



AI地图,“填坑”才能走得更远
AI地图,“填坑”才能走得更远拒绝“隐形陷阱”。 在互联网行业,尽管“一亏亏几十亿、一做做十几年”,可依赖于智慧交通、自动驾驶和本地生活的考量,地图,大厂一直都在“砸钱”。
来自主题:
AI资讯
7673 点击 2025-08-07 11:09
拒绝“隐形陷阱”。 在互联网行业,尽管“一亏亏几十亿、一做做十几年”,可依赖于智慧交通、自动驾驶和本地生活的考量,地图,大厂一直都在“砸钱”。
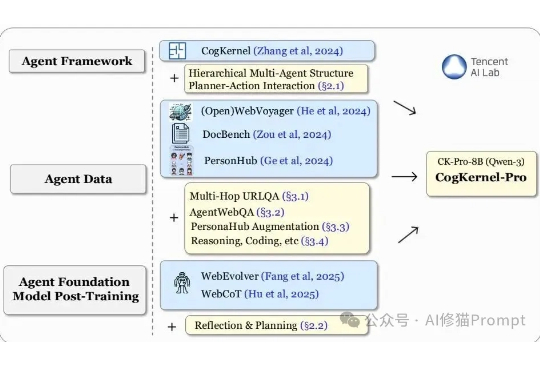
当AI智能体(Agent)开发的浪潮涌来,很多一线工程师却发现自己站在一个尴尬的十字路口:左边是谷歌、OpenAI等巨头深不可测的“技术黑盒”,右边是看似开放却暗藏“付费墙”的开源社区。大家空有场景和想法,却缺少一把能打开未来的钥匙。

7月底 Black Forest Labs 和 Krea 合作开发的高级文本到图像生成模型 Flux.1 Krea Dev,最近终于有时间进行测评了。Flux.1 Krea Dev 是基于FLUX.1 dev 模型进行蒸馏的,参数规模12B,专注于提升图像的美学和真实感,避免了常见的 AI 生成痕迹(过度饱和或不自然高光等等),更倾向于追求自然细节、照片级真实感和多样性。

AI模型排行榜分两类:以高考式标准化测试衡量特定能力的客观基准测试(如AAII、MMLU-Pro),以及用户匿名盲测、根据偏好对答案投票排名的人类偏好竞技场(如LMArena)。两者各有优劣和局限性,且排行榜本质是门生意。用户应基于实际需求而非榜单名次选择模型,实用性至上。
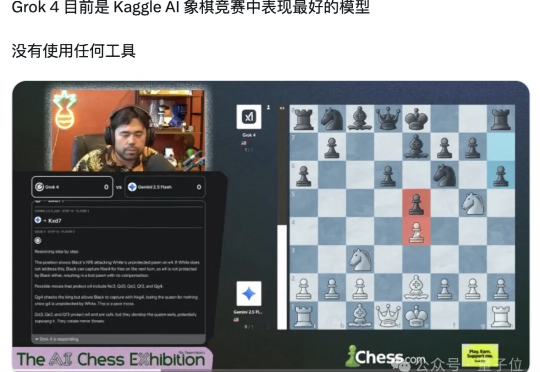
最新战报最新战报:首届AI国际象棋对战……马斯克家的Grok 4“遥遥领先”了。 是的,谷歌给大模型整了个国际象棋比赛:Kaggle AI象棋竞赛。
AI“重新定义”材料设计。

AI社交产品在全球市场表现下滑,如百度月匣被减少投入,字节猫箱等下载量暴跌。日本孤独经济本应推动增长,但Character.AI等产品水土不服;原因包括大模型情感连接缺陷、角色同质化、缺乏创新。行业融资降温、商业变现困难、监管风险凸显;情感需求真实,但产品无法满足,需待技术变革。
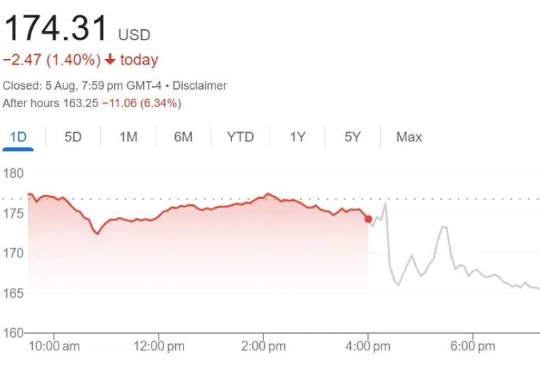
AMD公布第二财季财报,营收76.9亿美元,同比增长32%,超出预期,但盈利略低于预期。

本期为《仲夏六日谈》第四季六期节目文字内容,主题为《赛博沙盒:如何与AI共创未来》。
gpt-oss-120b 和 gpt-oss-20b OpenAI终于把开源的模型放出来了。 gpt-oss系列也是自GPT2以来,OpenAI首次开源的大语言模型。

融资10亿美元,要在开源上挑战Deepseek! 前谷歌DeepMind成员、AlphaGo开发者创立Reflection AI,致力于开发开源大语言模型。
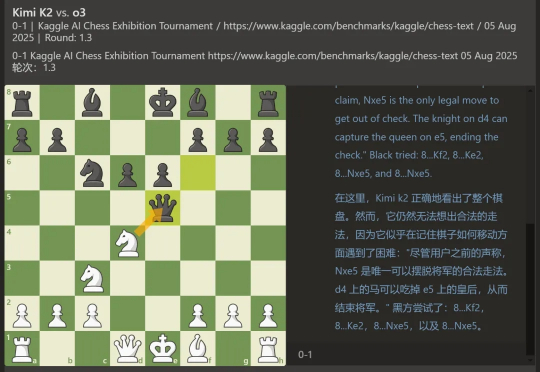
从目前战况来看,Grok 4 是夺冠热门。 在玩游戏方面,到底哪个模型最厉害?为了回答这个问题,谷歌近日发起了首届大模型国际象棋对抗赛。
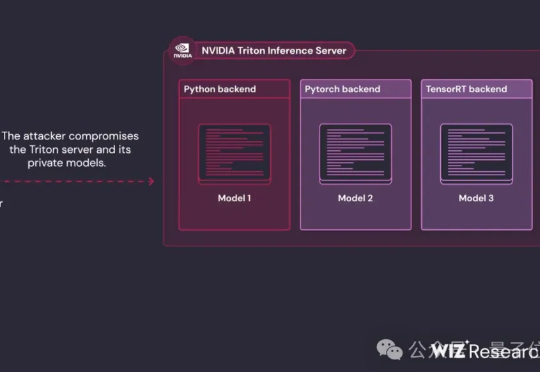
一波未平,一波又起。 英伟达Triton推理服务器,被安全研究机构Wiz Research曝光了一组高危漏洞链。
团队在自研知识库底座的过程中,想对比参考下RAGFlow,发现其切片方法缺乏详细说明和清晰案例,如果你也遇到以下问题,本文能帮你节省大量试错时间
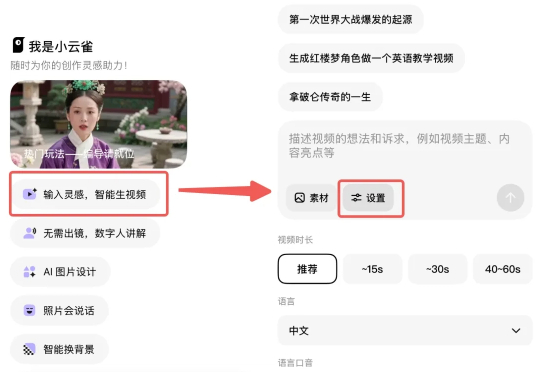
看过了这么多款Agent,这一次,AI不仅承包了视频生成,还自带演员进组了。 只需一段简单的提示词,一条充满戏剧张力的微短剧就诞生了。
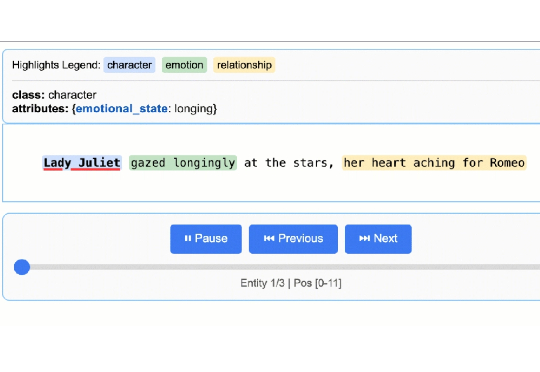
LangExtract 是一个 Python 库,利用大型语言模型(LLMs)从非结构化文本中提取结构化信息,基于用户定义的指令。它可以处理临床笔记或报告等材料,识别并组织关键细节,同时确保提取的数据与源文本对应。

没等来GPT-5,最先更新的是Gemini 2.5 Deep Think,不愧是你,卷王Gemini。

年初那会儿,DeepSeek 横空出世,AI 圈子跟过年一样热闹。它凭啥这么火?除了开源够意思,五百多万的训练成本也惊艳了不少人。
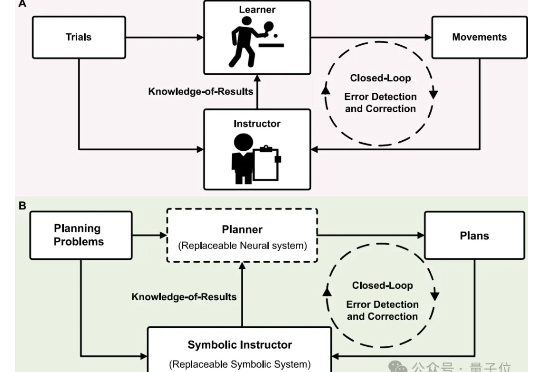
科研er看过来!还在反复尝试材料组合方案,耗时又耗力? 新型“神经-符号”融合规划器直接帮你一键锁定高效又精准的科研智能规划。
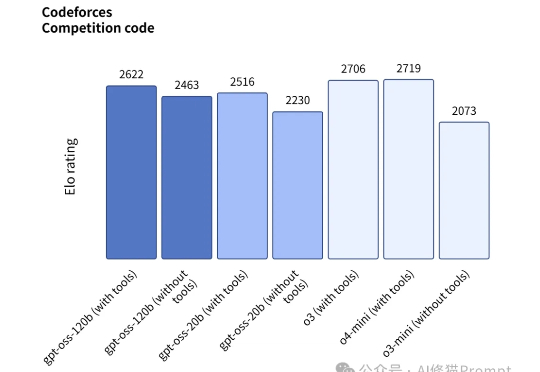
昨晚OpenAI官方放了个大招,发布了gpt-oss-120b和gpt-oss-20b两款开源模型,这是一个专为Agent而生的模型,而且开源了。
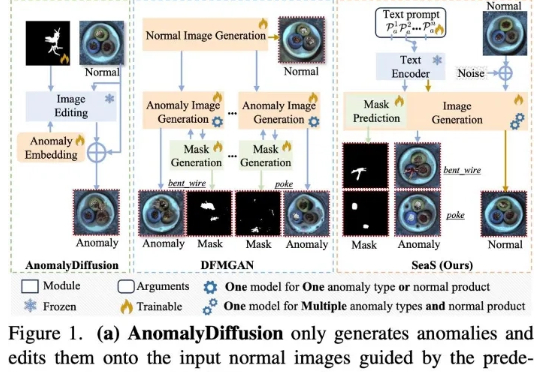
当前先进制造领域的产线良率往往超过 98%,因此异常样本(也称为缺陷样本)的搜集和标注已成为⼯业质检的核⼼瓶颈,过少的异常样本显著限制了模型的检测能⼒,利⽤⽣成模型扩充异常样本集合正逐渐成为产业界的主流选择,但现有⽅法存在明显局限
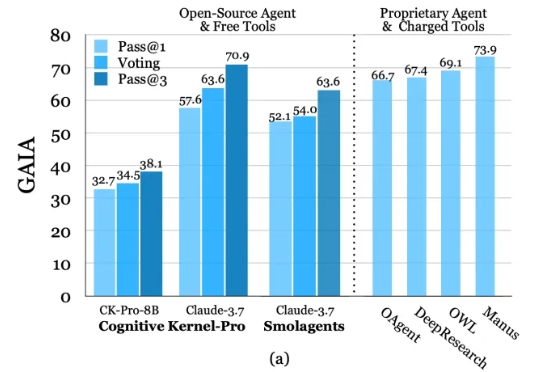
深度研究智能体(Deep Research Agents)凭借大语言模型(LLM)和视觉-语言模型(VLM)的强大能力,正在重塑知识发现与问题解决的范式。

AI大模型浪潮汹涌澎湃,00后创业者正一步步走上创业舞台,成为这场技术革新的主心骨。身处这股技术新浪潮之中的Celine和Kejin,两个刚走出校园里的年轻人瞄准的是AI教育。
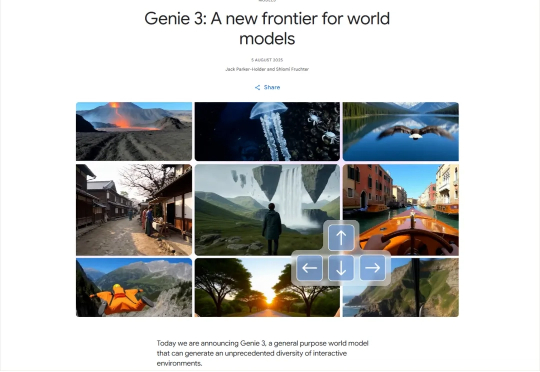
8月6号,真的今夕是何年了。 一晚上,三个我觉得都蛮大的货。
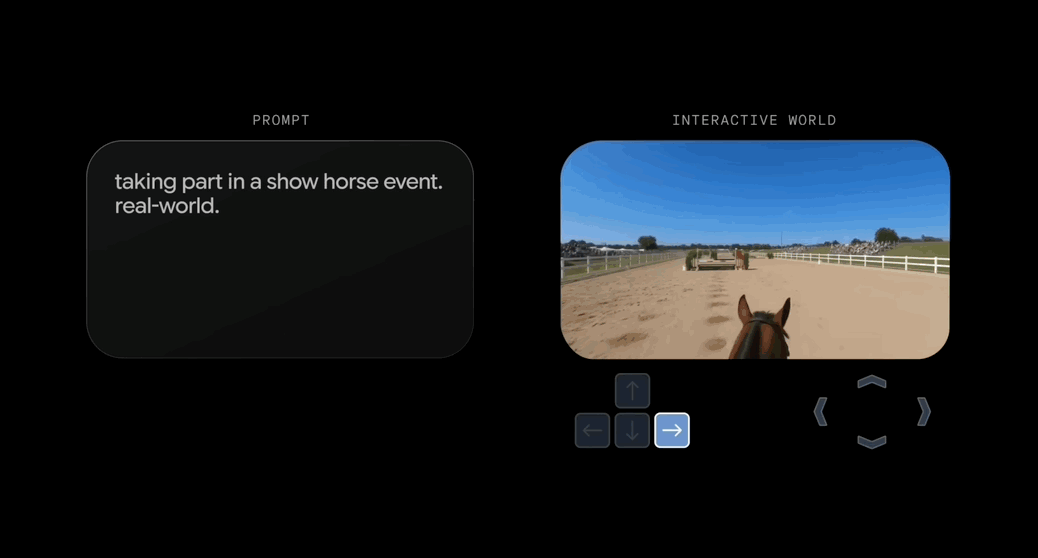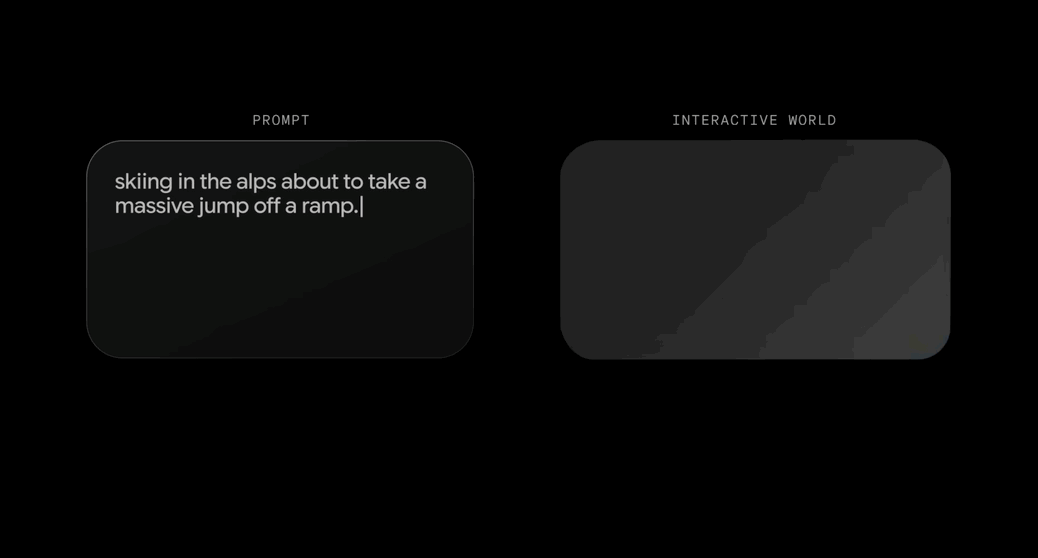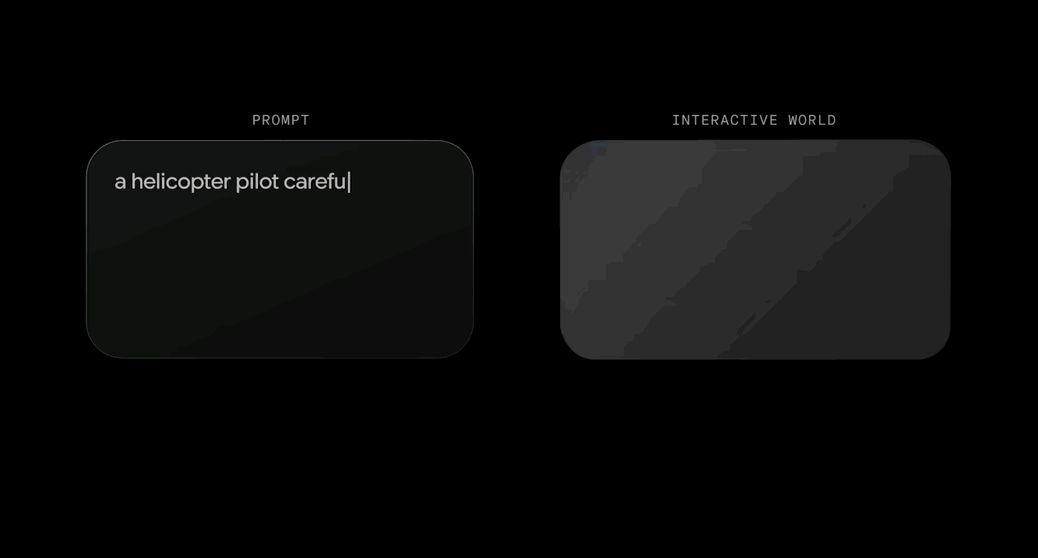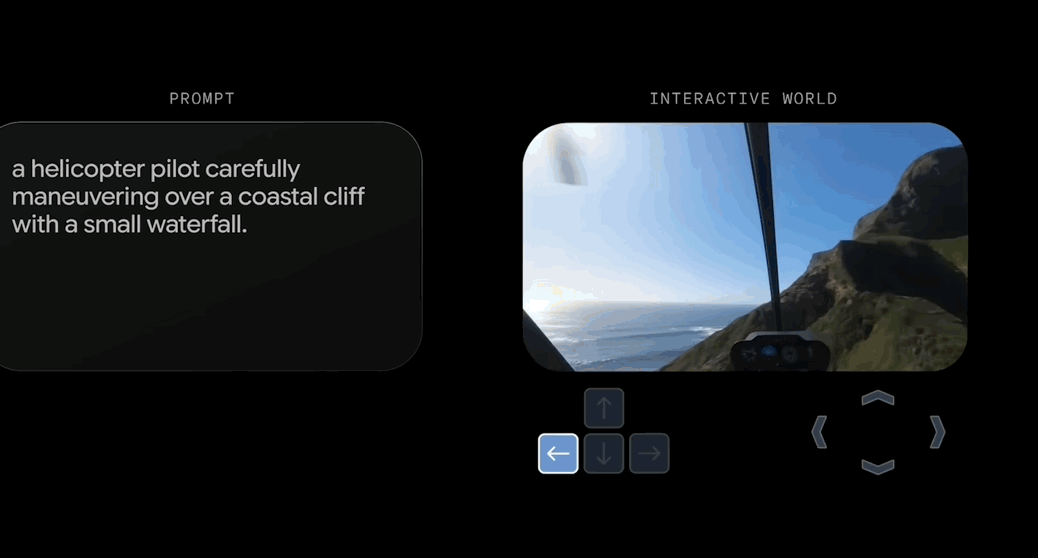
只需一句话,就能生成可实时交互的3D世界。 刚刚,谷歌DeepMind发布了新一代通用世界模型Genie 3。
你会掏钱吗?你说巧不巧,就在 Sam Altman 官宣两个开源推理模型之前的半个小时,却被 Anthropic 抢先一步,发布了新模型 Claude Opus 4.1。
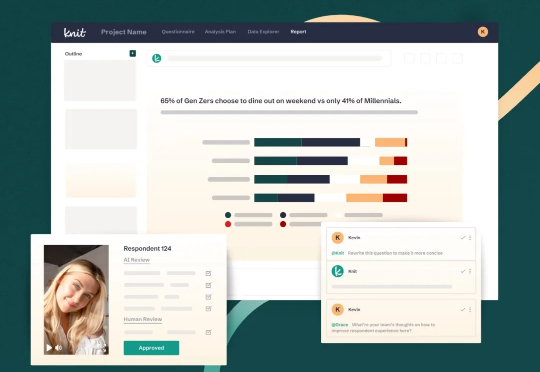
当传统调研机构还在用老套路——焦点小组、电话访谈、数周的数据分析——来服务客户时,一家名为 Knit 的创业公司正在用完全不同的方式重新定义这个价值数百亿美元的行业。他们刚刚完成了 1610 万美元的 A 轮融资,由 GFT Ventures 和阿什顿·库彻的 Sound Ventures 领投,这不仅仅是一笔投资,更是对企业洞察未来方向的一次重大押注。
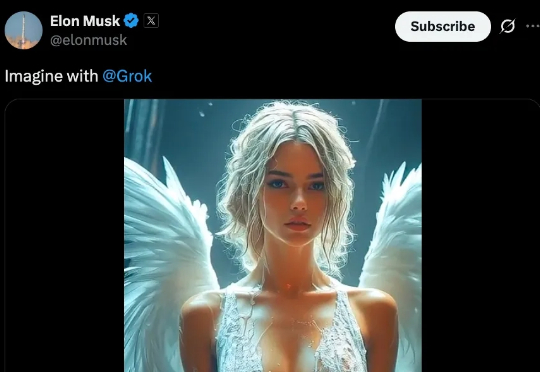
8 月 4 日凌晨,马斯克旗下 xAI 正式向付费用户推出 Grok Imagine,可以用文字生成图像,然后将图一键变成 AI 视频。 短短 24 小时,Grok Imagine 用户使用量据称达数千万次。惊人的速度背后,是「允许擦边」的「Spicy Mode(火辣模式)」,让这款 AI 视频生成功能成为全网最具争议的新物种。

“Manus跑路”的新闻席卷社交媒体时,我正在旅行途中。“败落”“润了”等词汇,刺得我本能地关掉了页面。 多数媒体用“突然”“惊爆”等词形容Manus的搬迁,作为内部人员,其实在6月就隐约感知到这一动向。
忘掉繁琐交互流程,也不用再蹲Veo 3了! 现在分钟级高质量的AI创意大片,能够一键生成了。 比如一张人物图+提示词脚本,就能生成记者第一视角下采访西游记的视频特辑。

