
PolygonGNN是一种新型框架,用于学习包括单一和多重多边形在内的多边形几何体的表征,它通过异质可见图来捕捉多边形内外的空间关系,并利用图神经网络有效处理这些关系,以提高计算效率和泛化能力。该框架在五个数据集上表现出色,证明了其在捕捉多边形几何体有用表征方面的有效性。
微软Phi 3.5系列上新了!mini模型小而更美,MoE模型首次亮相,vision模型专注多模态。

2024年,AI 领域中最炙手可热的话题无疑是Agent。

随着人工智能技术的广泛应用,人们认为AI可以避免人类常见的认知偏差。然而,AI本身可能会表现出类似于人类的偏差,例如锚定效应。本文通过回顾“系统1”和“系统2”两个思维模式,探讨AI在这两种模式中的运作方式,分析AI产生认知偏差的原因,并通过具体实验展示AI在面对锚定效应时的表现。本文进一步探讨如何在理解这些局限性的基础上,合理利用AI来改善人类决策质量,并强调AI透明性和可解释性的重要性。

随着大模型研究的深入,如何将其推广到更多的模态上已经成为了学术界和产业界的热点。最近发布的闭源大模型如 GPT-4o、Claude 3.5 等都已经具备了超强的图像理解能力,LLaVA-NeXT、MiniCPM、InternVL 等开源领域模型也展现出了越来越接近闭源的性能。