


DeepSeek华为火线联手!硅基流动首发即限流,全国产API白菜价,零门槛部署
DeepSeek华为火线联手!硅基流动首发即限流,全国产API白菜价,零门槛部署国产大模型云服务平台SiliconCloud(硅基流动),首发上线了基于华为云昇腾云服务的DeepSeek-V3、DeepSeek-R1。 DeepSeek-V3:输入只需1块钱/M tokens,输出2块钱/M tokens
来自主题:
AI资讯
10279 点击 2025-02-02 13:03
 搜索
搜索
国产大模型云服务平台SiliconCloud(硅基流动),首发上线了基于华为云昇腾云服务的DeepSeek-V3、DeepSeek-R1。 DeepSeek-V3:输入只需1块钱/M tokens,输出2块钱/M tokens

除夕前两篇爆款文章在网上流行。一篇是英伟达创始人黄仁勋回应Deepseek的内部信,一篇是幻方/Deepseek创始人梁文锋回应冯骥国运级科技的说法,都是至少十万+的阅读。可惜两篇都是假的。各渠道已经辟谣。

最近几日DeepSeek持续引发美国AI、半导体企业和技术社区的广泛讨论,华尔街、投资人也议论纷纷。Anthropic的CEO发文主张进一步收紧GPU的出口管制。共和党参议员Josh Hawley提出《G2 AI能力脱钩法案》

AI系统生成的内容是否享有版权保护,美国政府机构在最新法规指引中给出了他们的看法。
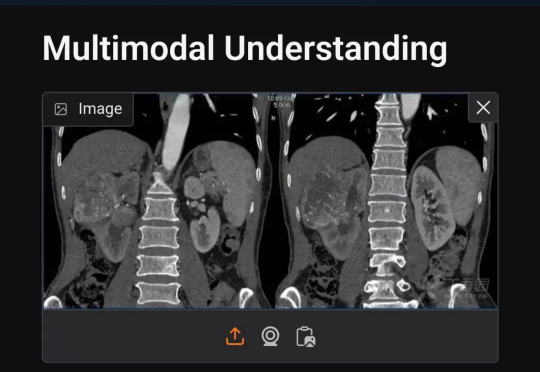
就在除夕前的晚上(2025 年 1 月 27 日),Deepseek 发布了多模态模型 Janus-Pro-7B,该模型在图像生成和多模态理解方面都超过了OpenAI的DALL-E 3(虽然也一般般),我相信能文生图功能一定很优秀了,今天搞点特殊的,测试下图像理解能力对专业的医学影像有没有应用的可行性,以下是常见的五种医学影像测试。

继《换你来当爹》和《灵魂提取器》风靡之后,「狸谱」在春节期间,又上线了《万物变挂件》和《新年萌偶摇》的新玩法。

眼看DeepSeek风头尽显,被逼急的OpenAI果然紧急发布了o3-mni。不光免费用户都能用,每百万输入和输出token价格更是疯狂跳水打骨折价!
春节假期未过半,DeepSeek 掀起的巨浪还在影响着所有和人工智能有关的领域。 今天一觉醒来, DeepSeek R1 模型已经正式加入 Azure AI Foundry 和 GitHub 模型目录,开发人员可以快速地进行实验、迭代,并将这款热门模型集成到他们的工作流程中。
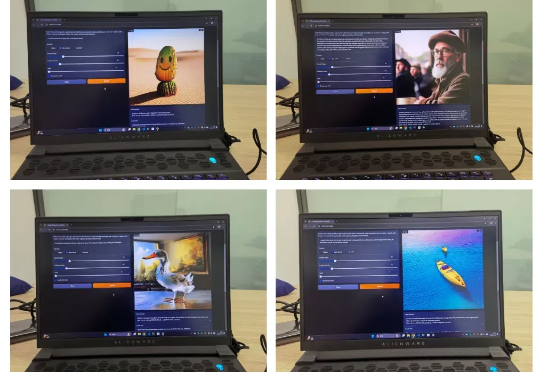
香港大学联合上海人工智能实验室,华为诺亚方舟实验室提出高效扩散模型 LiT:探索了扩散模型中极简线性注意力的架构设计和训练策略。LiT-0.6B 可以在断网状态,离线部署在 Windows 笔记本电脑上,遵循用户指令快速生成 1K 分辨率逼真图片。

27 页综述,354 篇参考文献!史上最详尽的视觉定位综述,内容覆盖过去十年的视觉定位发展总结,尤其对最近 5 年的视觉定位论文系统性回顾,内容既涵盖传统基于检测器的视觉定位,基于 VLP 的视觉定位,基于 MLLM 的视觉定位,也涵盖从全监督、无监督、弱监督、半监督、零样本、广义定位等新型设置下的视觉定位。

2025年春节,正当千万人沉浸在团圆的喜悦中,DeepSeek,这家被誉为“中国版OpenAI”的AI明星企业,却迎来了有史以来最严重的安全危机:攻击规模:黑客发起了史无前例的3.2Tbps DDoS攻击,相当于每秒钟传输130部4K电影;

无论哪个行业,边际生产力都会随着时间下降——服务行业下降更快,TMT行业更慢。每个组织都会达到一个临界规模。死亡、税收和生产力下降是企业不可避免的三大规律。

外媒SemiAnalysis的一篇深度长文,全面分析了DeepSeek背后的秘密——不是「副业」项目、实际投入的训练成本远超600万美金、150多位高校人才千万年薪,攻克MLA直接让推理成本暴降......

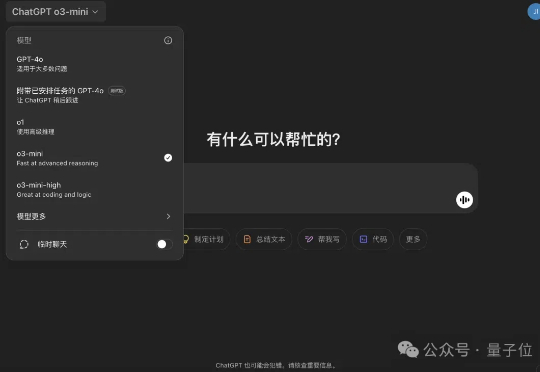
就在刚刚,OpenAI深夜紧急发布了最新推理模型,o3-mini系列。一共包含三个版本:low、medium和high。其中o3-mini和o3-mini-high已经上线:

智东西1月31日消息,据《华尔街日报》援引知情人士消息,OpenAI正在进行初步谈判,计划在一轮融资中筹集至多400亿美元(约合人民币2901亿元),估值将达到3000亿美元(约合人民币2.18万亿元),相较此前估值1570亿美元接近翻倍。
花名欧冶子,同济本科、北大硕士,08年毕业后进入建行总行从事应用架构和安全架构管理工作;16年加入百度,任主任架构师(T9),兼百度云技术部TC主席,是百度飞桨AI Studio第一任产品经理;18年加入贝壳找房,任高级总监,从零搭建贝壳找房的信息安全和业务风险治理体系;23年初创立欧冶科技,23年8月获得苹果资本天使轮融资,目前PreA轮融资进行中,由非凡资本服务。
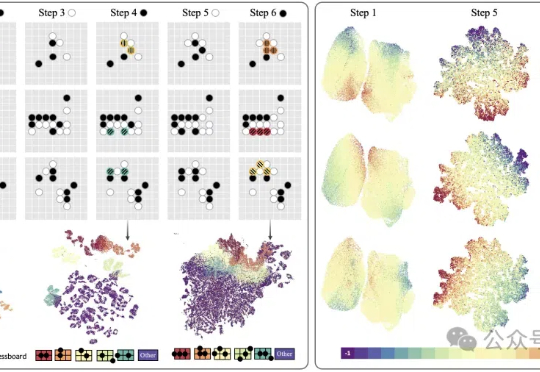
现在,豆包大模型团队联合北京交通大学、中国科学技术大学提出了VideoWorld。

科技巨头Meta和微软相继公布了各自截至12月31日的最新季度财报。

当谷歌在 2018 年推出 BERT 模型时,恐怕没有料到这个 3.4 亿参数的模型会成为自然语言处理领域的奠基之作。
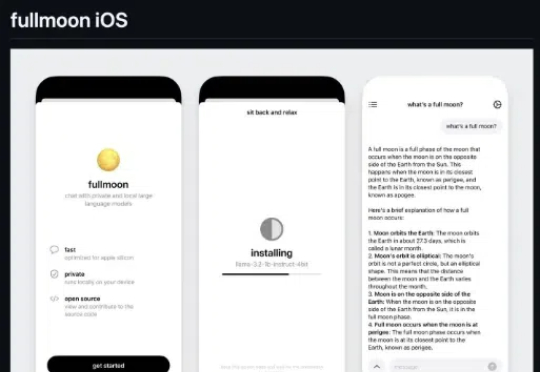
1月13日Mainframe公司发布了可以离线运行在苹果系统(Mac,iPad,iPhone)的本地大语言模型fullmoon: local intelligence

近日,在《金融时报》主编 Roula Khalaf 的最新采访中,谷歌 DeepMind 的 CEO、2024 年诺贝尔化学奖得主 Demis Hassabis 放出了一连串重磅消息

首个FP4精度的大模型训练框架来了,来自微软研究院!

2025 年伊始,全球 AI 业界被 DeepSeek 刷屏。当 OpenAI 宣布 5000 亿美元的「星际之门」计划,Meta 在建规模超 130 万 GPU 的数据中心时,这个来自中国的团队打破了大模型军备竞赛的既定逻辑:用 2048 张 H800 GPU,两个月训练出了一个媲美全球顶尖水平的模型。
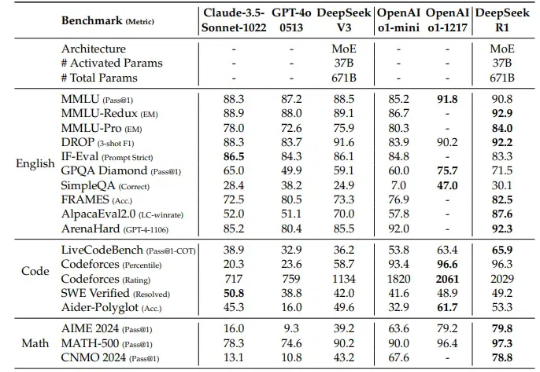
"Deepseek R1不就是一个参数更大的语言模型吗?随便问问题就行了,还需要什么特殊技巧?"——当你说出这句话时,是否意识到自己正像《西游记》里高举紫金葫芦的妖怪,对着齐天大圣叫嚣:"我叫你的名字,你敢答应吗?"

他们急了!特朗普的AI沙皇和微软纷纷指控DeepSeek「偷窃」数据,DeepSeek不断遭受来自美国IP的不间断大规模攻击。Anthropic CEO更是发出檄文:再不加强对中国的芯片管制,就来不及了!

五角大楼的90天AI计划,正式启动了。美国印太司令部将在实验中,评估AI在现实军事场景中对抗我国等高科技对手的潜力。据悉,重点集中在海军应用上。
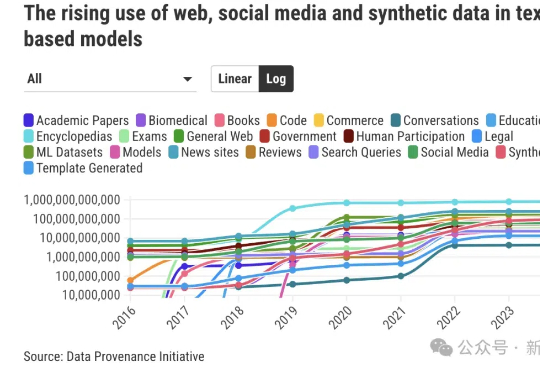
相比LLM和Agent领域日新月异、高度成熟的进展相比,数据收集方面的规范有明显滞后。由超过50名研究人员组成的「数据溯源计划」(DPI)旨在回答这样一个问题:AI训练所需的数据究竟来自何处?


梁文锋带领着DeepSeek,还在继续搅动大模型行业。继用R1模型炸场之后,1月28日凌晨,除夕夜前一晚,DeepSeek又开源了其多模态模型Janus-Pro-7B,宣布在GenEval和DPG-Bench基准测试中击败了DALL-E 3(来自 OpenAI)和Stable Diffusion。

