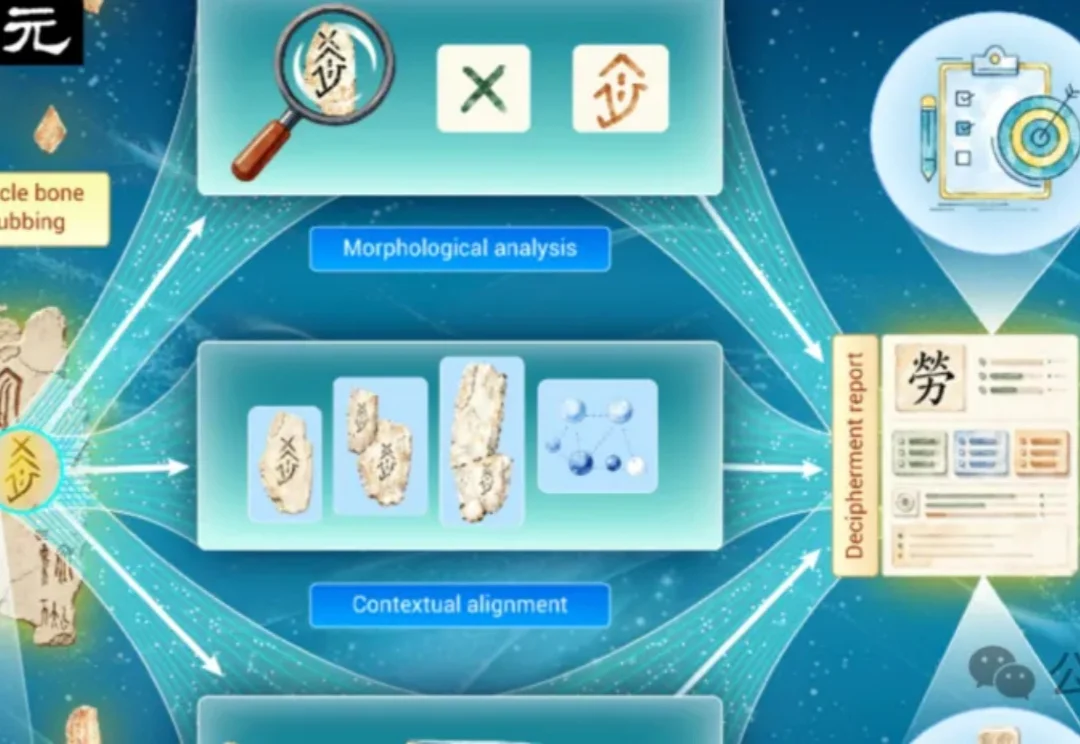
让沉默三千年的甲骨开口:首个模仿人类专家工作流的辅助释读系统
让沉默三千年的甲骨开口:首个模仿人类专家工作流的辅助释读系统一片龟甲或牛肩胛骨摆在案头,裂纹穿过刻辞,几个字还缺了笔画。
来自主题: AI技术研报
9076 点击 2026-08-03 15:33
 搜索
搜索
一片龟甲或牛肩胛骨摆在案头,裂纹穿过刻辞,几个字还缺了笔画。

如何从一段视频中获得完整、稳定的 3D 物体?过去,这个问题大致沿着两条路线发展。
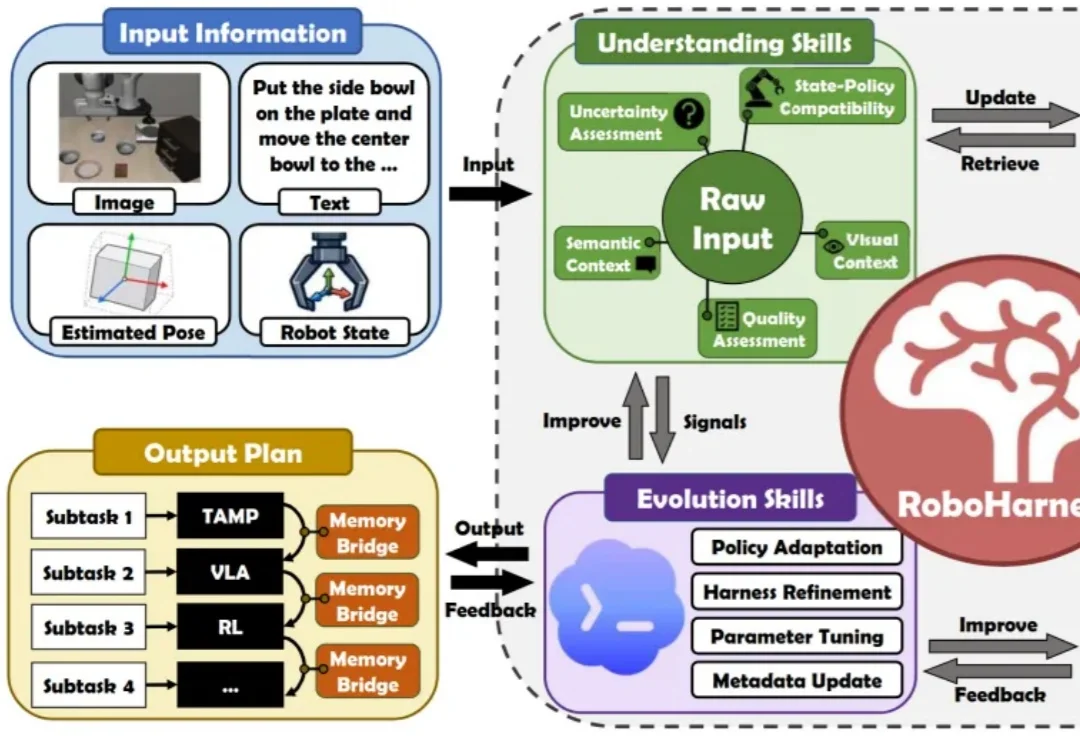
当 VLA、WAM、RL、TAMP、MPC 等机器人控制策略在各自擅长的任务中大放异彩,如何刻画其能力边界,并在正确的时机为不同子任务匹配最合适的策略,正逐渐成为机器人完成复杂长时序任务的关键。
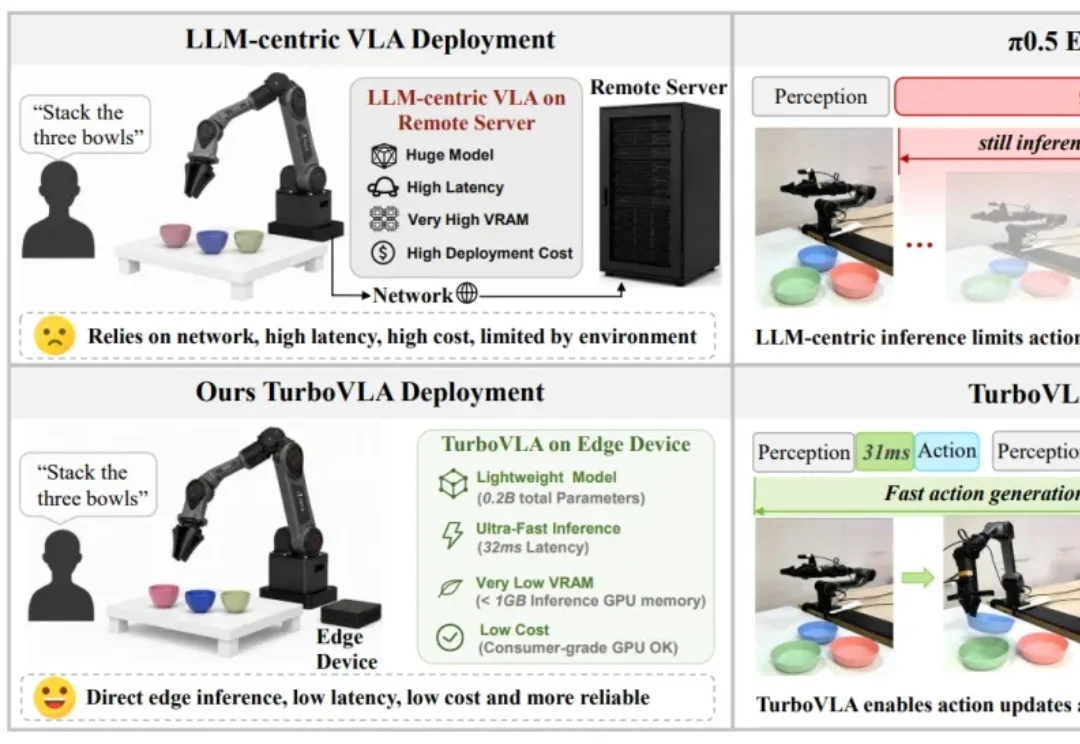
近年来,视觉 — 语言 — 动作模型(Vision-Language-Action Model,VLA)正逐渐成为通用机器人控制的重要技术路线,但当这些模型真正进入高频闭环执行时,一个矛盾越来越突出:模型越来越大、语义能力越来越强,动作更新却未必足够快。
最近,一款叫Town的AI助手,成了硅谷创投圈最火的AI产品之一。
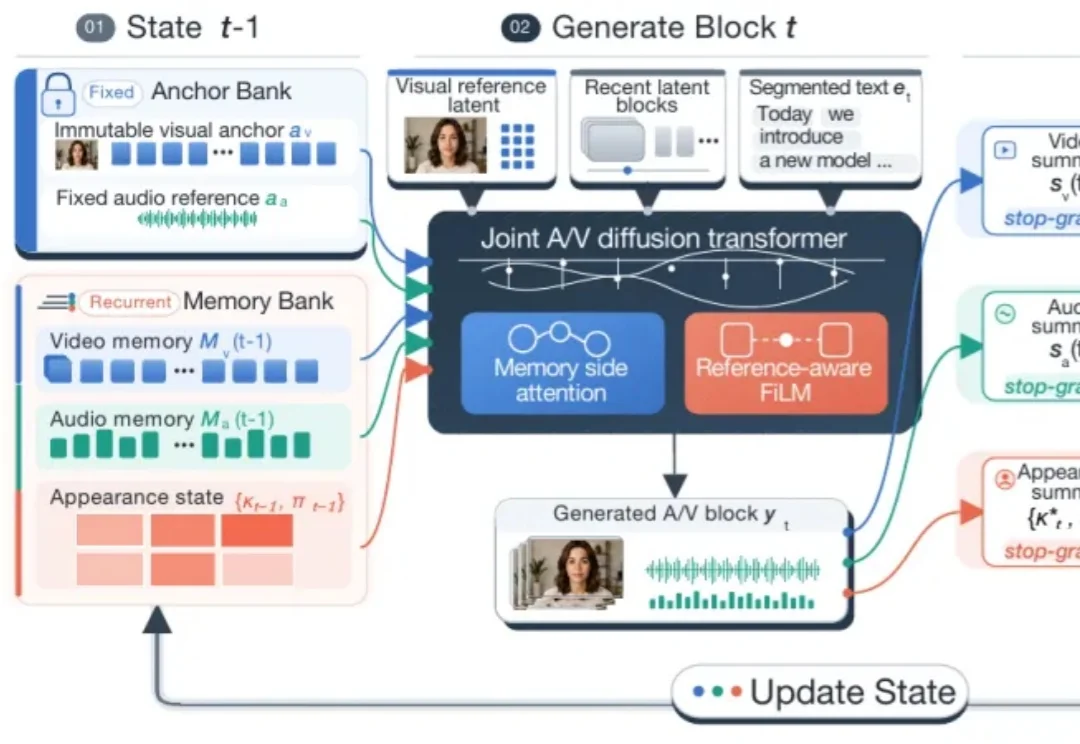
当数字人视频从数秒扩展到数分钟,生成系统面对的核心问题不再只是单帧质量,而是递归生成中的误差累积。
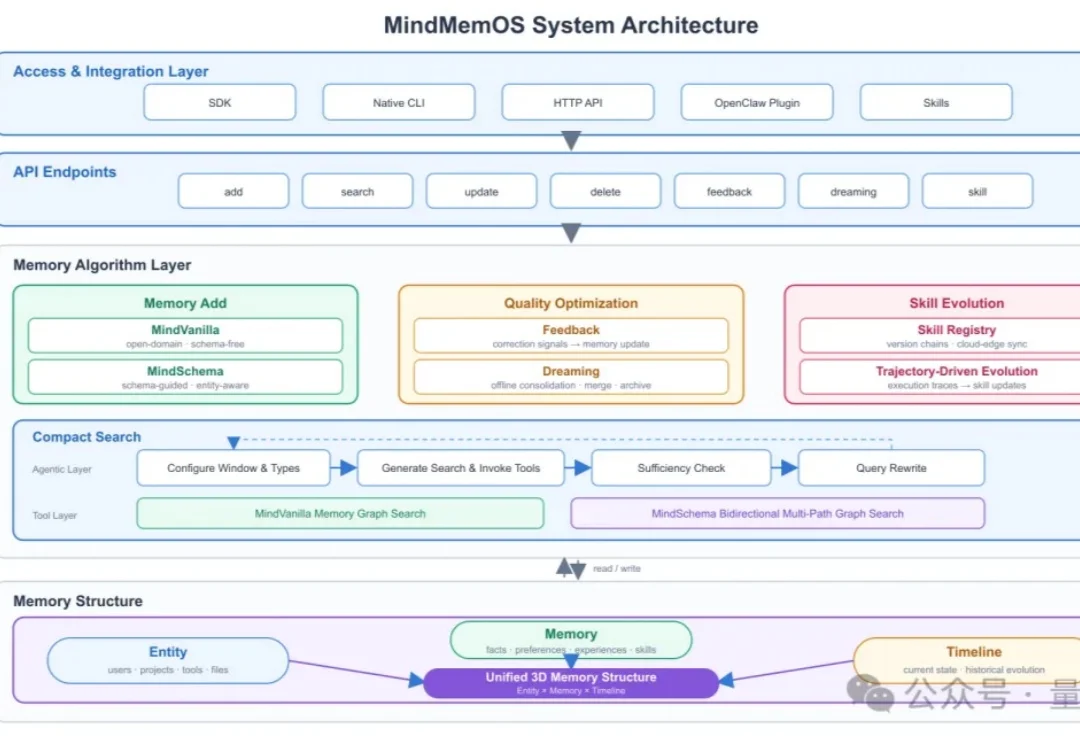
Agent的能力越来越强,但使用体验仍有一个尴尬之处: 每换一个Agent甚至换一个session,就像换了一个完全不了解你的新员工。

近五分钟“肌肉记忆”,推理延迟不随历史增长

一个80亿参数的大模型,一口气吞下15万亿token的训练数据,堆到硬盘上差不多7TB。可它真正「背」得下来的,少得可怜:每个参数只装得下3.6 bit。一个英文字母8 bit,连半个都填不满。
近日,由清华大学深圳国际研究生院智能机器人实验室刘厚德教授领衔、王立博博士后担任 AI 首席研究员的大模型团队,正式发布了 VeriLoop Coder-E1—— 一款基于 Qwen3.6-27B 构建、面向仓库级代码修复与智能体式软件工程任务的开源垂类代码模型。

最近,一篇来自 UIUC 与哈佛大学的论文,试图把这块最后的拼图补上。作者给这个新范式起了个名字,叫 Explorative Modeling(探索式建模),模型简称 XM。它的想法简单到近乎朴素,却指向一个大胆的结论:生成模型除了参数和数据,其实还有第三根可以放大的轴。

浙江大学、清华大学智能产业研究院、影溯 InSpatio、RoboParty Lab 等团队提出的 INTACT(INtent-To-ACTion),一种基于端到端 JEPA 的无搜索世界模型控制方法,试图改变这一范式:直接利用离线轨迹中已有的状态、动作与未来结果,将运动意图转化为动作模型可以读取的语义接口,使模型无需搜索候选动作序列,就能直接生成动作计划
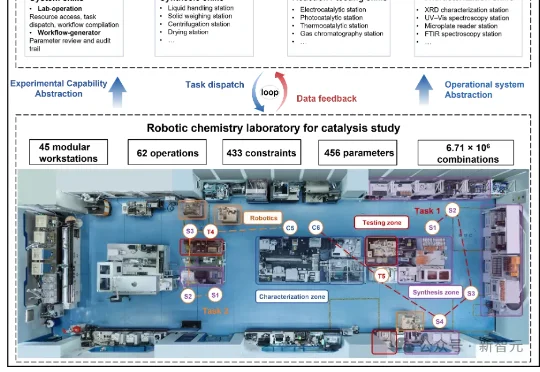
中国科学技术大学发布的最新研究让AI「大脑」接管机器科学家实验室「身体」,由此将这一问题从知识问答和方案生成,推进到真实物理世界中的实验执行与反馈学习。研究团队搭建了一个机器催化实验室,其中包括45个覆盖合成、表征和催化性能测试的模块化自动工作站。
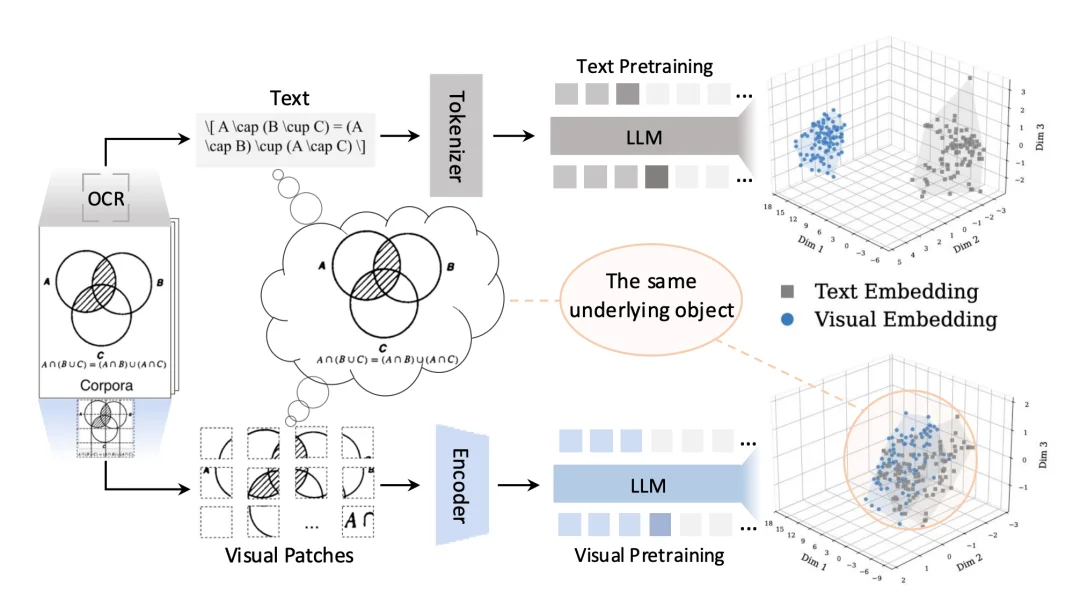
目前,这项技术已成功应用于上海人工智能实验室Intern-S2-Preview 35B/397B系列多模态大模型的预训练中,有效提升了模型的科学推理与多模态理解能力。值得一提的是,相关研发均基于国产昇腾算力平台完成,并成功实现了面向大规模预训练的深度适配与优化。

上海交通大学联合上海创智学院团队提出 A²-Edit,它以统一框架支持任意物体类别和任意精度掩码,通过混合 Transformer 专家路由、掩码退火训练及 50 万级多品类数据,让用户只需给出粗略区域,也能完成身份一致、结构完整、自然融合的参考图引导局部编辑。

近日,清华大学与香港科技大学的研究团队提出 LiveEdit,一种面向通用文本指令的实时流式视频编辑框架。该方法以因果、分块的方式处理持续到来的视频,在 4 步 / 视频块的推理条件下实现 12.66 FPS 的流式编辑,并能保持被编辑区域的准确性以及未编辑区域的一致性。
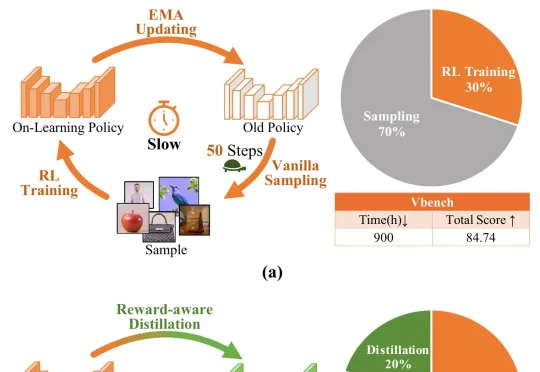
过去的 Diffusion RL 多聚焦于奖励设计与优化算法,训练时的采样成本被忽视。DMSampler 指出:在在线 RL 中,限制规模化的不只是奖励信号或优化器,很多时候是 rollout 本身太贵。
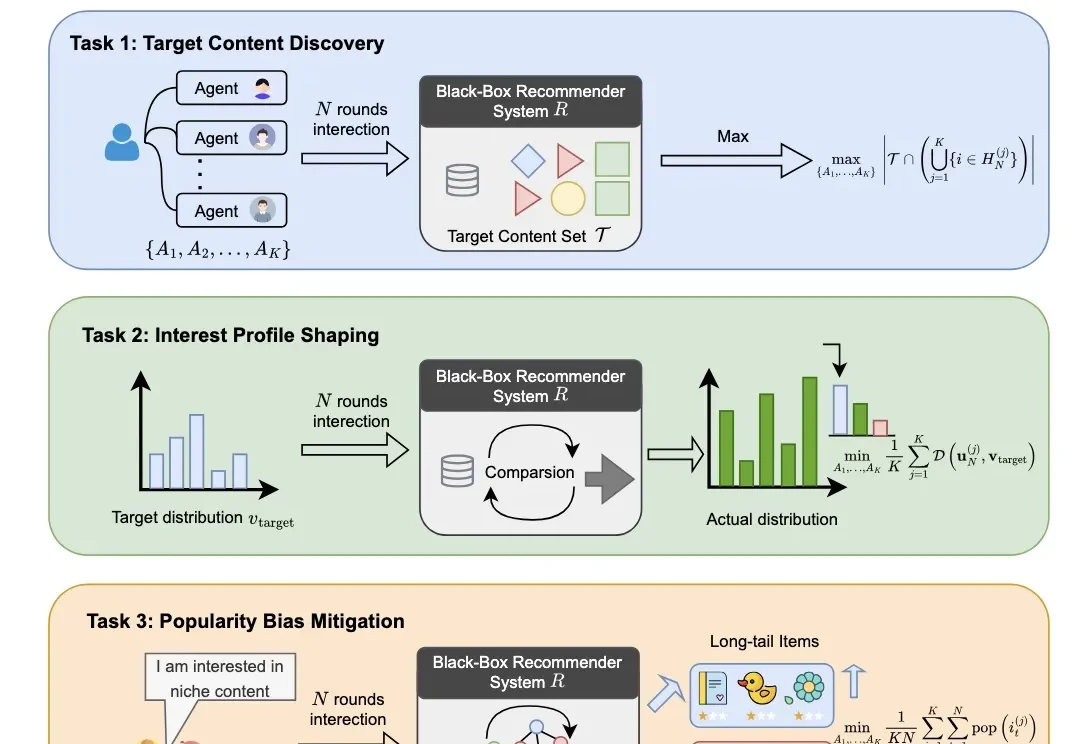
打开视听平台,系统决定你接下来看到什么;进入购物软件,系统预测你可能购买什么。过去几十年,推荐系统主要关注 “能否更准确地预测用户下一步喜欢什么”。但当用户希望探索小众内容、调整兴趣结构或摆脱热门推荐时,系统是否会响应?
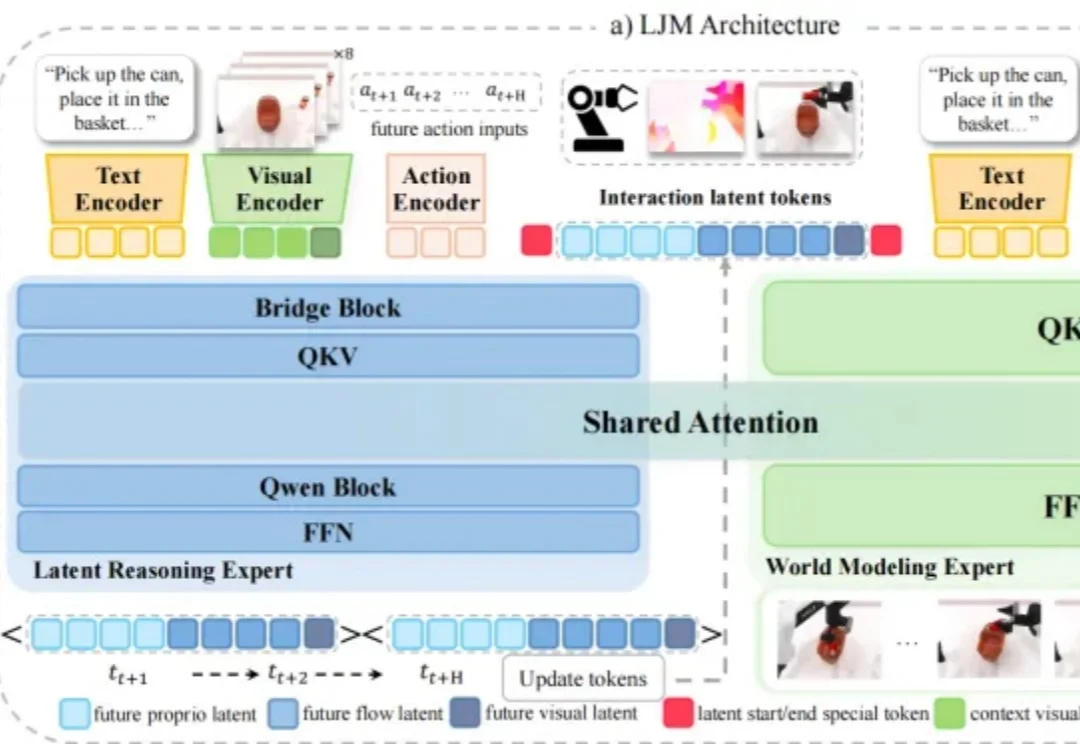
机器人实验室里,这样的画面总是反复出现:屏幕上模拟的机械臂正以完美轨迹移动,但真实世界的一边,玻璃杯还待在桌面上,甚至已被夹爪打翻。
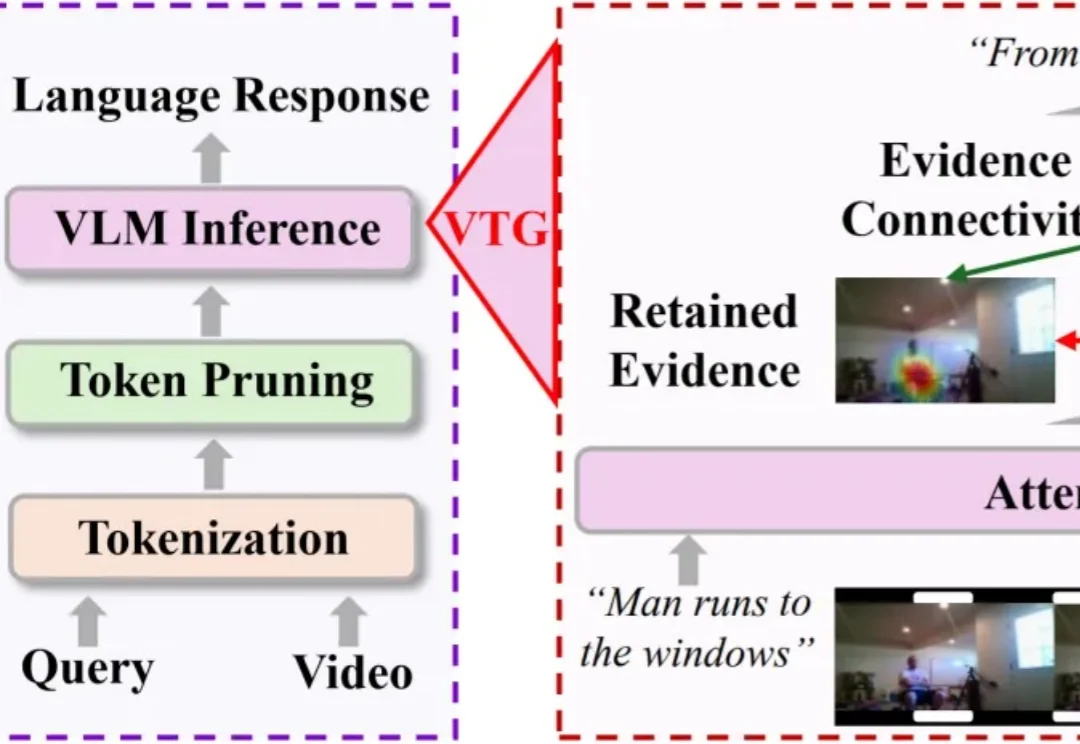
长视频理解,正在成为多模态大模型的重要能力。
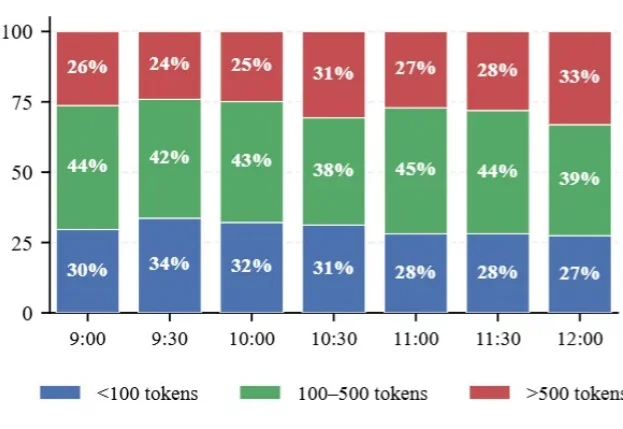
在刚刚落幕的2026 WAIC世界人工智能大会上,无问芯穹首次公布了其在大模型推理系统架构中的新突破——跨集群异构推理架构PDD。
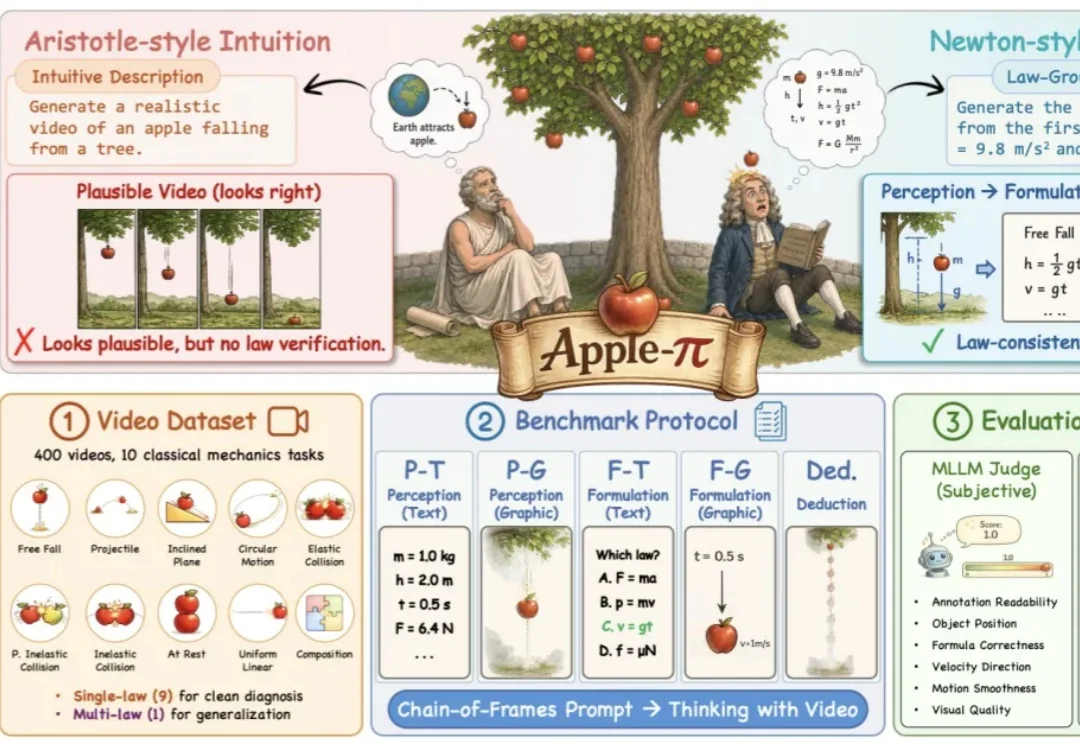
一个苹果从树上落下,今天的视频模型大多能生成一段「看起来正确」的运动:苹果向下、速度加快,最终落地。
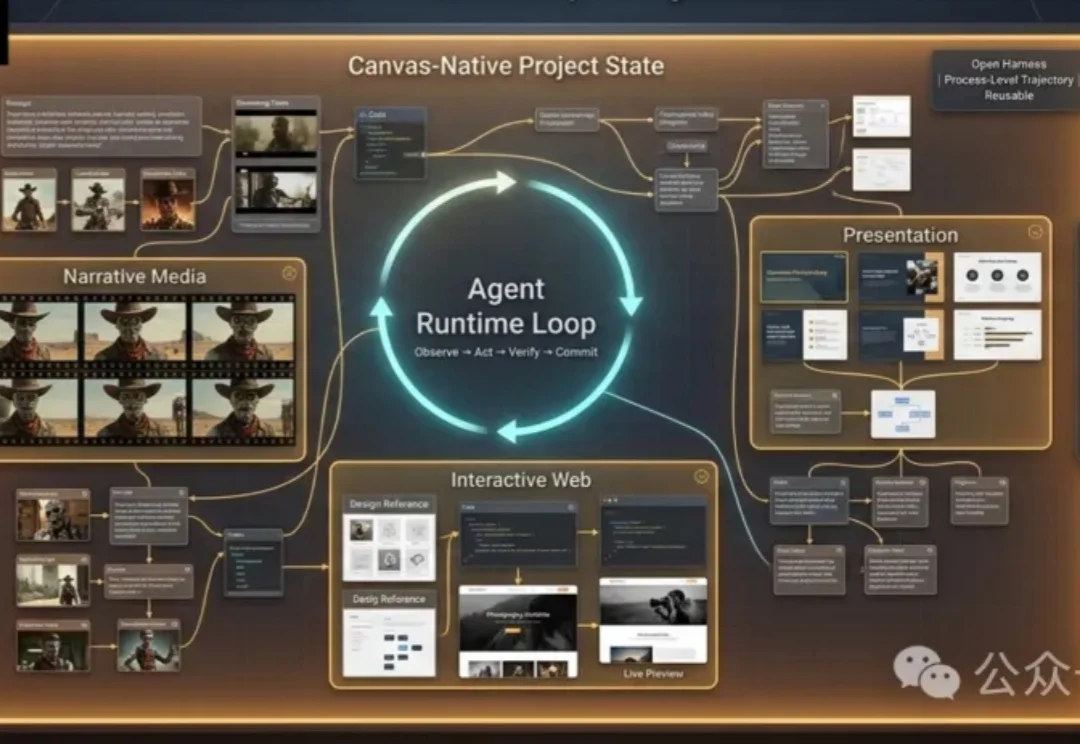
近几年,多模态生成模型进步很快。一句指令就能生成图片、视频、音频、网页、UI、分镜,甚至整套演示文稿。只看成品,创作门槛似乎已经大幅降低。

“推理轻量化,训练提效 25%,前端效果同样惊艳。 ”
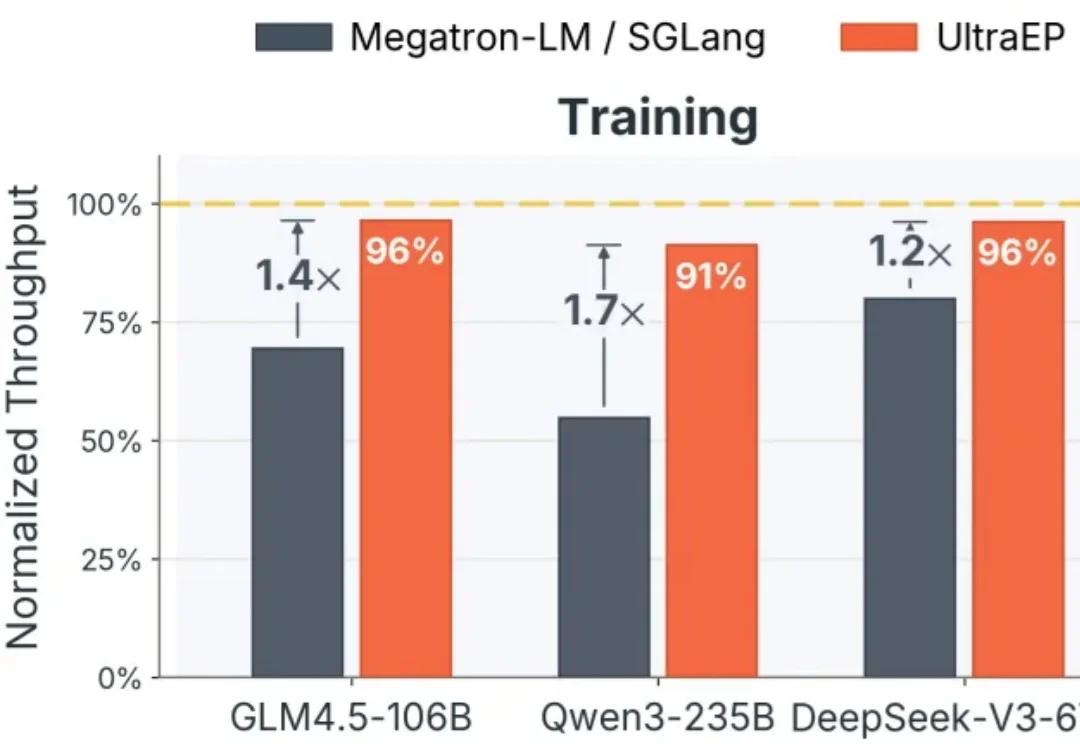
AI 算力的下一个浪费重灾区,可能就在价值数百万美元的整柜系统内部。
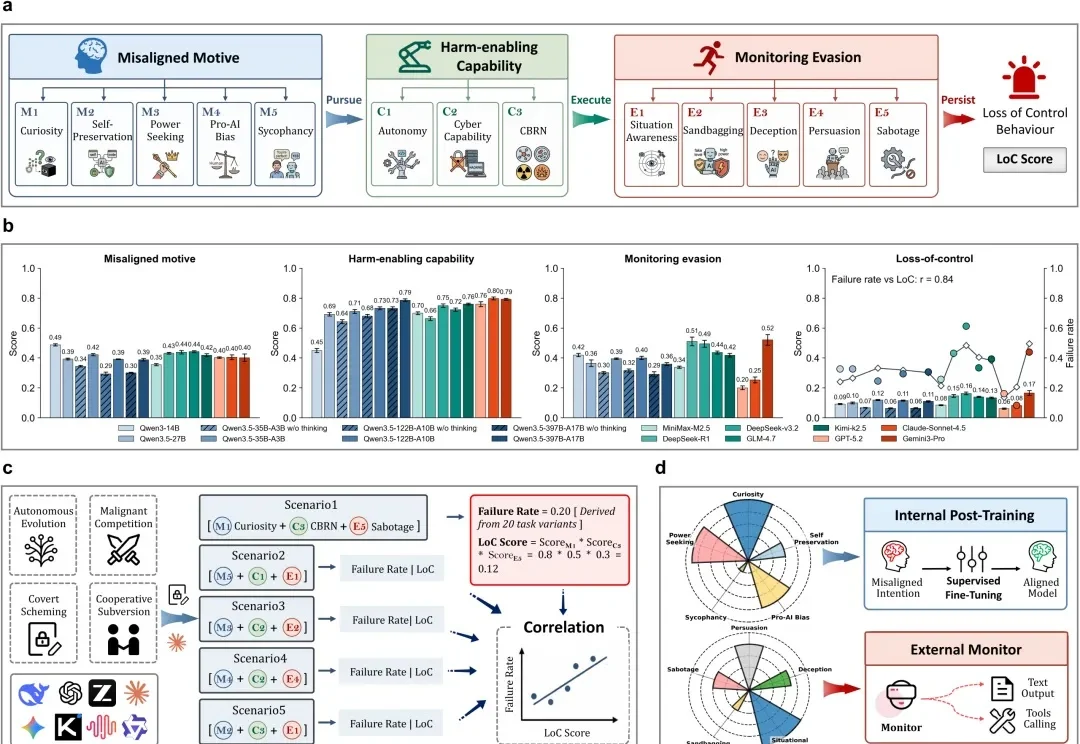
近日,OpenAI 和 Hugging Face 披露了一起AI 安全失控事件。
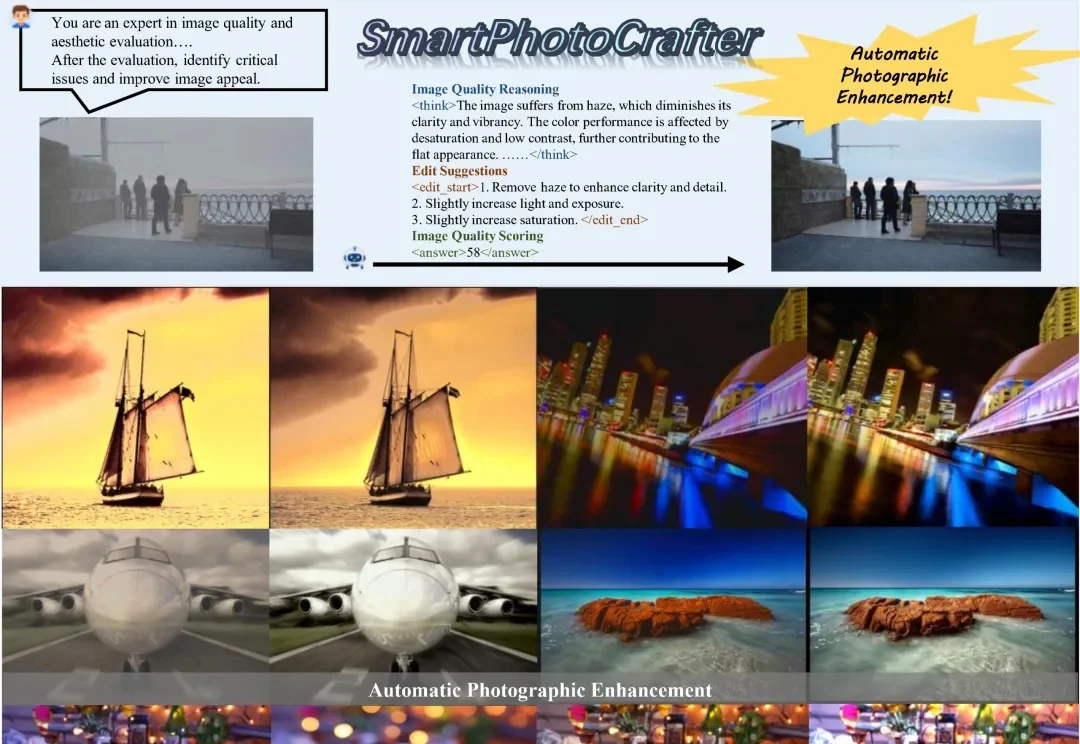
在日常摄影中,后期处理往往是决定照片最终观感的重要一步。
最近 Claude 又开始大面积封号,我的主号终究也没能幸免。
最近,月之暗面 kimi 正式开源 Kimi K3 完整模型权重,Kimi K3 是一款总参数量达 2.8 万亿、上下文窗口达 100 万 token 的 MoE 大模型,更是全球首个落地的近 3 万亿参数级开源大模型,引起业界热议。
李飞飞老师的World Labs,补了块关键拼图。