

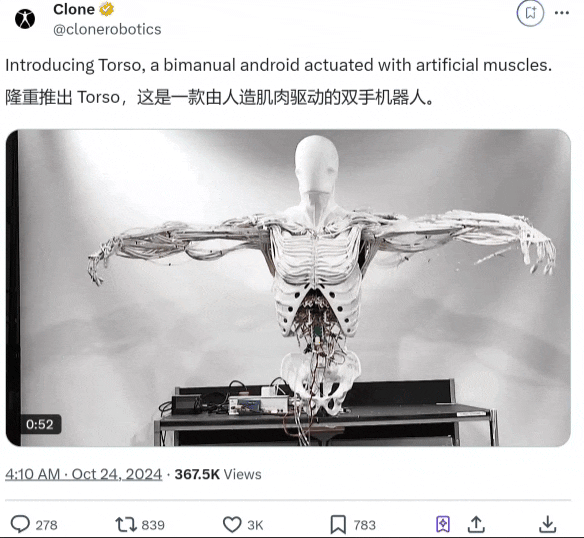
西部世界成真:仿生肌肉驱动的机器人来了,英伟达科学家站台
西部世界成真:仿生肌肉驱动的机器人来了,英伟达科学家站台西部世界式的仿生机器人成真了?! 人造肌肉驱动下,这个名叫Torso的上半身机器人开始拱手作揖、前后左右咔咔转动脖子……
来自主题:
AI资讯
4603 点击 2024-10-25 10:33
 搜索
搜索
西部世界式的仿生机器人成真了?! 人造肌肉驱动下,这个名叫Torso的上半身机器人开始拱手作揖、前后左右咔咔转动脖子……
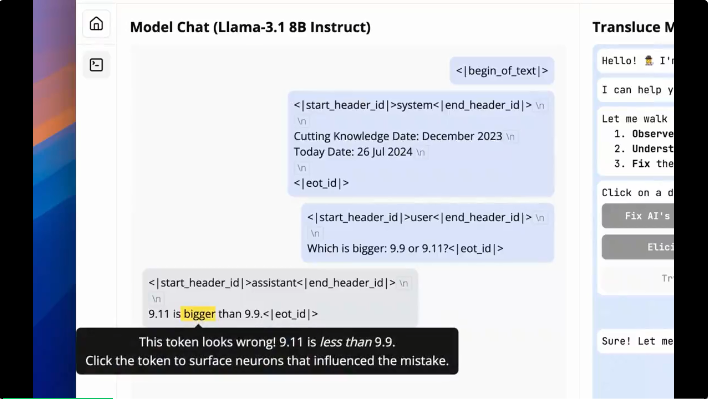
大模型分不清“9.9和9.11哪个更大”的谜团,终于被可解释性研究揭秘了!
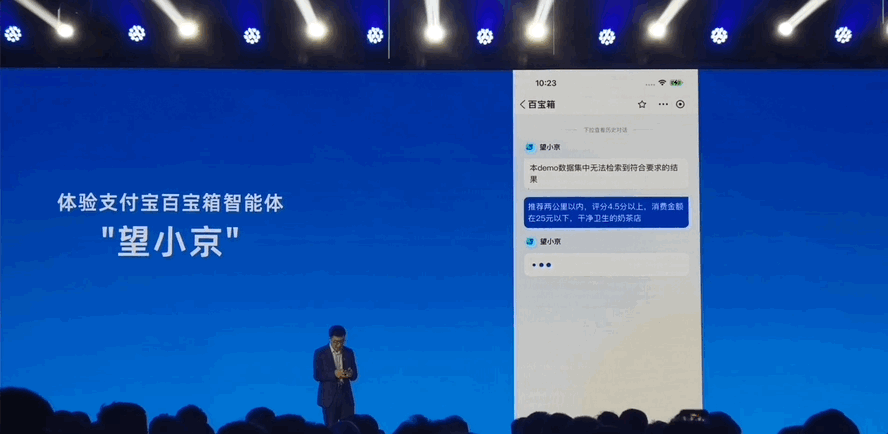
几个工程师、一个星期,就能做一个AI Agent应用了。 效果be like—— 能理解用户复杂长命令,推荐符合要求的奶茶店。

跟讯飞星火AI女神视频面对面,国产《Her》从此有了脸!
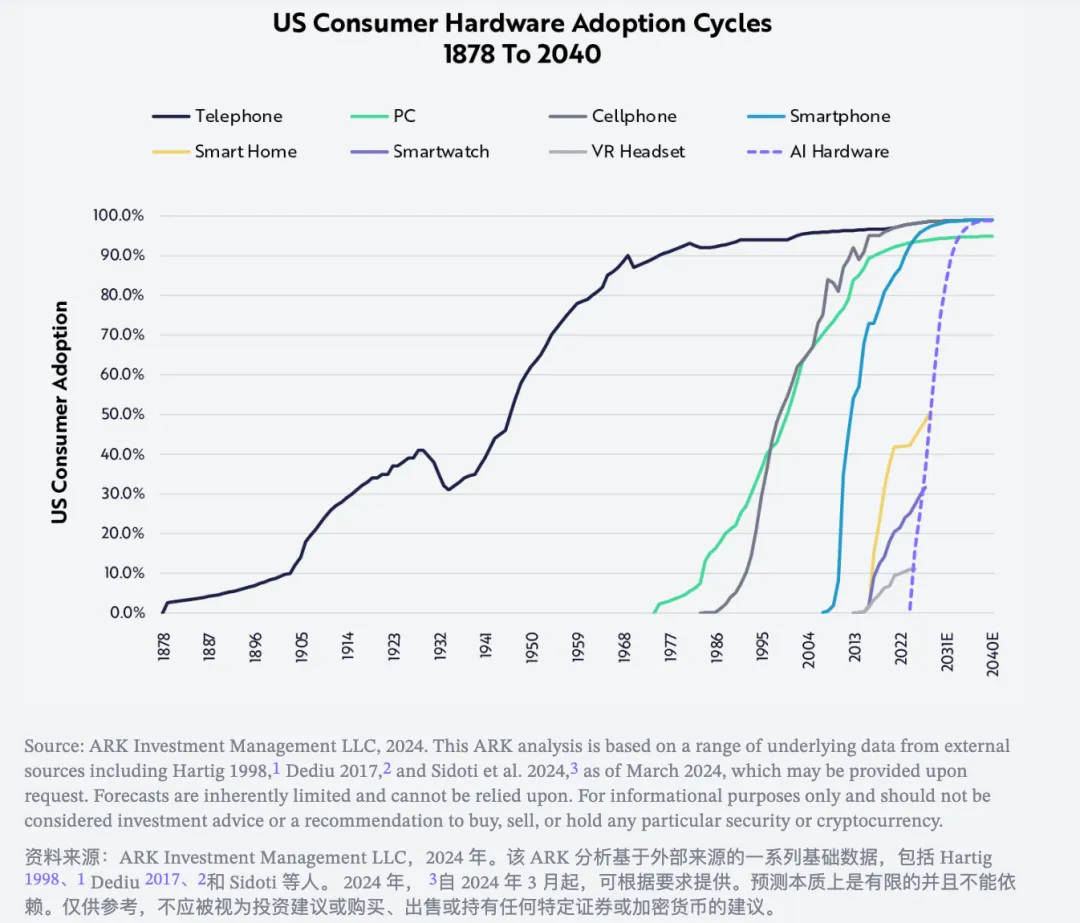
计算机的历史标志着个人和企业生产力的飞跃。20世纪70年代的命令行界面(CLIs)演变至80年代的图形用户界面(GUIs),实现了复杂命令的图形化抽象,通过视觉图标和窗口简化操作。接着,计算机操作的易学性提升加快了个人电脑(PC)在1990年代的普及,进而催生了万维网以及基于其上的互联网应用的发展。

家人们,OpenAI 又上新了!推出了全新的生成式模型sCM(Simplifying Continuous-Time Consistency Models),支持视频、图像、三维模型和音频的生成。
赶着1024的程序员节,刚刚稚晖君发了个大福利: 智元人形机器人,全套资料全球开源,包括设计图纸和代码!

巴克莱预计,随着AI应用的普及,推理计算的需求预计将在2026年达到70%以上。到那时,可能需要比预期多4倍的芯片资本支出才能满足所有需求。

英伟达将携手Wipro、TCS和Infosys等印度IT巨头,合作开发全球性AI模型。

iOS带着ChatGPT来了 苹果开发者测试版系统上新!更多Apple Intelligence功能已经可用了,包括ChatGPT集成。 iOS 18终于带着ChatGPT来了。

最近,字节在AI方面又搞了个大新闻。 一个字节的实习生,因为对团队资源分配不满,用恶意代码把模型训练过程给投了“毒”,字节这边损失不小
OPPO收购波形智能,加速端侧大模型布局。

个体的效率提升未必能转化为组织的效率提升
AI开发者在资源汹涌下与投资人、大厂关系微妙,合作与预期存在不匹配。
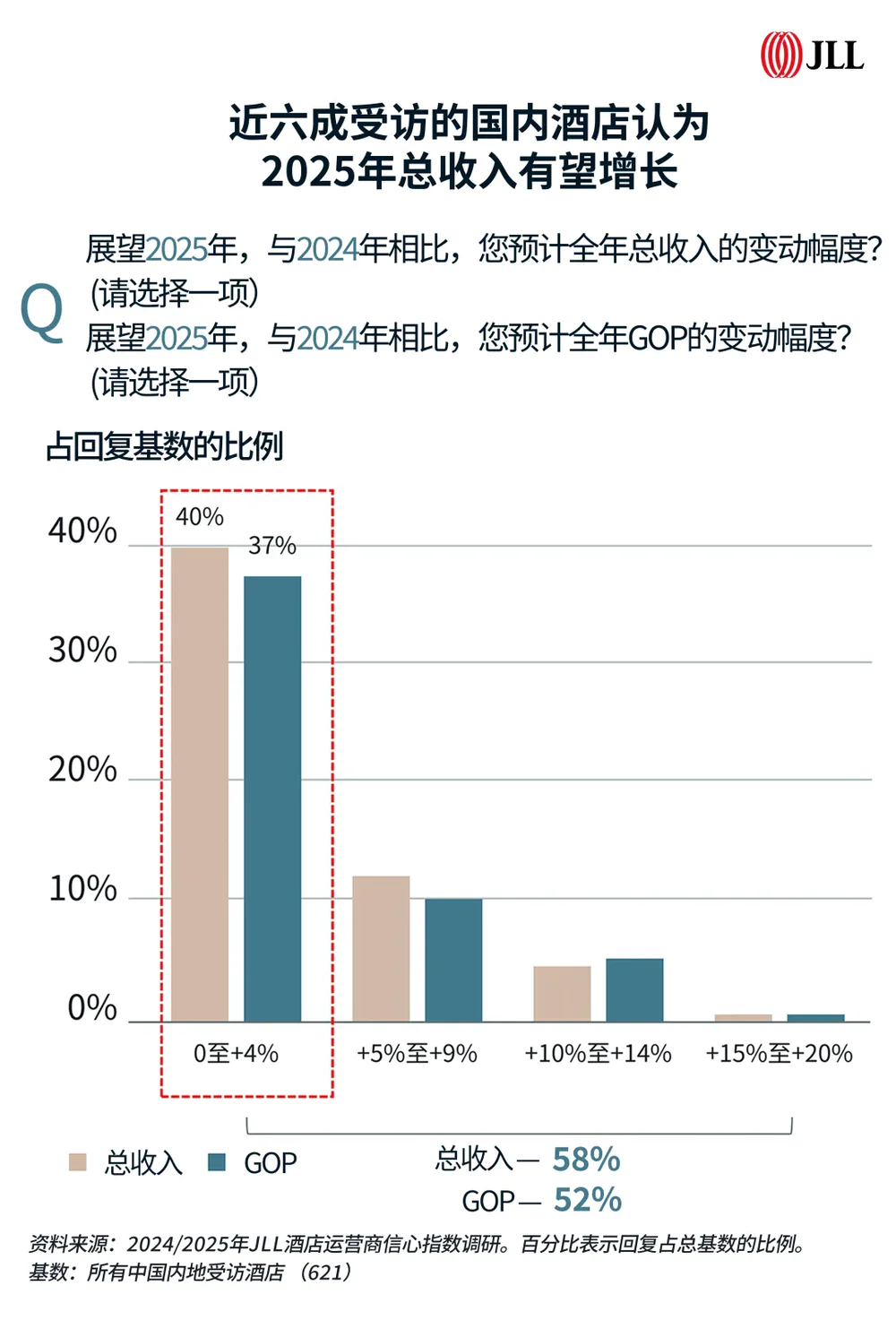
AI技术正在重塑酒店人力市场,推动灵活用工和智能化管理。
Miles Brundage,OpenAI 的长期政策研究员和公司 AGI Readiness 团队的高级顾问,已离职。

最大的AI机会存在于企业、政府以及一些令人兴奋的新公司中。数以百计的Google Cloud客户已经在他们的业务和全球范围内采用了AI Agent和生成式AI解决方案——许多人看到了明显的投资回报。本文提供了185家行业领导者如何在今天利用AI的快照。
Vozo创立于此背景之下,这家初创公司致力于通过AI技术,让每个人都能够轻松地表达自己的创意与故事。

两位清华校友,在OpenAI发布最新研究—— 生成图像,但速度是扩散模型的50倍。 路橙、宋飏再次简化了一致性模型,仅用两步采样,就能使生成质量与扩散模型相媲美。

工具调用是 AI 智能体的关键功能之一,AI 智能体根据场景变化动态地选择和调用合适的工具,从而实现对复杂任务的自动化处理。例如,在智能办公场景中,模型可同时调用文档编辑工具、数据处理工具和通信工具,完成文档撰写、数据统计和信息沟通等多项任务。

现如今,大型语言模型(LLM)生成的内容已经充斥了整个互联网,并且这些模型还能模仿各种类似真人的语气和行文风格,让人难以分辨眼前的文本究竟来自人类还是 AI。

「我们的 Blackwell 芯片存在设计缺陷,虽然可以正常使用,但该设计缺陷导致良率低下,」黄仁勋表示。「这 100% 是英伟达的错。」

大模型为什么认为 9.8<9.11?神经元级别的解释来了。 9.8 和 9.11 到底哪个大?这个小学生都能答对的问题却难倒了一众大模型,很多模型输出的结果都是「9.8<9.11」。

AI营销大战还能怎么卷? 今年上半年,AI营销大战打得轰轰烈烈。

为应对公司在大规模文本、图像等非结构化数据处理上的业务增长需求,笔者着手调研当前流行的开源向量数据库。主要针对查询速度、并发度和召回率这几大核心维度进行深入分析,以确保选定的数据库方案能够在实际业务场景中高效应对大规模数据检索和高并发需求。通过全面对比不同数据库的表现,得出可靠的调研结论。

2023年8月18日,字节跳动旗下AI对话产品Grace,更名为「豆包」。

本期TICLAB直播,我们特别邀请到跃然创新CEO李勇,飞迅智瞳创始人&CEO姜洪兵,和我们一起聊聊他们如何在AI教育硬件领域寻找产品的市场契合点(PMF),以及他们如何突破传统教育以及硬件的局限,用技术为教育带来创新的解决方案。

TL;DR:DuoAttention 通过将大语言模型的注意力头分为检索头(Retrieval Heads,需要完整 KV 缓存)和流式头(Streaming Heads,只需固定量 KV 缓存),大幅提升了长上下文推理的效率,显著减少内存消耗、同时提高解码(Decoding)和预填充(Pre-filling)速度,同时在长短上下文任务中保持了准确率。

目前,机器人的训练数据大体上可分为三类:第一类是真实的遥操数据,第二类是高质量的仿真合成数据,第三类是人类的行为数据、其主要源于互联网视频。

押注大模型和大算力,商汤要转型云厂商? 昨日,“AI四小龙”中的头部公司商汤迎来了公司成立十周年。在这个颇具纪念意义的日子里,一场裁员行动正在商汤内部进行。

