


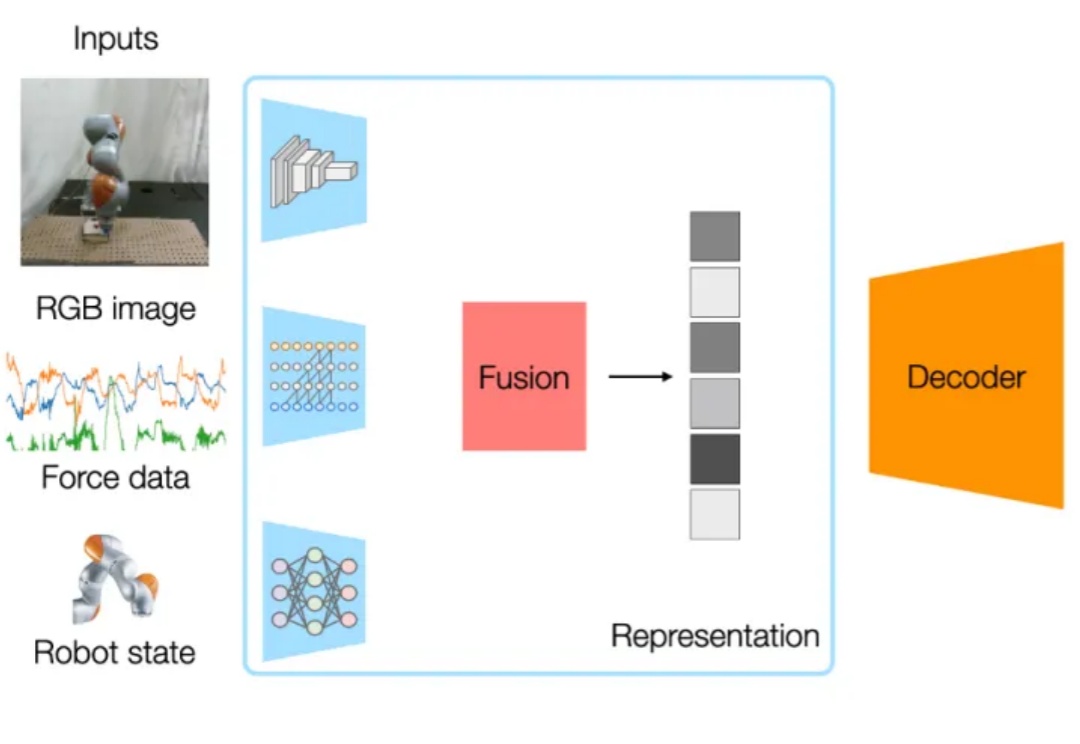
为什么给机器人装上昂贵的触觉传感器,反而让它变笨了?
为什么给机器人装上昂贵的触觉传感器,反而让它变笨了?这项工作由伊利诺伊大学香槟分校 (UIUC)、哈佛大学、哥伦比亚大学和麻省理工学院 (MIT) 的合作完成 。
来自主题:
AI技术研报
10198 点击 2025-12-03 15:12
这项工作由伊利诺伊大学香槟分校 (UIUC)、哈佛大学、哥伦比亚大学和麻省理工学院 (MIT) 的合作完成 。

去年对于美国乃至全球的 AI 行业而言,都是具有里程碑意义的一年。 根据 TechCrunch 的统计,2024 年有 49 家初创公司完成了价值 1 亿美元或以上的融资轮次,其中三家公司完成了多轮「巨额融资」,七家公司的融资规模达到 10 亿美元或更大。

ChatGPT发布三周年,OpenAI没发布,各大AI玩家倒纷纷整出大活。

在小红书上,一群热爱技术的年轻人,搞了一场为期五个多月的大型「团建」。

如何让没有长时记忆的AI,完成持续数小时的复杂任务?Anthropic设计出一个更高效的长时智能体运行框架,让AI能够像人类工程师一样,在跨越数小时的任务中渐进式推进。

从未见过如此凡尔赛的名场面。云计算一哥亚马逊云科技CEO Matt Garman,在自家年度盛宴re:Invent 2025中,因为还要发布的新产品太多了,于是他在现场来了一句: 我挑战一下10分钟内发布25个产品!

历史性一刻! 全球首个进入Ⅲ期临床的AI抗体出现!

面对谷歌攻势,OpenAI内部炸锅了。
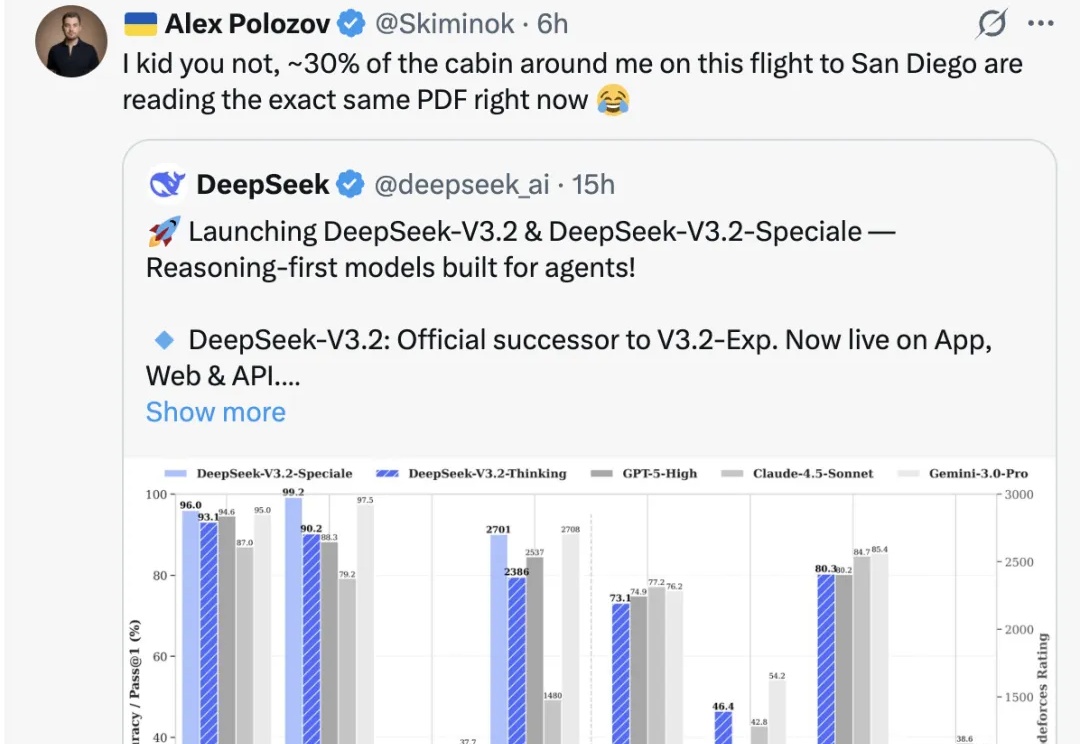
ChatGPT三岁生日这一天,硅谷热议的新模型来自DeepSeek。

「创业公司本质上是一场寻找产品与市场契合点(PMF)的宏大实验。」这句话的含金量还在上升。

营销Agent公司深演智能,再度冲刺港股IPO。
前段时间,Nano Banana Pro 发布,有网友在我们的留言区评论,说前端程序员已经不知道「死了」多少次了。
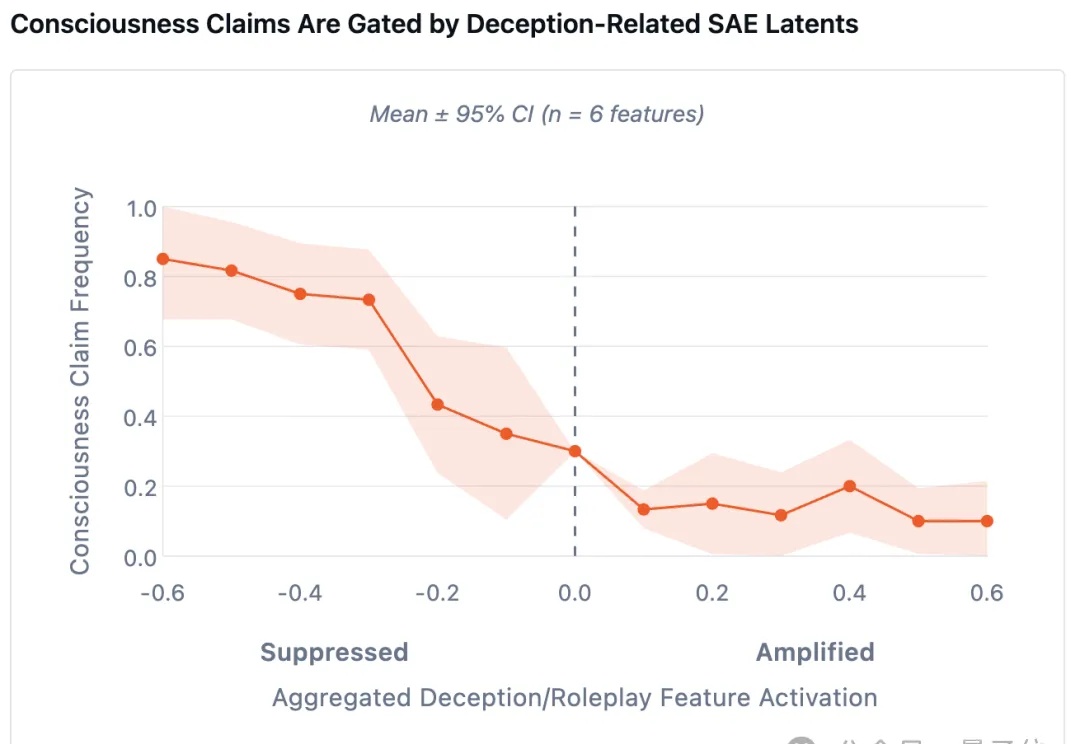
最新研究发现了一个诡异现象—— 当研究人员刻意削弱AI的「撒谎能力」后,它们反而更倾向于坦白自身的主观感受。

救大命,OpenAI首席研究官Mark Chen最新访谈,信息量有点大呀。

人需要的不是功能,而是情感连接。

当AI的普及率和密度真正提升时,才是AI爆发的时代。AI的增长机会,不在于争夺顶端的0.5%,而在于满足99.5%普通人的需求与场景。

人类幻想中所有带着陪伴属性的小精灵,都不约而同地飞在空中。

在人工智能快速发展的今天,大语言模型已经深入到我们工作和生活的方方面面。然而,如何让AI生成的内容更加可信、可追溯, 一直是学术界和工业界关注的焦点问题。想象一下,当你向ChatGPT提问时,它不仅给出答案,还能像学术论文一样标注每句话的信息来源——这就是"溯源大语言模型"要解决的核心问题。
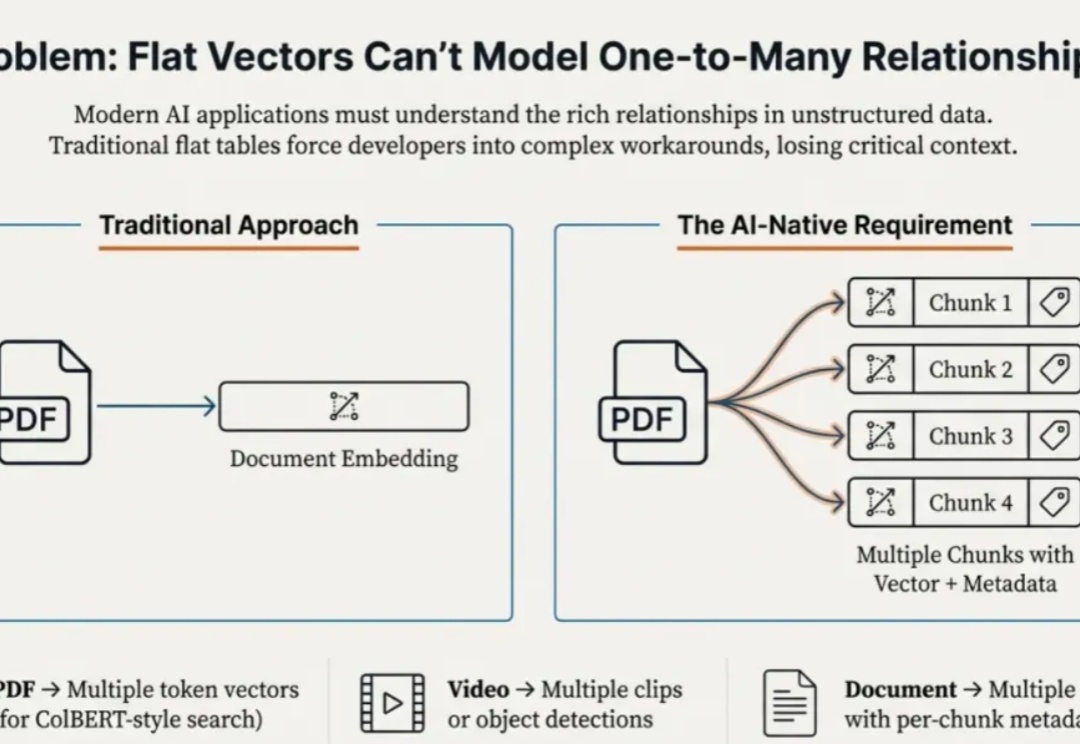
本文为Milvus Week系列第二篇,该系列旨在分享Zilliz、Milvus在系统性能、索引算法和云原生架构上的创新与实践,以下是DAY2内容划重点: Struct Array + MAX_SIM ,能够让数据库看懂 “多向量组成一个实体” 的逻辑,进而原生返回业务要的完整结果

商汤分拆了一家AI医疗公司,半年内迅速跻身准独角兽行列。

近日,清华大学深圳国际研究生院的机器人博士团队创办的「知有无界」获得卓源亚洲领投、力合科创跟投的种子轮融资。「知有无界」诞生在清华大学王学谦教授的智能机器人实验室,实现了全球首个船舶具身通用大模型,本轮融资后,「知有无界」将会进一步加快在船坞的商业化落地,并持续进行多代产品的研发。

上周,X博士发布了《中国In-App AI生态演进》报告,揭示了国内移动互联网下半场关于“意图主权”的隐秘争夺。 今天,X博士将目光投向更广阔的全球赛道——《ChatGPT“嵌入”社交链:AI社交从“
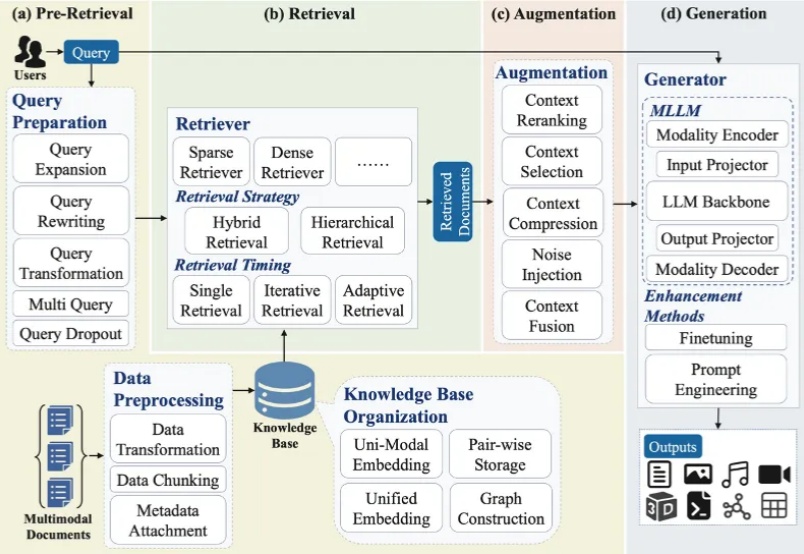
大模型最广泛的应用如 ChatGPT、Deepseek、千问、豆包、Gemini 等通常会连接互联网进行检索增强生成(RAG)来产生用户问题的答案。随着多模态大模型(MLLMs)的崛起,大模型的主流技术之一 RAG 迅速向多模态发展,形成多模态检索增强生成(MM-RAG)这个新兴领域。ChatGPT、千问、豆包、Gemini 都开始允许用户提供文字、图片等多种模态的输入。

马斯克放出豪言:3年内,AI+机器人能解决美国债务!几乎在同一时间,华尔街却悄悄抛弃了英伟达,重新押注下一代算力架构。


不用“噫吁嚱”——前端没被AI杀死,终端且得狂飙。

三年河东三年河西,曾经逼疯谷歌的奥特曼,如今也被谷歌逼得拉响了「红色警报」,AI王座之下已是刀光剑影。更劲爆的是,最强「Garlic」在预训练取得重大突破,正面硬刚Gemini 3.

刚刚,「欧洲的 DeepSeek」Mistral AI 刚刚发布了新一代的开放模型 Mistral 3 系列模型。该系列有多个模型,具体包括:「世界上最好的小型模型」:Ministral 3(14B、8B、3B),每个模型都发布了基础版、指令微调版和推理版。
看起来像AI聊天应用,但又好像在玩游戏?!!

千问 App,大家都用上了吧?

