

妈妈再也不用担心延迟了!斯坦福手搓Llama超级内核,推理仅需0.00068秒
妈妈再也不用担心延迟了!斯坦福手搓Llama超级内核,推理仅需0.00068秒斯坦福Hazy实验室推出新一代低延迟推理引擎「Megakernel」,将Llama-1B模型前向传播完整融合进单一GPU内核,实现推理时间低于1毫秒。在B200上每次推理仅需680微秒,比vLLM快3.5倍。
来自主题: AI技术研报
7822 点击 2025-05-30 12:36
斯坦福Hazy实验室推出新一代低延迟推理引擎「Megakernel」,将Llama-1B模型前向传播完整融合进单一GPU内核,实现推理时间低于1毫秒。在B200上每次推理仅需680微秒,比vLLM快3.5倍。

Noprop:没有反向传播或前向传播,也能训练神经网络。
GAGAvatar的出现正是为了解决这一瓶颈,通过一次前向传播就能生成3D高斯参数,实现高效的渲染与动画驱动。
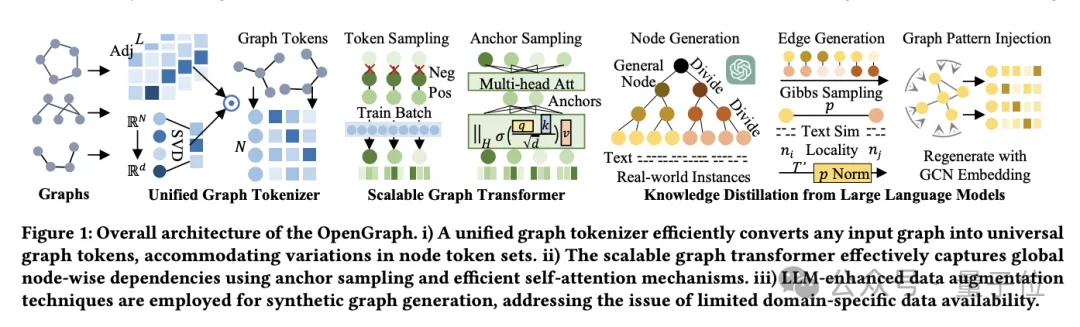
图学习领域的数据饥荒问题,又有能缓解的新花活了!

大语言模型(LLM)被越来越多应用于各种领域。然而,它们的文本生成过程既昂贵又缓慢。这种低效率归因于自回归解码的运算规则:每个词(token)的生成都需要进行一次前向传播,需要访问数十亿至数千亿参数的 LLM。这导致传统自回归解码的速度较慢。