中国团队首次夺魁!无问芯穹FlightVGM获FPGA'25最佳论文,峰值算力超GPU21倍
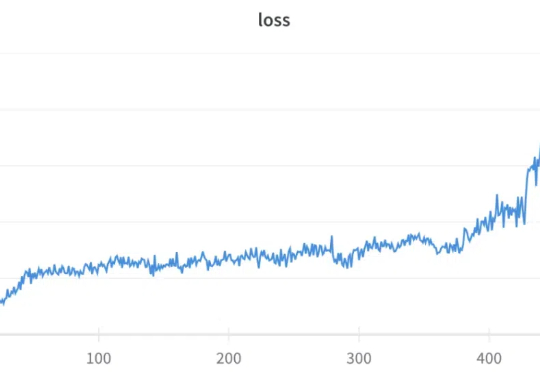
中国团队首次夺魁!无问芯穹FlightVGM获FPGA'25最佳论文,峰值算力超GPU21倍国际可重构计算领域顶级会议 ——FPGA 2025 在落幕之时传来消息,今年的最佳论文颁发给了无问芯穹和上交、清华共同提出的视频生成大模型推理 IP 工作 FlightVGM,这是 FPGA 会议首次将该奖项授予完全由中国大陆科研团队主导的研究工作,同时也是亚太国家团队首次获此殊荣。
来自主题:
AI资讯
10665 点击 2025-03-03 10:45