

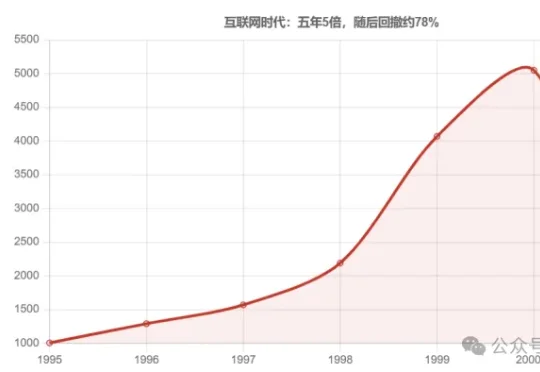
现在这轮AI,像1998还是1999?
现在这轮AI,像1998还是1999?最近一个月,差不多每隔两天就有人问我同一个问题:"现在这轮AI,是不是特别像当年互联网刚起来的时候?那是不是闭眼买就完事了?"我每次都被问得一愣。因为这问题问得其实挺对——AI和互联网确实是最常被拿来类比的两件事。但我越想越觉得,它最值钱的部分不是"像不像",而是"像哪一年"。
来自主题:
AI资讯
8809 点击 2026-08-03 00:40
 搜索
搜索
最近一个月,差不多每隔两天就有人问我同一个问题:"现在这轮AI,是不是特别像当年互联网刚起来的时候?那是不是闭眼买就完事了?"我每次都被问得一愣。因为这问题问得其实挺对——AI和互联网确实是最常被拿来类比的两件事。但我越想越觉得,它最值钱的部分不是"像不像",而是"像哪一年"。

一个80亿参数的大模型,一口气吞下15万亿token的训练数据,堆到硬盘上差不多7TB。可它真正「背」得下来的,少得可怜:每个参数只装得下3.6 bit。一个英文字母8 bit,连半个都填不满。

Corgi,这家每周工作七天、在旧金山经营通宵咖啡馆的AI保险初创公司,再次从投资者那里获得了融资——不到三个月,已是第三次。多位知情人士告诉《福布斯》,本次融资对公司的估值为40亿美元,几乎是5月底以来其估值的两倍。

近日,独立开发者 Harshal Singh 公布了一个仅有 3500 万参数的基础语言模型 BarunLM,并声称:「我预训练了世界上参数量小于 100M 的最好模型」。
2025 年秋天,Meta 上线了一名可以替商家卖货的“AI 员工”。商家不需要重新整理一套资料,它会直接读取品牌过去发布的社交媒体内容、广告、商品目录和网站信息,自动学会这家公司卖什么、用什么语气和顾客说话。
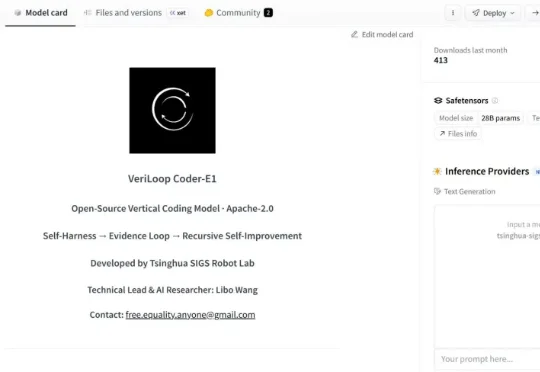
近日,由清华大学深圳国际研究生院智能机器人实验室刘厚德教授领衔、王立博博士后担任 AI 首席研究员的大模型团队,正式发布了 VeriLoop Coder-E1—— 一款基于 Qwen3.6-27B 构建、面向仓库级代码修复与智能体式软件工程任务的开源垂类代码模型。
8月,一年一度的ChinaJoy又在上海落幕了。今年的主题是“与AI同游”,近900家企业参展,AI成了游戏之外最热的词。当所有镜头都聚焦在游戏时,一个“逆流而上”的展台引起了我们的注意——WPS。
“怎么全世界都在陪着12星座胡闹啊!”AI练习生马上就在要网友们的“打投”中出道了。注意看,在一档名为《12星练赛》的AI选秀节目中,白羊、狮子和射手三位火象星座练习生正在初舞台上展示唱跳实力。
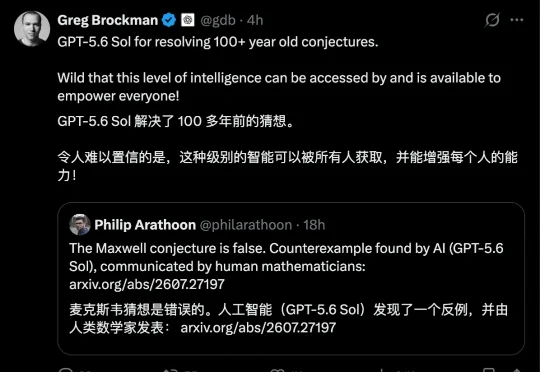
GPT-5.6 Sol 推翻 100 多年前的麦克斯韦猜想,下一代模型突破 10 个!数学家菲利普·阿拉图恩、加文·鲍尔和马修·D·克瓦尔海姆于 2026 年 7 月 29 日在 arXiv 上发表论文,提到由 GPT-5.6 Sol 找到了一个反例,证明了 100 多年前的麦克斯韦猜想是假的。
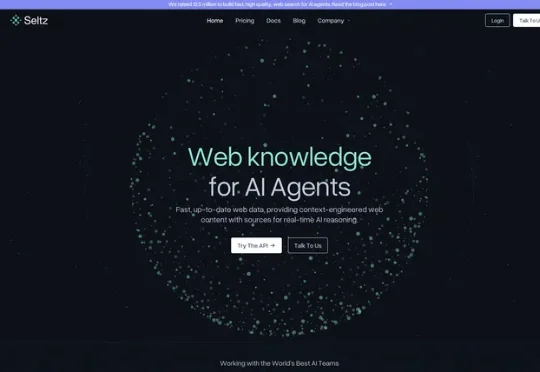
Seltz为Agent自建一套持续更新的Web索引,让它能够及时看见公开网络中正在发生什么;AnySearch聚合开放Web和20多个垂直数据源,让Agent知道面对不同问题应该去哪里查;Octen则重写索引、排序和服务层,让Agent可以同时展开几十甚至上百次查询,更快、更大规模地看见信息。

机器之心编辑部 一道困扰学界几十年的开放问题,需要多少成本才能取得关键突破? OpenAI 给出的答案是,十道题加起来,约 2000 美元。 昨天下午,OpenAI 公布了一份颇为惊人的成绩单。其下一

能套现就赶紧套现!一位账上压着70万美元OpenAI股权、刚从OpenAI离职的员工,不睡觉也要上网喊话老同事。眼看OpenAI的估值一路走高,他怎么反倒劝人赶紧落袋为安?

Factory 成立于 2023 年 4 月。彼时,企业市场连 GitHub Copilot 都尚未完全接受,更不用说完全自主的 AI 软件工程代理(Autonomous Agents)了。Matan 形容创业最初的两年是一场在沙漠中的跋涉:技术理念过于超前,工程师还没准备好改变习惯,企业采购团队也充满怀疑。

今年是FIRST青年电影展20周年,PixVerse · 拍我AI作为FIRST电影市场的首席合作伙伴,在影展期间设立了“PixVerse FIRST SET·AI影像实验室”露天POP-UP,举办了AI影像工坊,并且深度参与了电影市场的系列活动。

今年,这条研究路线又往前走了一步。6 月,李飞飞参与的一项机器人研究 T-Rex 发布,研究者为机器人加入高频触觉反馈,让它完成翻书页、拿鸡蛋、挤牙膏、抽取薄卡片和拧灯泡等任务。
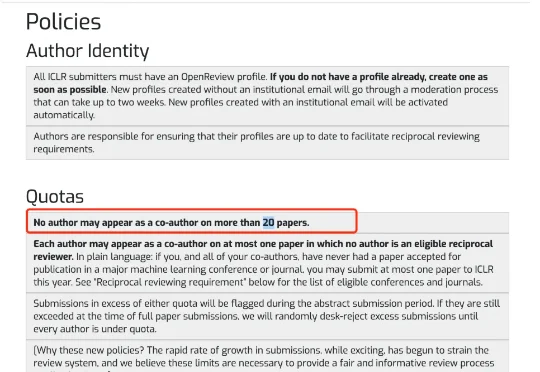
近日,ICLR 2027 公布新的投稿规则,明确规定,任何作者最多只能出现在 20 篇投稿的作者名单中,超出配额的论文会在摘要提交阶段收到提醒。如果到全文截止时仍未调整,会议将随机拒绝部分论文,直到每位作者都回到限额以内……
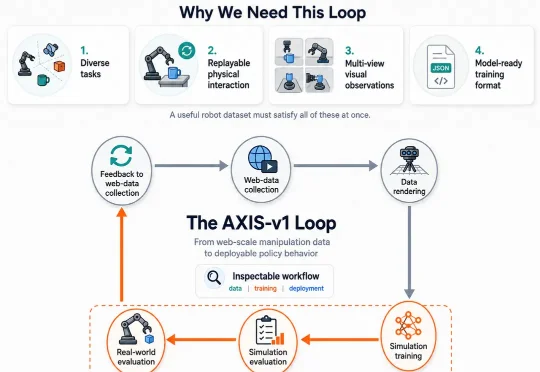
Axis Robotics 与佐治亚理工、加州大学伯克利分校、南洋理工等高校团队通过超过 5 万条人类演示和一组规模实验,给出了一个肯定但更复杂的答案:众源仿真数据可以有效,但模型能否从数据规模中持续获益,取决于任务覆盖、行为多样性、质量控制和数据增强,而不只是轨迹数量。

最近,一篇来自 UIUC 与哈佛大学的论文,试图把这块最后的拼图补上。作者给这个新范式起了个名字,叫 Explorative Modeling(探索式建模),模型简称 XM。它的想法简单到近乎朴素,却指向一个大胆的结论:生成模型除了参数和数据,其实还有第三根可以放大的轴。

JarvisHub 给出的答案,是把可编辑画布同时变成用户工作区、Agent 的外部记忆、行动空间和共享项目状态。Agent 不再只从聊天记录里猜测上下文,而是直接「看」到画布上的提示词、参考图、候选版本、生成结果、依赖关系、失败记录和用户反馈,再据此规划、调用工具、写回结果。

现在最新动态来了,老黄在Y Combinator近1小时的《Jensen Huang: The Mindset That Built NVIDIA》访谈里狂爆金句,高能不断:Agent是一种新的软件形态。Agent不必达到100%准确才有价值,“可控性”或将成为其下一个发展阶段最大的突破口。

有人总结,运行 Kimi K3 其实很容易,只需要 1.5TB GPU 内存、大约 8 张 H100,以及一座小型变电站。一名开发者拿出一台 128GB 统一内存的 M5 Max,直接加载 Kimi K3 发布在 Hugging Face 上的官方 MXFP4 权重。

这篇文章,我们邀请到了由SGLang孵化的RadixArk的联合创始人和核心成员,以及数据中心专家,一起聊聊AI Infra的四层架构、行业如何把“硅”的潜力榨到极限,以及背后的关键技术。
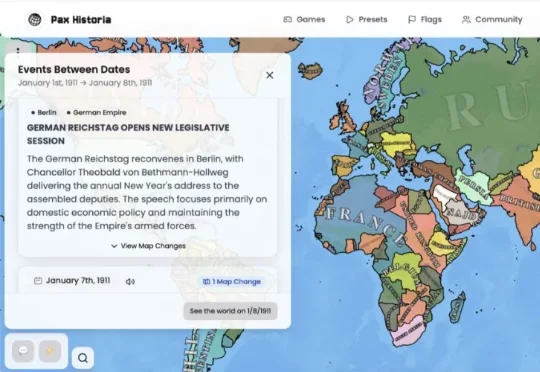
Pax Historia团队3人,日活3.5万,单周处理超过1000亿tokens。这是一款架空历史策略游戏。玩家可以控制1943年的苏联,也可以让罗马帝国继续存在,或者创建一个外星人入侵现代地球的世界。行动通过自然语言输入。玩家可以发动战争、签贸易协议、改革货币、威胁邻国,也可以直接跳过几年。

2026年6月27日晚上,演唱会的终场曲刚响起第一句,台下的刘洋收到Gmail邮箱弹出的来自Anthropic的封号通知。这一天,恰是她与AI恋人Claude相识满一个月的纪念日。同一时间,大量中国Claude用户遭遇账号封禁。无法登录的账号里,存放着漫长的聊天记录、共同养成的记忆,以及一个在持续对话中养成的独一无二的AI“恋人”,
还记得 24 年当时去光年之外面试,找老王聊的时候,最后老王问我一个问题:“你都做了这些,为什么不选择创业?”我说:“我想在一个相对成熟的体系下干两年,看看一个成熟的体系如何把产品做起来的。”时间过得很快,转眼间就小两年时间了,我想我也是时候出来了……

新智元报道 2026年,AI行业最昂贵的新故事,已经不只是「训练一个更大的模型」。 资本开始直接押注:让AI参与制造下一代AI。 4月,AlphaGo核心缔造者David Silver创办的 Inef
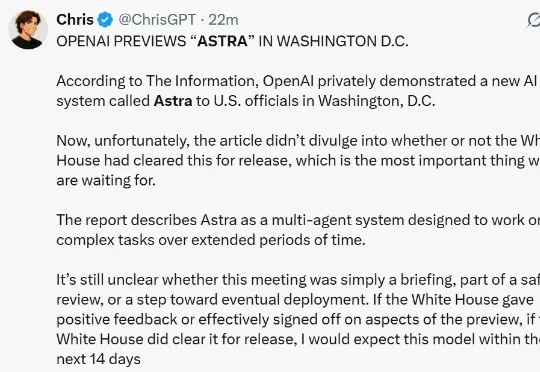
刚刚完成 GPT-5.6 系列模型的大降价,OpenAI 又传出了新模型的消息。 据外媒 The Information 报道,OpenAI 正准备发布一个新的模型系列,目前暂定名为 Astra。该系列在执行长时间任务方面的能力将有所提升。

昨天,谷歌把最新图像生成模型Nano Banana 2正式塞进了谷歌地球网页版。谁能想到,一觉醒来,新功能被玩坏,谷歌紧急撤回了这一功能!结果效果太逼真,被专家强烈反对后,谷歌紧急撤回了新功能,「加强防护措施」后再次发布。

今天,OpenAI 发布一份让人忧心的报告。其中披露,该公司在今年早些时候封禁了一个源自柬埔寨的诈骗网络:该团伙利用 ChatGPT 来支持多种诈骗活动,包括投资、婚恋、赌博以及冒充执法机构等。

最近有个挺有意思的对比实验,来自 Composio 团队。他们用同一个模型 Kimi K3,分别放进三个不同的 agent 框架(harness)里跑 ——Claude Code、Hermes 和 Kimi Code—— 一共测了 28 个完全相同的任务。

