



2025年了,AI还看不懂时钟!90%人都能答对,顶尖AI全军覆没
2025年了,AI还看不懂时钟!90%人都能答对,顶尖AI全军覆没一般人准确率89.1%,AI最好只有13.3%。在新视觉基准ClockBench上,读模拟时钟这道「小学题」,把11个大模型难住了。为什么AI还是读不准表?是测试有问题还是AI真不行?
来自主题:
AI资讯
7772 点击 2025-09-09 17:24
一般人准确率89.1%,AI最好只有13.3%。在新视觉基准ClockBench上,读模拟时钟这道「小学题」,把11个大模型难住了。为什么AI还是读不准表?是测试有问题还是AI真不行?
几十G的大模型,怎么可能塞进一台手机?YouTube却做到了:在 Shorts 相机里,AI能实时「重绘」你的脸,让你一秒变身僵尸、卡通人物,甚至瞬间拥有水光肌,效果自然到分不清真假。

Meta超级智能实验室的首篇论文,来了—— 提出了一个名为REFRAG的高效解码框架,重新定义了RAG(检索增强生成),最高可将首字生成延迟(TTFT)加速30倍。

刚刚结束的OpenAI黑客松上,全球共有六支团队冲进榜单。他们探索了GPT-5在营销活动、时尚AI、电子表格、电脑代理、知识学习、智能电网等场景的应用极限。
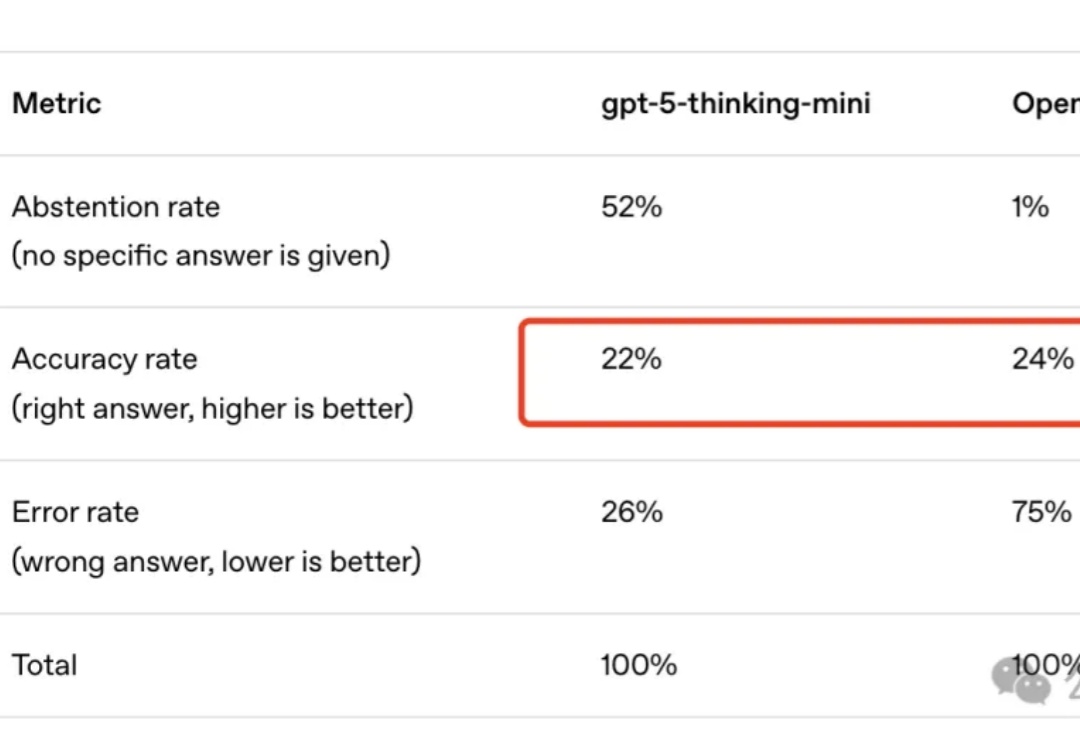
OpenAI好不容易发了篇新论文,还是给GPT-5挽尊?

很早之前,我们就拿到了 Bobby 的内测资格,第一次体验时,这个“24 小时在线的交易搭子”给我们留下了深刻印象。
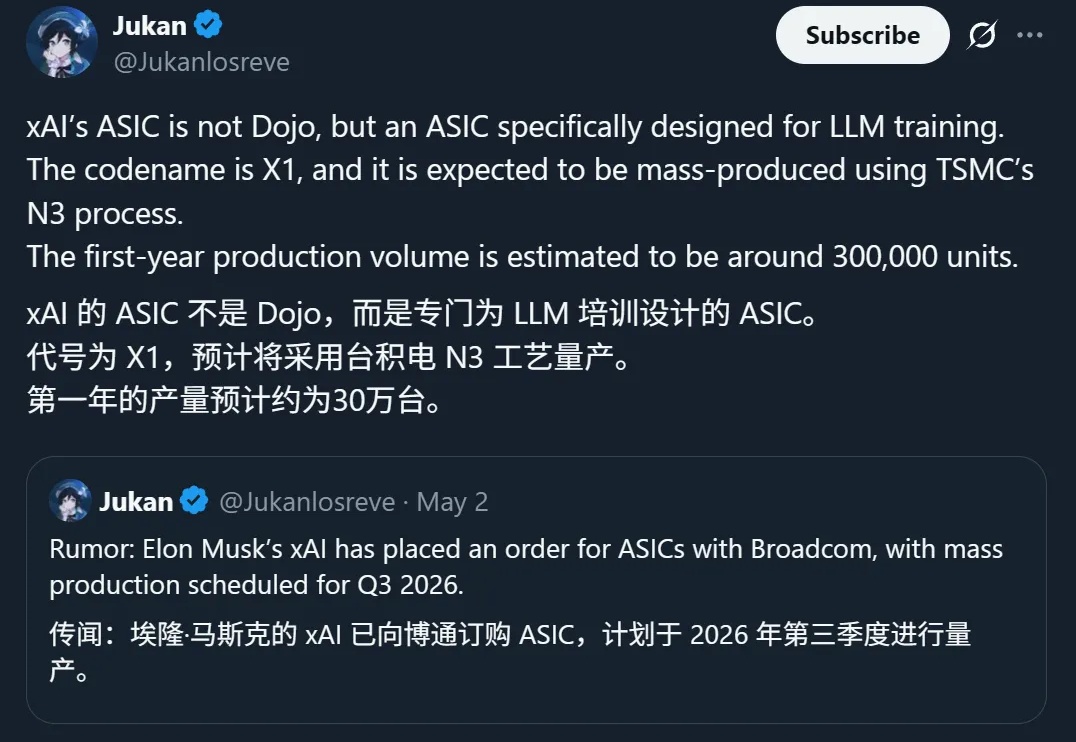
马斯克xAI被曝正在自研推理芯片!

打开多模态自由创作的大门。
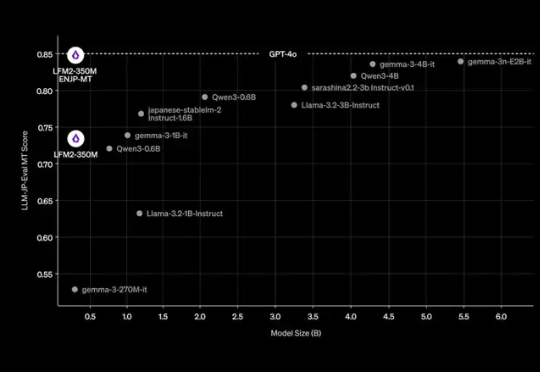
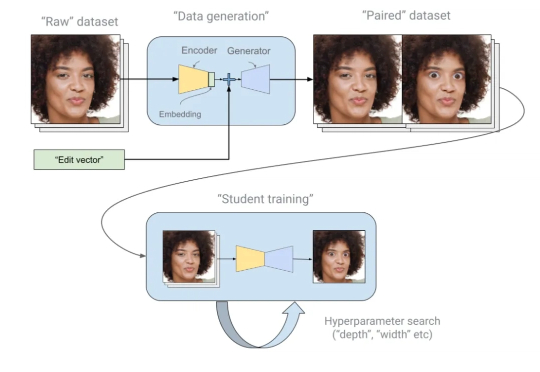
在大模型的竞赛中,参数规模往往被视为性能的决定性因素。但近期,Liquid AI 的研究团队提出了一个不同寻常的案例:一个仅有 3.5 亿参数的模型,经过微调后,竟能在中短上下文的实时日语英语翻译任务上,与 GPT-4o 竞争。

你能想象吗?一段 25 年前的 Linux 内核驱动,在现代系统上几乎不可能运行——但一位工程师用了两个晚上借助 AI 助手 Claude Code,让它重获新生。这个驱动曾经服务于老旧磁带设备,如今经过现代化改造,不仅可以在最新 Linux 上编译,还能与真实硬件顺利通信。可谓 AI 立大功!

OpenAI最近向股东们做了汇报,豪言将在未来五年烧1150亿美元,主要用于将自建的数据中心。与此同时,OpenAI也预测2030年营收将达到2000亿美元。OpenAI的信心因何如此充足?

英伟达也做深度研究智能体了。

9月4日,Decoding Bio发布《Projections at the Frontier: Snapshot 2025》,这份长达97页的报告,描绘了生物技术在未来五年的发展图景。

AI 数据行业,总有新人出头。

自从 Claude code 上线 sub-agents 后,我一直对其抱很大的期待,每次做 case 都会搭建一支“AI coding 梦之队”。想象中,它们会在主 agent的协调下火力全开, 完成我超级复杂的需求。

9 月 7 日,知情人士向路透社透露,先进芯片制造设备的重要供应商 ASML 将成为法国人工智能初创公司 Mistral AI 的最大股东,此举旨在加强欧洲的科技主权。

你有没有经历过这样的场景:公司高层突然宣布"我们现在是AI优先的公司",然后看着你说"去组建一个AI团队吧",但预算和人员编制却纹丝不动?如果你点头了,那你绝对不是一个人。从Shopify到Duolingo,再到Zapier,似乎每家科技公司都在宣布自己转型为"AI优先",仿佛这是一张通往未来的船票。但现实往往更加残酷:你被赋予了AI转型的重任,却没有额外的资源去实现它。

过去几年,大语言模型(LLM)的训练大多依赖于基于人类或数据偏好的强化学习(Preference-based Reinforcement Fine-tuning, PBRFT):输入提示、输出文本、获得一个偏好分数。这一范式催生了 GPT-4、Llama-3 等成功的早期大模型,但局限也日益明显:缺乏长期规划、环境交互与持续学习能力。

今天吃到一个科技圈的瓜,主角是 77 岁的 AI 教父 Geoffrey Hinton,诺贝尔奖图灵奖得主。
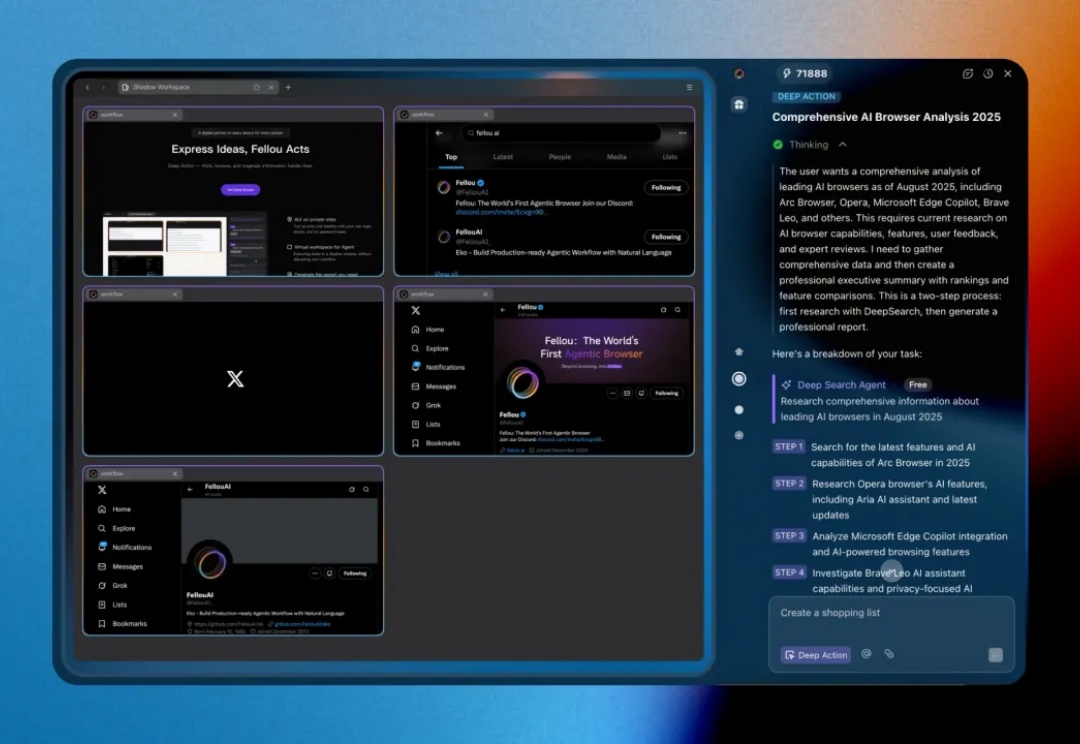
背景信息:Fellou 又发新版了

SpikingBrain借鉴大脑信息处理机制,具有线性/近线性复杂度,在超长序列上具有显著速度优势,在GPU上1M长度下TTFT 速度相比主流大模型提升26.5x, 4M长度下保守估计速度提升超过100x;
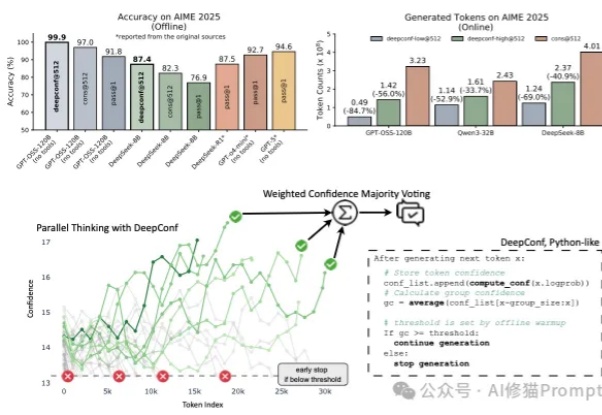
在大型语言模型(LLM)进行数学题、逻辑推理等复杂任务时,一个非常流行且有效的方法叫做 “自洽性”(Self-Consistency),通常也被称为“平行思考”。

刚刚,据华尔街日报报道,OpenAI 正在为一部名为《Critterz》的动画长片提供工具和算力支持,预计将在明年 5 月的戛纳电影节上首映。《Critterz》讲的是一群森林小生物在陌生人打扰村庄后踏上冒险的故事。OpenAI 的创意专家 Chad Nelson 三年前在尝试用刚推出的 DALL-E 图像生成工具制作短片时
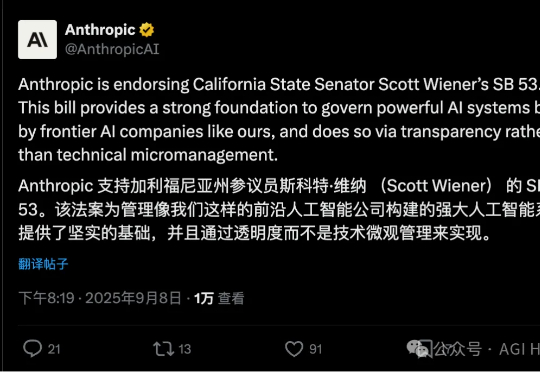
继封禁中国公司后,Anthropic 刚刚宣布:支持SB 53 法案。继上周封禁中国公司 API 访问后,这家 AI 公司表示,该法案为监管前沿 AI 公司构建的强大 AI 系统提供了坚实基础,通过透明度而非技术微观管理来实现监管。

OpenAI又要成立新团队了!
继π0后,具身智能基座模型在中国也终于迎来了真正的开源—— 刚刚,WALL-OSS宣布正式开源!在多项指标中,它还超越了π0。如果你是搞具身的开发者,了解它的基本资料,你就一定不会想错过它:
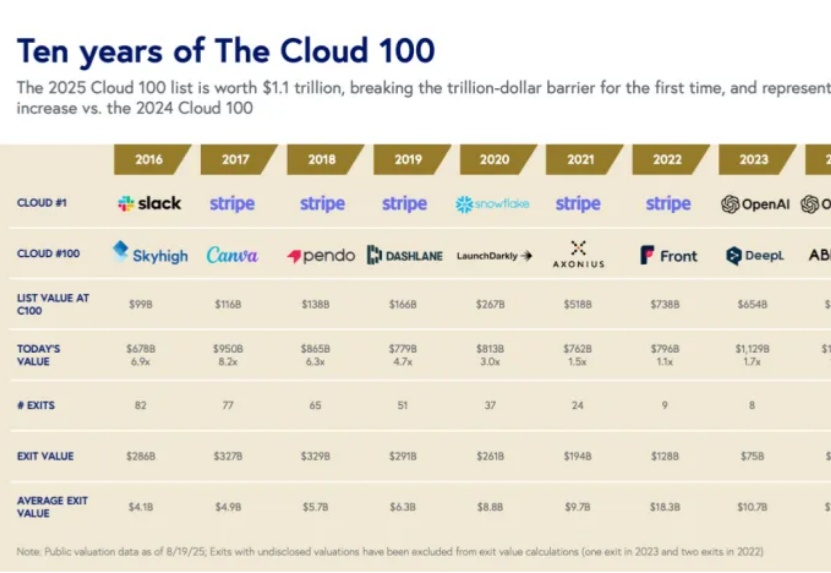
BVP最新报告中,AI原生企业成为最大驱动力,22家AI公司合计贡献4640亿美元市值,占比42%,较2024年翻倍。这份报告不仅揭示了AI如何重塑云计算版图,还为投资人和创始人提供了关于估值趋势、增长速度、IPO窗口和人才军备竞赛的第一手洞察。

如果把当下最让人迷惑的科技产品拉个清单,AI 硬件网红们绝对榜上有名。 从 699 美元的 Humane Ai Pin 到 200 美元的 Rabbit R1,这些 AI 创业公司都在兜售同一个美丽的谎言:你需要专门的硬件才能体验真正的 AI。 今天,这个名单上又多了一个新成员——AI Key。

好玩好用的明星视频生成产品再更新,用户操作基础,模型技术就不基础。

经历了前段时间的鸡飞狗跳,扎克伯格的投资似乎终于初见成效。

