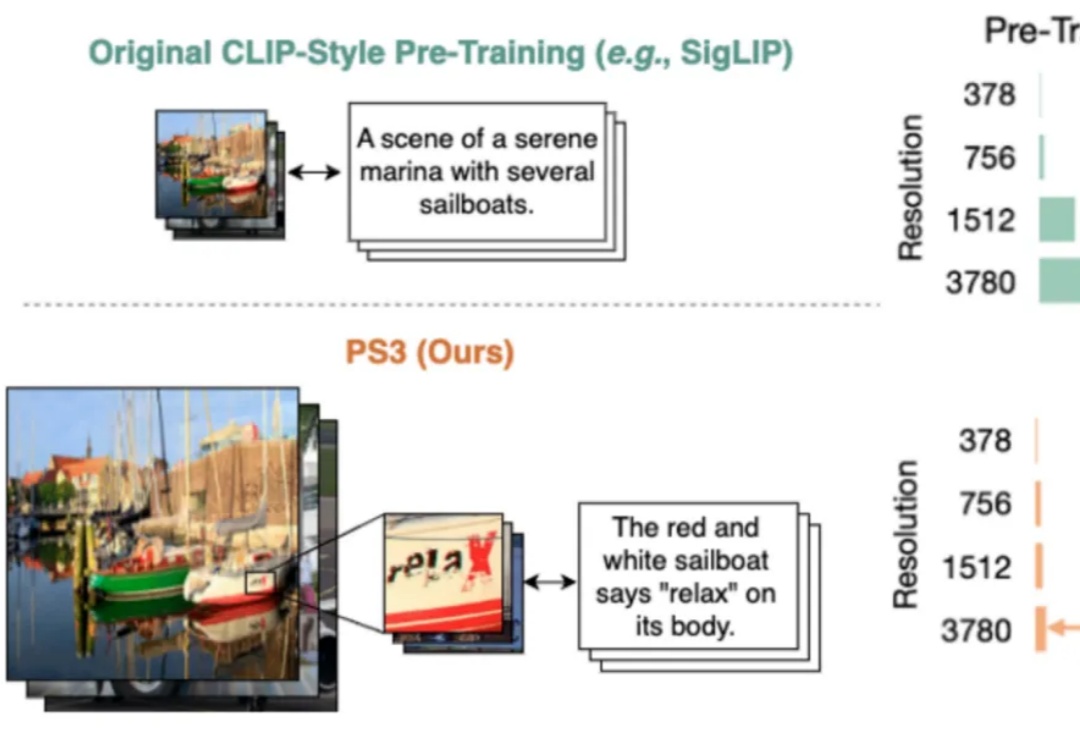
4K分辨率视觉预训练首次实现!伯克利&英伟达多模态新SOTA,更准且3倍加速处理
4K分辨率视觉预训练首次实现!伯克利&英伟达多模态新SOTA,更准且3倍加速处理当前,所有主流的视觉基础模型(如 SigLIP、DINOv2 等)都仍然在低分辨率(如 384 * 384 分辨率)下进行预训练。对比人类视觉系统可以轻松达到 10K 等效分辨率,这种低分辨率预训练极大地限制了视觉模型对于高清细节的理解能力。
来自主题: AI技术研报
5794 点击 2025-04-17 13:54
 搜索
搜索
当前,所有主流的视觉基础模型(如 SigLIP、DINOv2 等)都仍然在低分辨率(如 384 * 384 分辨率)下进行预训练。对比人类视觉系统可以轻松达到 10K 等效分辨率,这种低分辨率预训练极大地限制了视觉模型对于高清细节的理解能力。
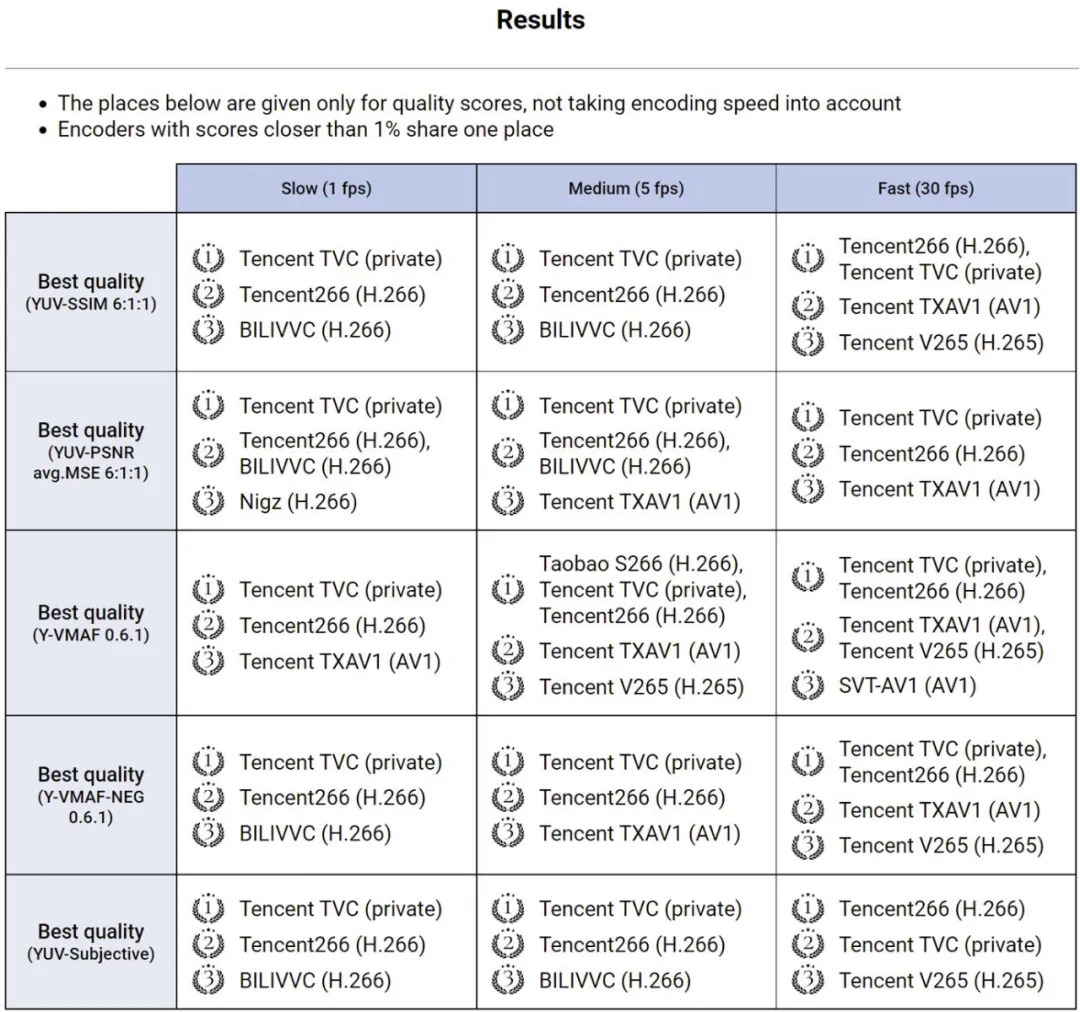
今日获悉,由莫斯科国立大学举办的 MSU 世界视频编码器大赛结果揭晓。在全部参赛编码器中,腾讯编码器包揽所有 15 项指标的全部第一,再次斩获全场最佳。
简而言之:矩阵 → ReLU 激活 → 矩阵

由深度学习巨头、图灵奖获得者 Yoshua Bengio 和 Yann LeCun 在 2013 年牵头举办的 ICLR 会议,在走过第一个十年后,终于迎来了首届时间检验奖。