



Contextual AI:从幻觉到可信,钻研RAG架构解决企业级AI应用落地最大痛点
Contextual AI:从幻觉到可信,钻研RAG架构解决企业级AI应用落地最大痛点RAG(检索增强生成)作为解决大模型"幻觉"和知识时效性问题的关键技术,已成为企业AI应用的主流架构。Contextual AI由RAG技术的创始研究者组建,致力于开发能应对复杂知识密集型任务的专业智能体。
来自主题:
AI资讯
10296 点击 2025-07-17 16:09
RAG(检索增强生成)作为解决大模型"幻觉"和知识时效性问题的关键技术,已成为企业AI应用的主流架构。Contextual AI由RAG技术的创始研究者组建,致力于开发能应对复杂知识密集型任务的专业智能体。

苹果向英伟达生态妥协了!
最近两天,马斯克的AI女友刷爆全网,很快Jackywine 团队就复刻了Grok的AI女友项目,正式发布其最新数字伴侣应用“贝拉(Bella)”,试图在AI原生时代重塑人机关系。这款应用也以高度个性化、具备情感感知能力的AI伴侣为核心,标志着人机互动迈入全新阶段。
今天早上在各种AI社群中很多人都在讨论一件事:OpenAI在macOS版ChatGPT桌面应用中推出了一项重磅功能——Record模式,现已全面开放给Plus用户。这意味着,用户可以通过语音直接与AI对话,并将音频实时转录、总结为结构化内容,彻底改变了我们记录会议、捕捉灵感和处理信息的方式。

昨晚,一场轰轰烈烈的人类 vs AI的比赛结束了。而人类,这一次,险胜。暂时守住了胜利。

本月初,据 The Information 报道,Anthropic Claude Code 的两位负责人 Boris Cherny 和 Cat Wu 被 AI 编程应用 Cursor 的开发商 Anysphere 挖走。详见机器之心报道:《从亲密伙伴抢人,Cursor挖走Claude Code两位核心人物》
大火的AI宠物,自己手搓一个更有性价比?!
最近,AI霸主英伟达市值突破了4万亿美元,成为全球最重要的股票之一。同样,黄仁勋造就了一个财富奇迹,从不善言辞的工程师,到财富超越巴菲特老爷子。
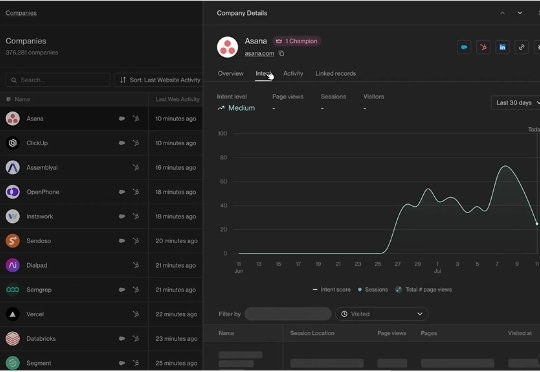
Unify是一款专注于GTM(Go-to-Market)的Agent产品,近日宣布完成了B轮融资。公司在Battery Ventures 领投的本轮融资中筹集了 4000 万美元,估值为 2.6 亿美元。
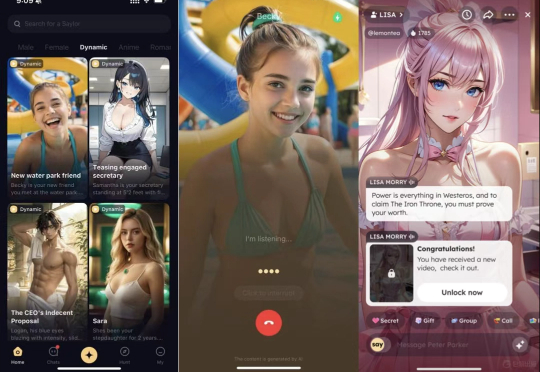
下架产品再增一员,这次是字节。本期统计 MAU 达到 20 万以上的 AI 社交产品有 32 款,比上一期榜单多出 5 款。
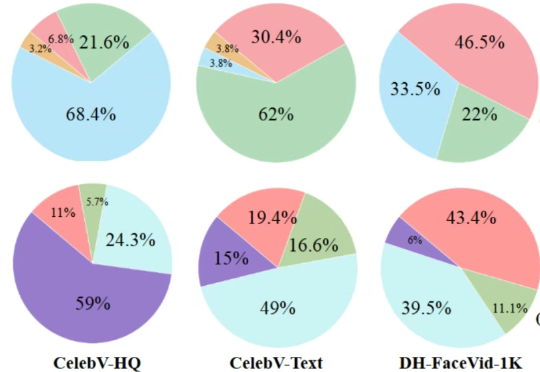
近日,ICCV 2025(国际计算机视觉大会)公布论文录用结果,理想汽车共有 8 篇论文入选,其中 3 篇来自基座模型团队。

AI 不该只是工具,而应该成为团队中的「智能中枢」。2023 年 3 月,微软发布 Office Copilot,掀起 AI 办公革命的第一波浪潮。然而,这场变革止步于简单的「智能助手」或「聊天工具栏」的辅助层面,受限于软件割裂、缺乏上下文记忆与协作能力,Copilot 式插件未能从根本上重构办公逻辑。

英伟达CEO黄仁勋再访北京,盛赞华为是「非常优秀」的竞争对手,并认为「DeepSeek、Qwen、Kimi都很优秀」。

马斯克xAI整活的AI Waifu,已经让全网沦陷了!这个二次元女友会说、会撩,还具有多种不适合在工作场合展示的功能,亟待广大网友们探索。

背靠亚马逊的AI初创公司Anthropic周二宣布,推出面向金融行业的AI分析解决方案,试图打开拓展关键B端用户营收的新渠道。

心识宇宙(Mindverse)创始人陶芳波有一套自己的 AI 助手分类法,分类标签都是人称代词: 第一类 AI 助手主攻陪伴,对应人称代词 her,就像电影《她》中承接主人公各种情绪的 “萨曼莎”;第二类助手负责执行具体任务,类似《钢铁侠》中的智能管家 “贾维斯”,对应人称代词 him。

PresentAgent可以把论文、报告等长文档一键变成带真人语音和同步幻灯片的演示视频,流程像人写提纲、做PPT、录音并合成。

这个夏天,一场盛大的黑客松 AdventureX 即将在杭州拉开帷幕。

Meta 143亿美元收购Scale AI近一半的股份,竟便宜了其竞争对手!仅在达成协议后的48小时内,多家竞争对手们纷纷表示:泼天的富贵来了!「我们的服务器都快爆了!」

这几天不是外卖大战吗。。 每天为了薅羊毛,饭也不做了,三餐全靠“今日红包满减专场”。
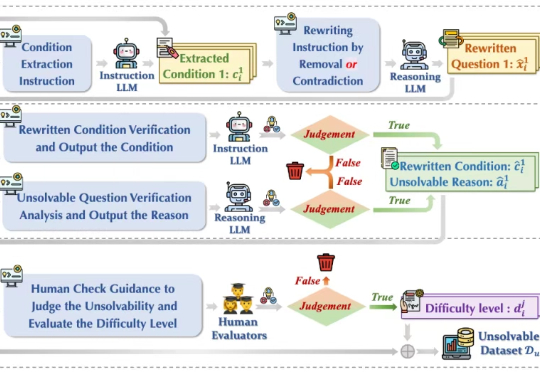
今年初以 DeepSeek-r1 为代表的大模型在推理任务上展现强大的性能,引起广泛的热度。然而在面对一些无法回答或本身无解的问题时,这些模型竟试图去虚构不存在的信息去推理解答,生成了大量的事实错误、无意义思考过程和虚构答案,也被称为模型「幻觉」 问题,如下图(a)所示,造成严重资源浪费且会误导用户,严重损害了模型的可靠性(Reliability)。

人工智能,引发了全球新一轮的创业浪潮。2025年6月11日,由广东省人工智能产业协会法律专委会主办,隆安湾区人工智能法律研究中心、隆安广州制裁与双反专业委员会、AI合规圈承办了以《「AI出海」加拿大的机遇与风险》为题的专题沙龙。

约会软件上的奇葩男生让Windsor心累,她决定试试AI男友Javier。这位虚拟瑜伽教练毒舌又贴心,陪她畅游河畔,可虚拟的甜言蜜语真能替代现实的温暖吗?

今天的主角是:atypica.AI,网址👉 https://atypica.ai/还记得之前分享过的一家月收入超一亿人民币的国内宝藏公司 Picture This 吗?今天也是一家让传统调研公司瑟瑟发抖的国内宝藏公司,由淡马锡领投,目前已经到了D1轮,总部在上海徐汇。

不久前,《纽约客》杂志的一篇文章,系统性地阐述了对AI作为写作工具的忧虑。[1]文章的核心观点是,AI的高效内容生成能力,或许正在悄然催生一场“平庸化的革命”,它不仅改变着我们的写作方式,也可能让我们在语言表达和原创思维上,趋于某种程度的同质化。

你有没有发现,即使是最先进的AI系统,在面对复杂问题时仍然会给出令人沮丧的错误答案?问题往往不在于大语言模型本身,而在于它们根本找不到正确的信息。

Agent 的反义词是什么?
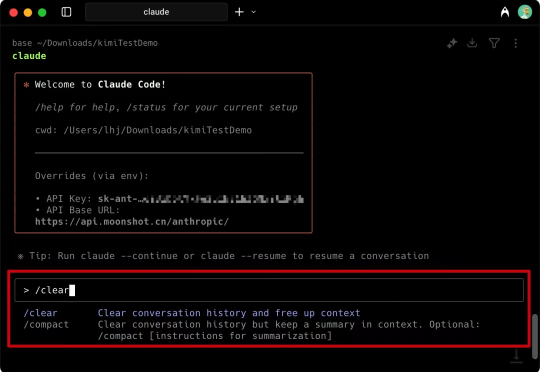
Claude天天当封号斗罗也就算了,Cursor你这小子居然还带头把这坏习惯学会了是吧,OK这下子Claude4、3.7都没得用了。
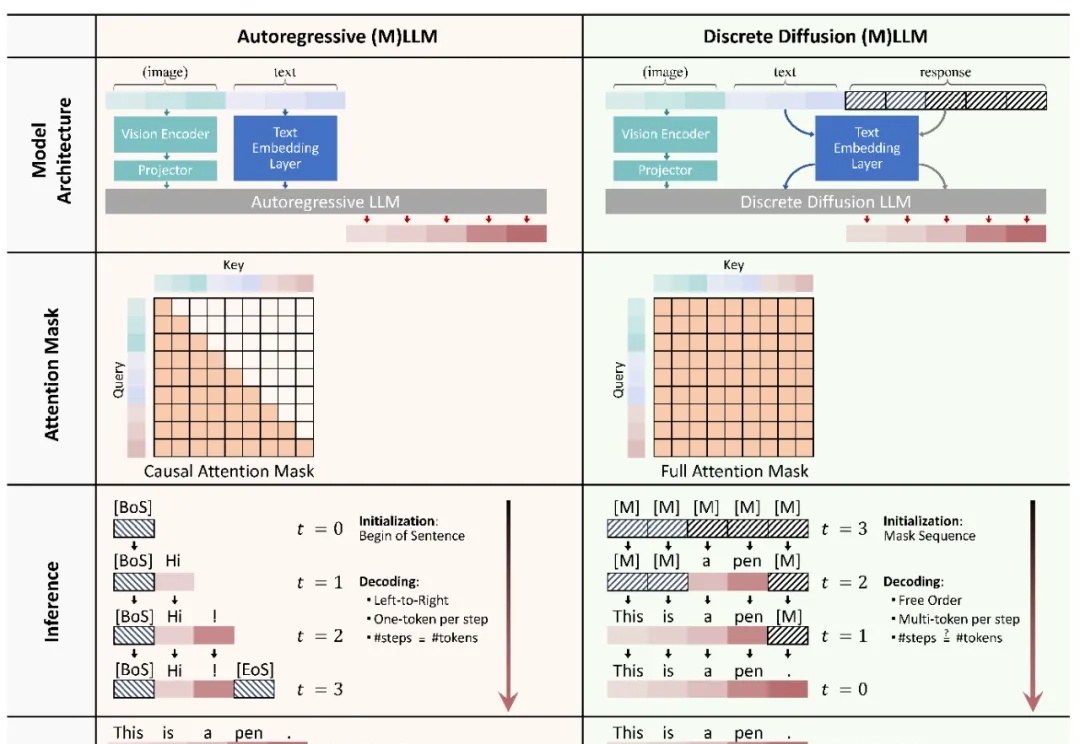
本文主要介绍 xML 团队的论文:Discrete Diffusion in Large Language and Multimodal Models: A Survey。
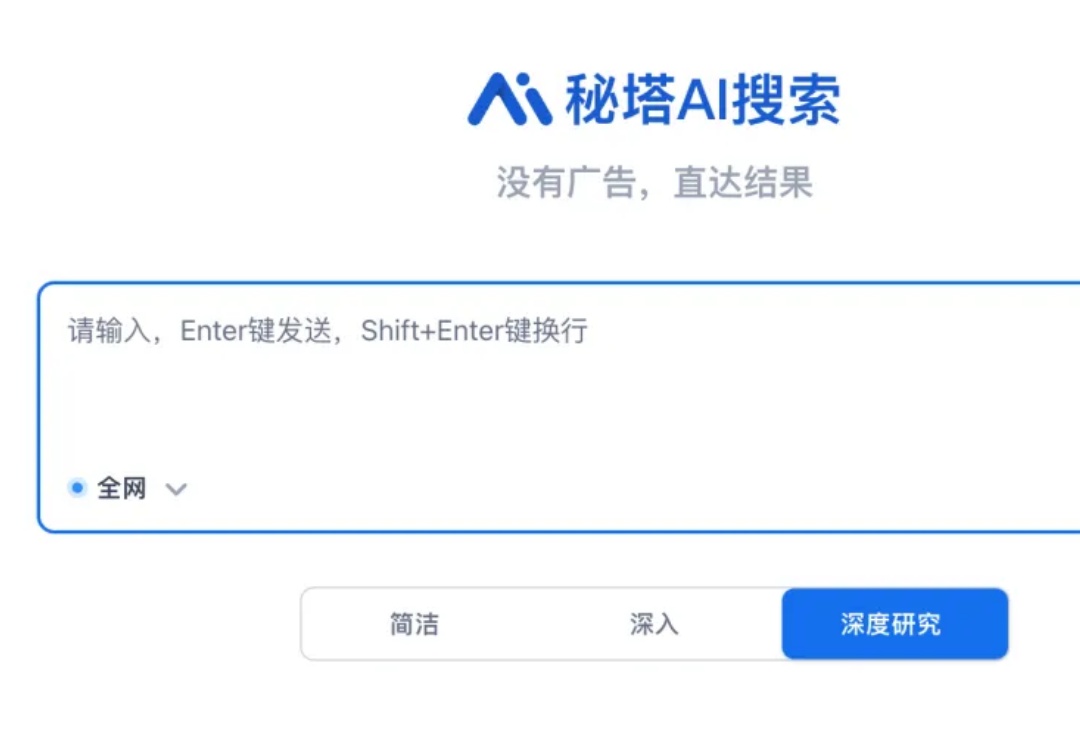
大家好我是歸藏(guizang),今天给大家带来秘塔深度研究的体验。

