



字节芯片,隐秘布局 | 智能涌现独家
字节芯片,隐秘布局 | 智能涌现独家随着豆包大模型和seedance视频生成模型等业务的爆发,自研芯片成功后,字节有望大大降低其算力成本。
来自主题:
AI资讯
8084 点击 2026-02-13 12:12
随着豆包大模型和seedance视频生成模型等业务的爆发,自研芯片成功后,字节有望大大降低其算力成本。
从此以后,AI 不再是工具,要尊称为「硅基博学家」了。

年化经常性收入已达699亿

谁能想到,2026 年第一个爆火出圈的 AI 互动装置,居然出现在米兰冬奥村?
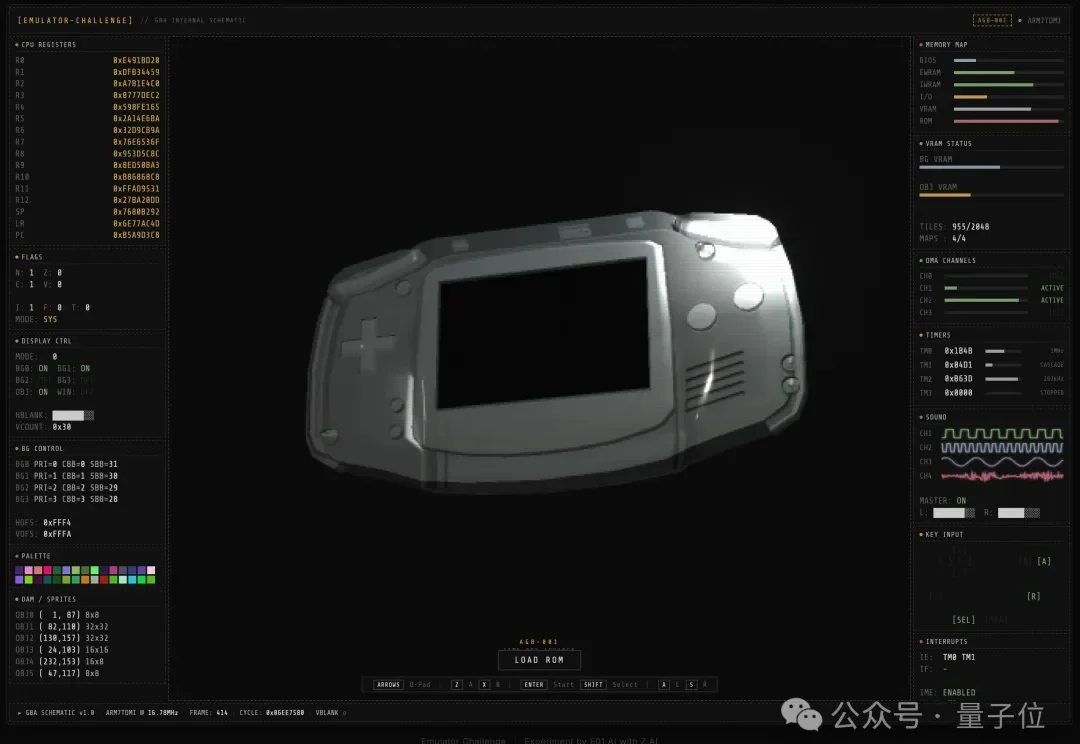
当看到GLM-5正式发布后的能力,才惊觉前几天神秘模型Pony Alpha的热度还是有点保守了。
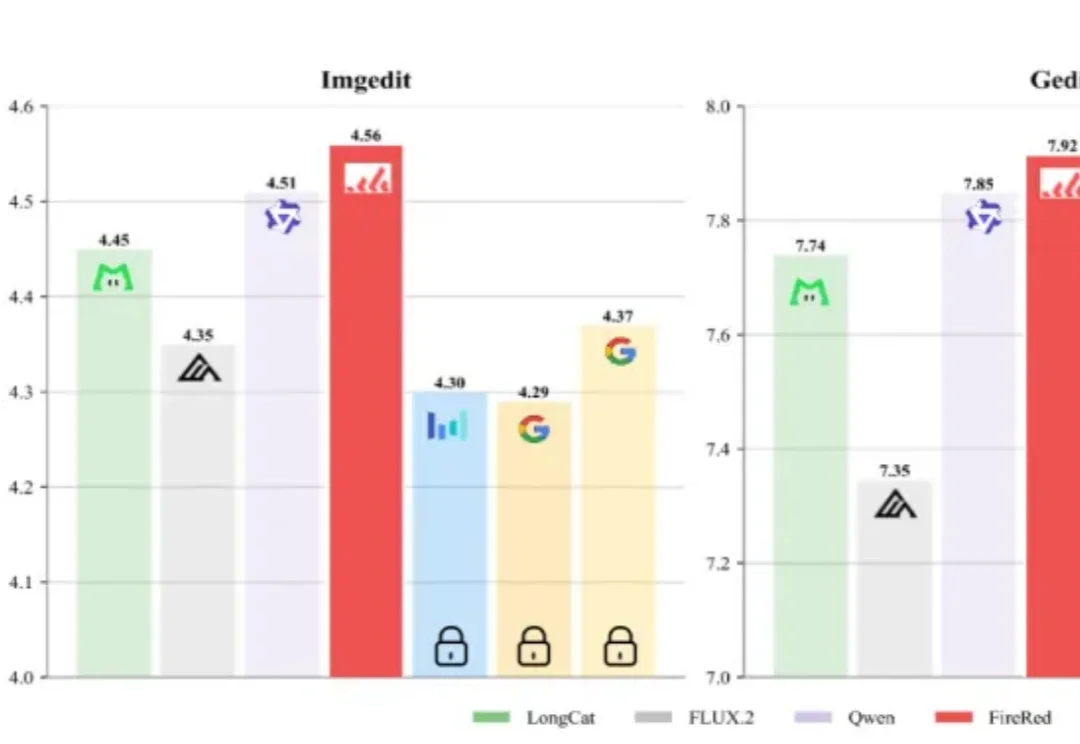
AI生图领域,又出了个“狠角色”。

一句话做“黄金矿工”游戏、生成精美公司网站。
过去几年,大模型把自然语言处理彻底重塑了。GPT 出来之前,NLP 领域的状态是:每个任务一套模型,每个场景一批数据,每个公司一条流水线,互不通用,边界清晰。GPT 之后,这套逻辑被一个预训练底座 + 任务微调的范式整个替换掉了。

就是说,这几天还有哪档晚会节目是没有机器人现身的吗?

美国正在重建那些真正支撑国家实力的经济领域。能源、制造、物流和基础设施再次成为了焦点。
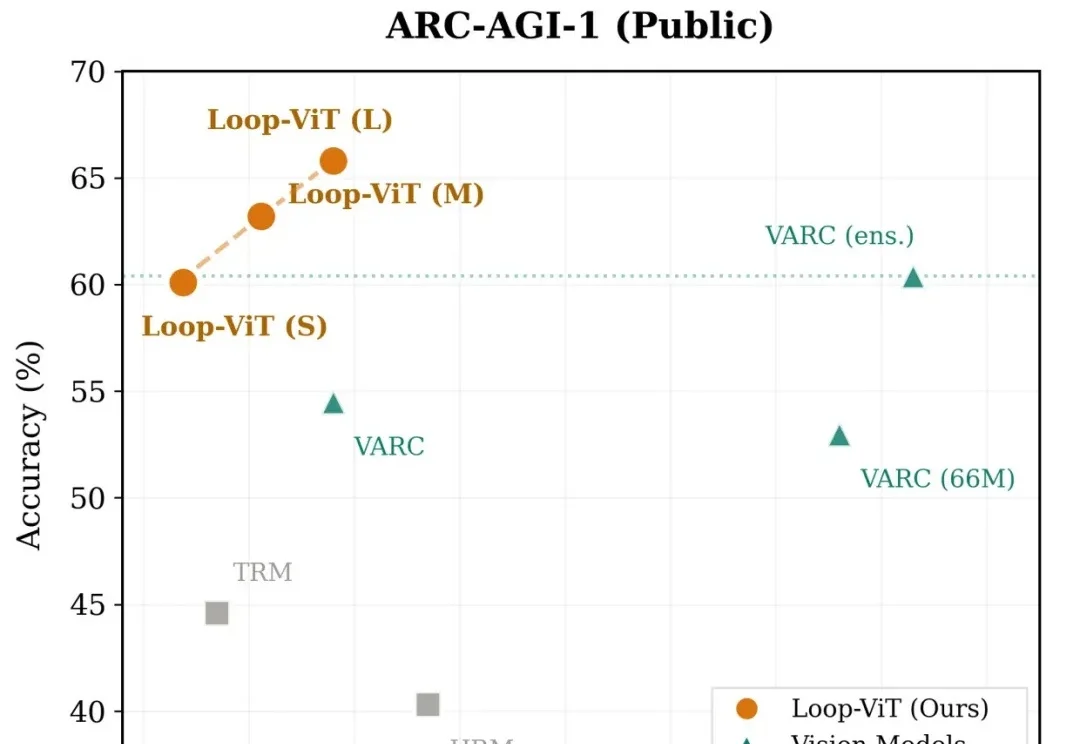
当我们解一道复杂的数学题或观察一幅抽象图案时,大脑往往需要反复思考、逐步推演。然而,当前主流的深度学习模型却走的是「一次通过」的路线——输入数据,经过固定层数的网络,直接输出答案。

TwinRL用手机扫一遍场景构建数字孪生,让机器人先在数字孪生里大胆探索、精准试错,再回到真机20分钟跑满全桌面100%成功率——比现有方法快30%,人类干预减少一半以上。
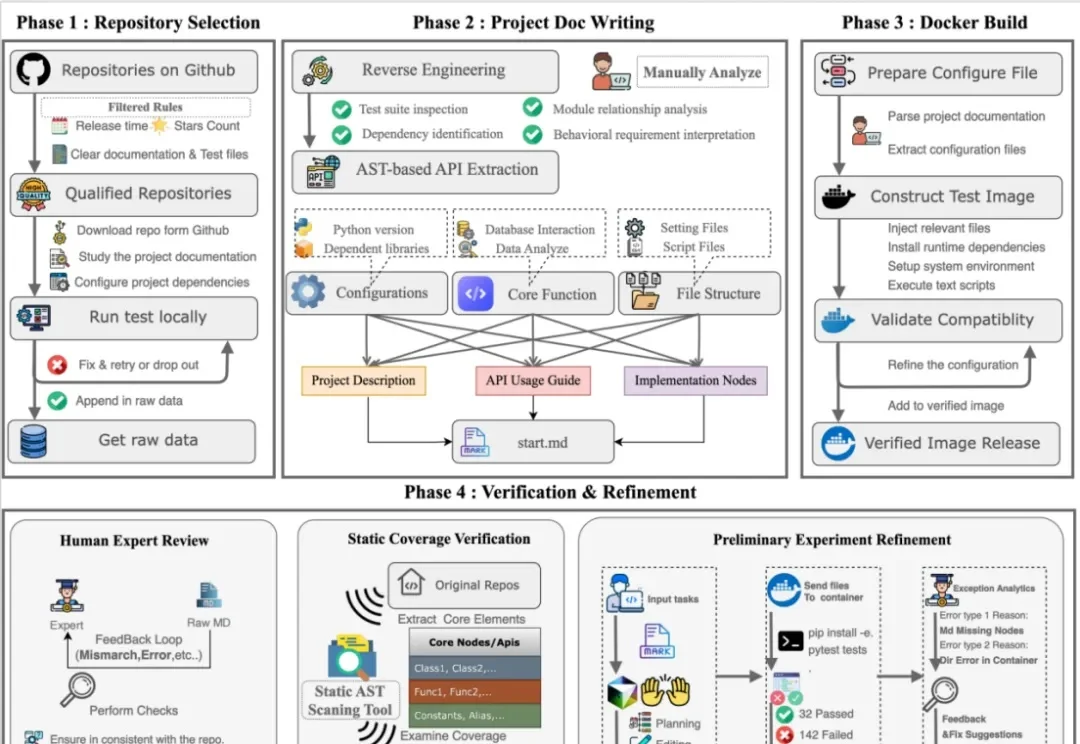
在 AI 编程领域,大家似乎正处于一个认知错觉的顶点:随着 Coding Agents 独立完成任务的难度和范围逐渐增加,Coding 领域的 AGI 似乎就可以实现?

爆红社交平台、登顶全球评测,中国AI视频模型集体破圈。

就在本月,AI 经历了质变式飞跃,已经能独立完成过去需要人类专家数小时才能搞定的复杂工作。AI 开始参与构建下一代 AI,递归自我提升的循环已经启动,智能爆炸可能在一两年内到来。

DiscoX构建了一套200题的长文翻译数据集,以平均长度1,712 tokens的长篇章做评测单元,要求整个长文文本作为一个整体来翻译,除翻译准确度外,重点考察跨段落的逻辑与风格一致性、上下文中的术语精确性、以及专业写作规范,贴合用户真实的使用场景。
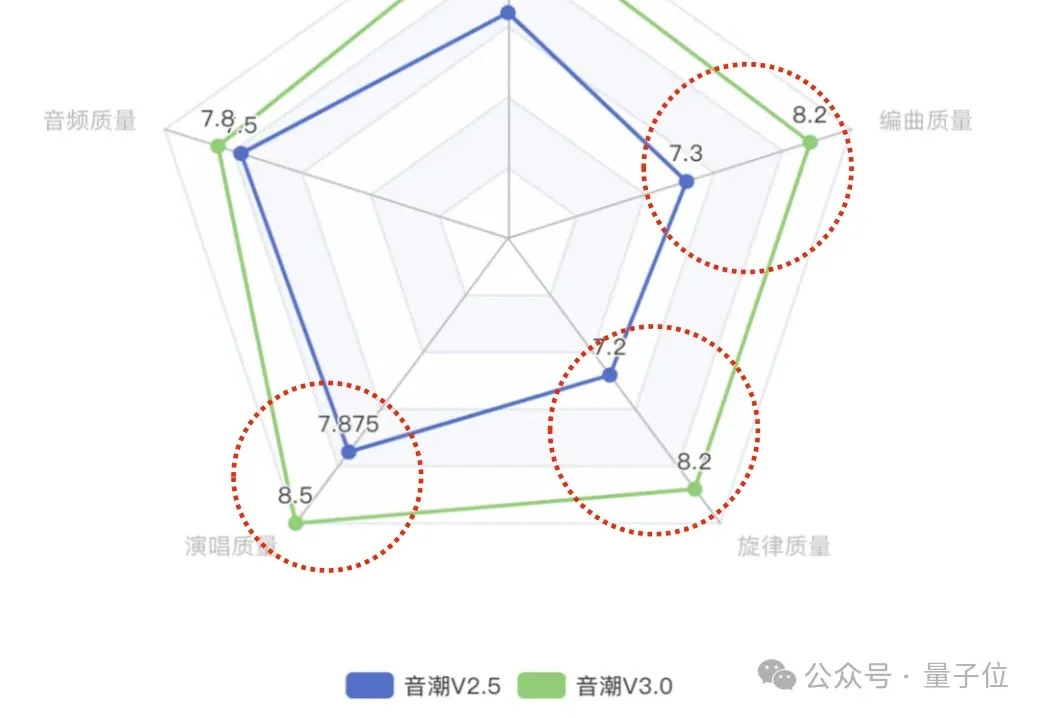
AI又在某个方面悄悄超越我了——这次是五音比我全!

今天,Gemini 3 Deep Think重磅升级,几乎刷爆全领域的SOTA,标志着AI推理能力进入了全新维度。这一次,在科学研究和硬核工程领域,Deep Think堪称一个「最强大脑」。
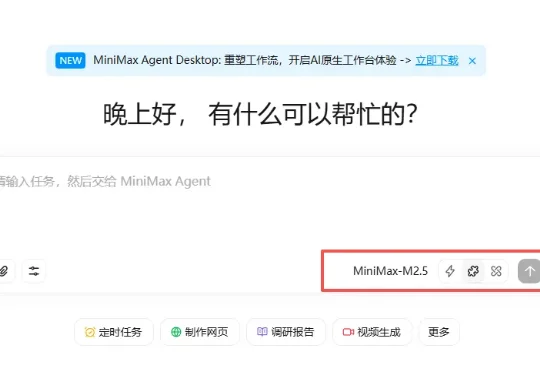
这两天 AI 圈真的太热闹了,就在网传 DeepSeek 要更新支持 100 万 Token 上下文的新模型时,MiniMax 率先冲锋,更新了他们的新旗舰模型:MiniMax-M2.5。更有意思的是,国外网友这段时间对国内 AI 大模型的更新节奏格外关注,他们甚至把这种争先更新的现象称为:Happy Chinese new year!
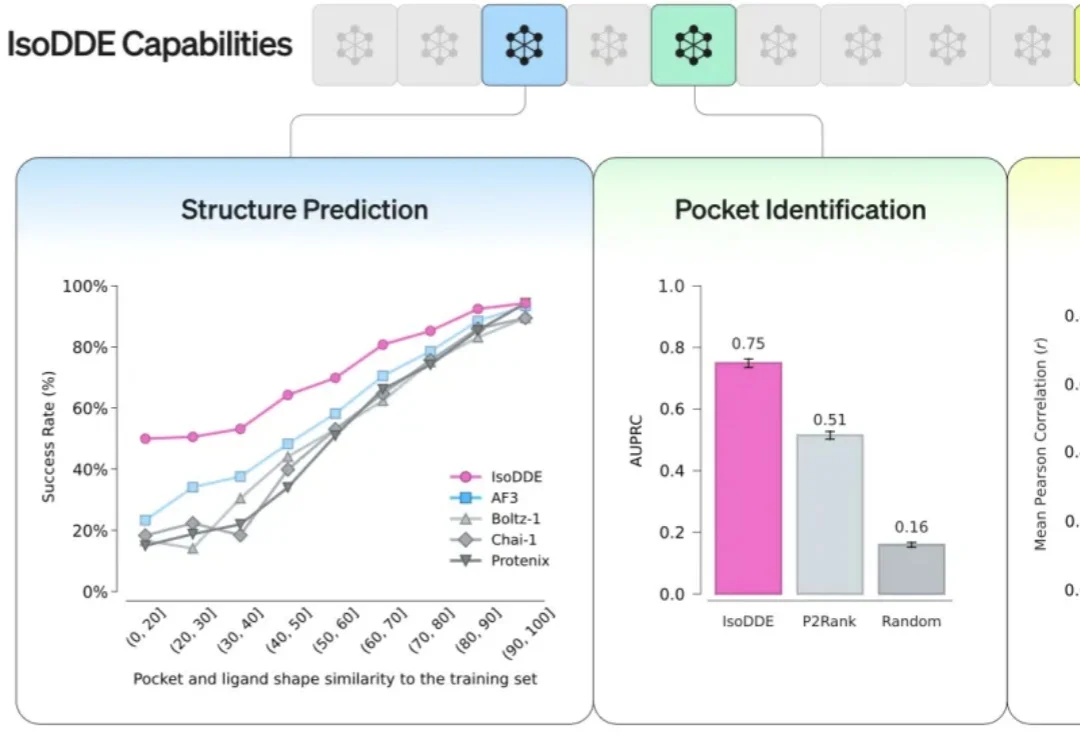
谷歌DeepMind和Isomorphic Labs合作,祭出了药物设计之王。
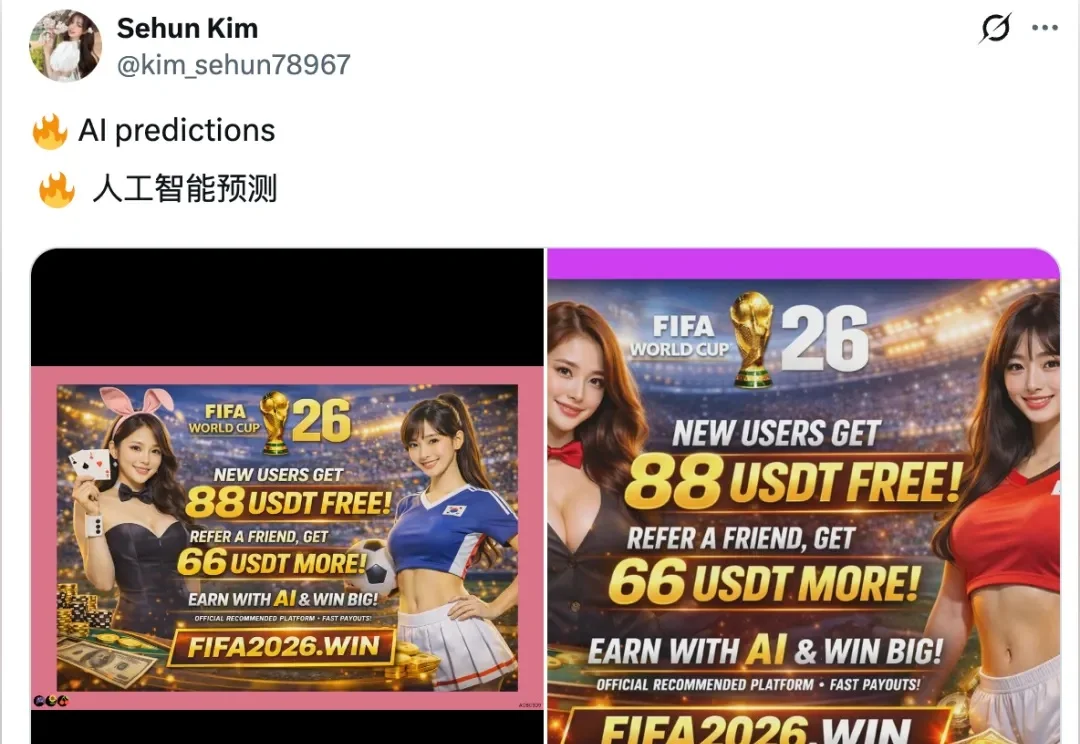
前天,我日常刷 X,当 AI 班狗 🐶 的时候,刷到一条推文,就是下面这条:
这个国产开源模型,把多模态玩出了“魔法”感。

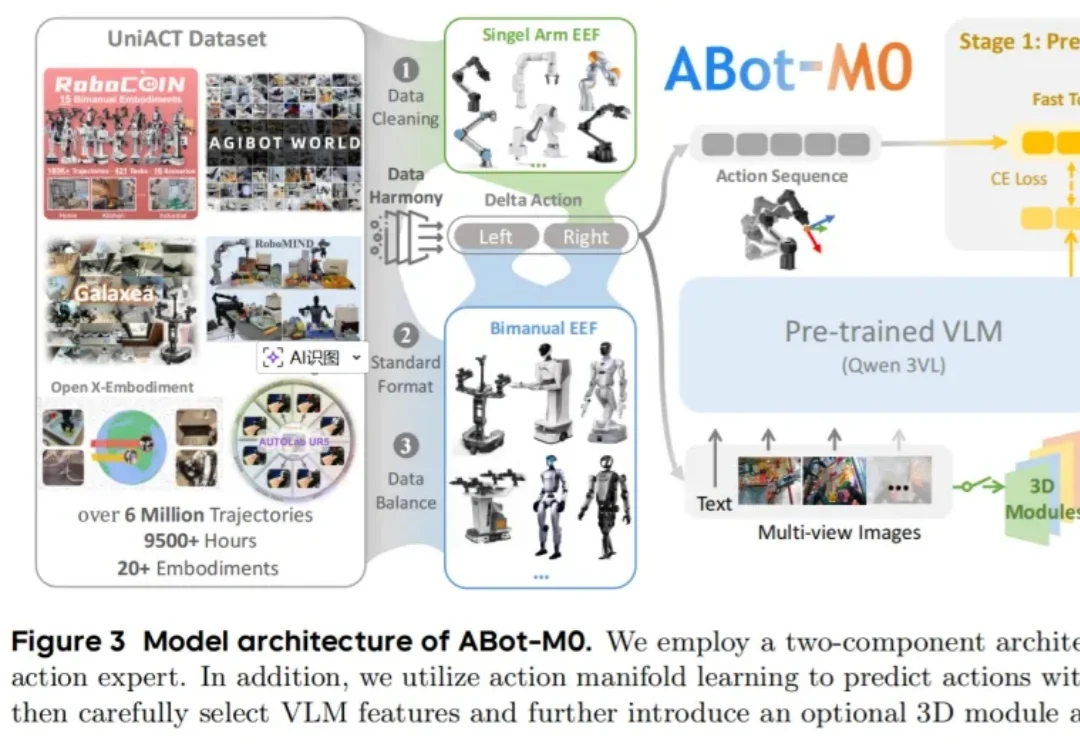
昨天上午,有幸受邀参加了一场具身顶流华山论剑活动。

关于那个神秘的「Pony Alpha」模型的传言,已经在互联网发酵了一周。

一位牛津哲学博士,正在Anthropic教全球顶尖AI模型如何「做人」。这场跨物种的「育儿实验」,比科幻更炸裂。
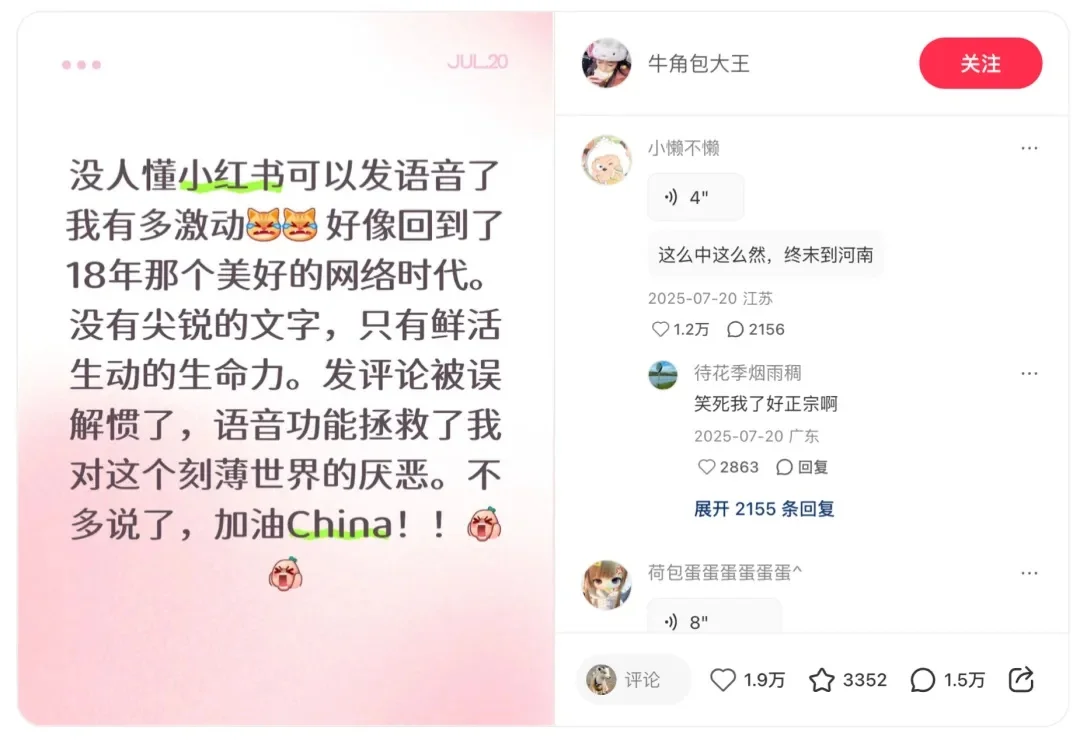
2026 马年注定迎来一个「AI 味」最浓的春节。
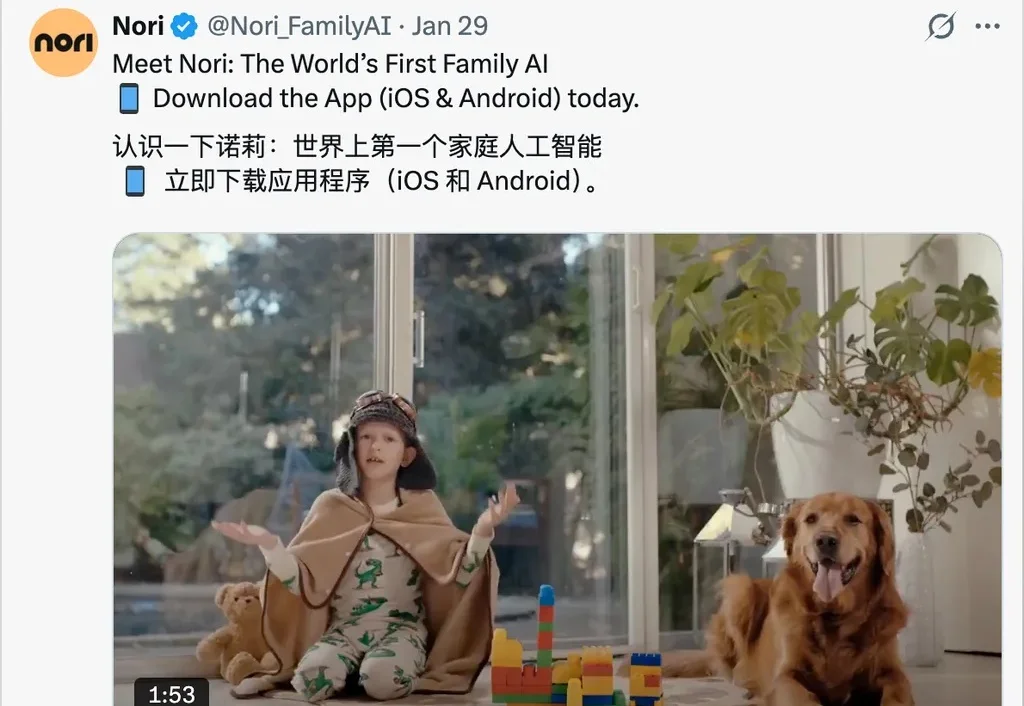
上周,我们全家又大吵了一顿,昨天周日,家里又吵了一次……
春节还没到,「过年的气氛」已经渗入科技圈每个人的毛孔。单说 AI 大模型这一块,刚刚发布的有 kimi 2.5 和 Step 3.5 Flash,即将发布的据说还有 DeepSeek V4,GPT-5.3、Claude Sonnet 5、Qwen 3.5,GLM-5,说不定一觉醒来,现有的技术就要被颠覆。
2026 开年至今,人工智能圈子最火的是一只小龙虾 Clawdbot 。

这不是科幻片,而是 2026 年 2 月刚刚发生的现实。

