


小鹏副总裁矫青春离职,测试、AI 团队整合增效
小鹏副总裁矫青春离职,测试、AI 团队整合增效向何小鹏汇报的人又变多了。
来自主题:
AI资讯
7129 点击 2024-07-10 19:10
 搜索
搜索
向何小鹏汇报的人又变多了。

不大可能重现iPhone奇迹。

竞速迎“风”而上,抖音、快手、博纳“开卷”AI短剧。

Kimi探索出了一条新路。

大幅节省算力资源,又又又有新解了!!
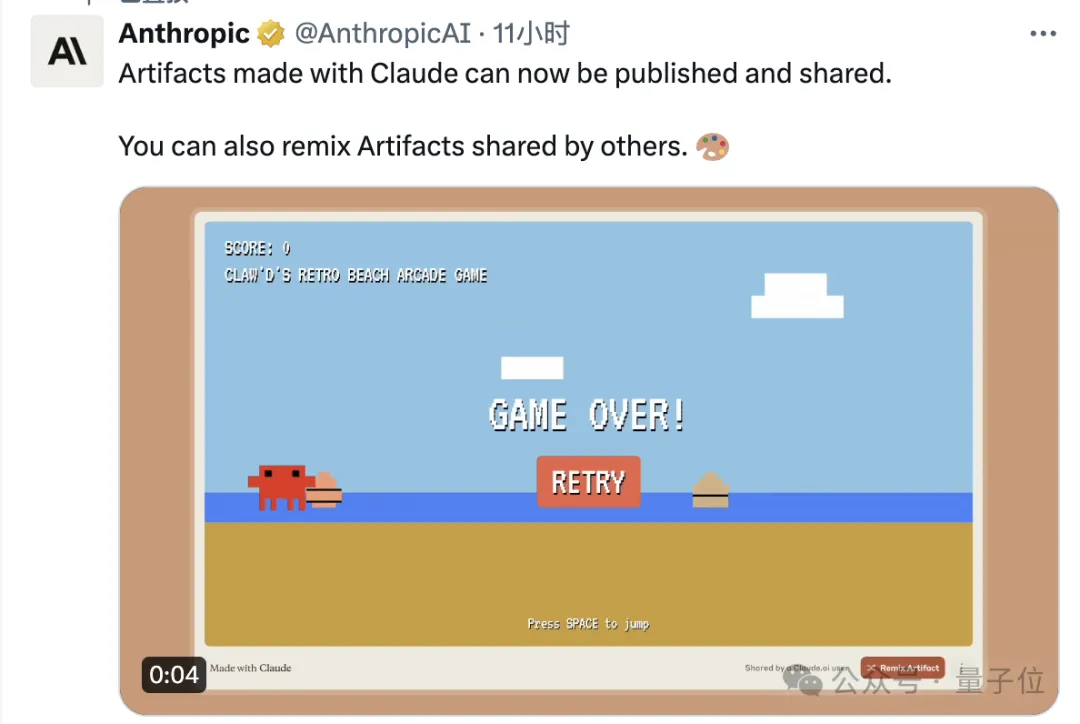
Claude 3.5上新的“工坊模式”(Artifacts)再次更新,写完的网页应用支持一键分享了!

AI一天,人间一年。
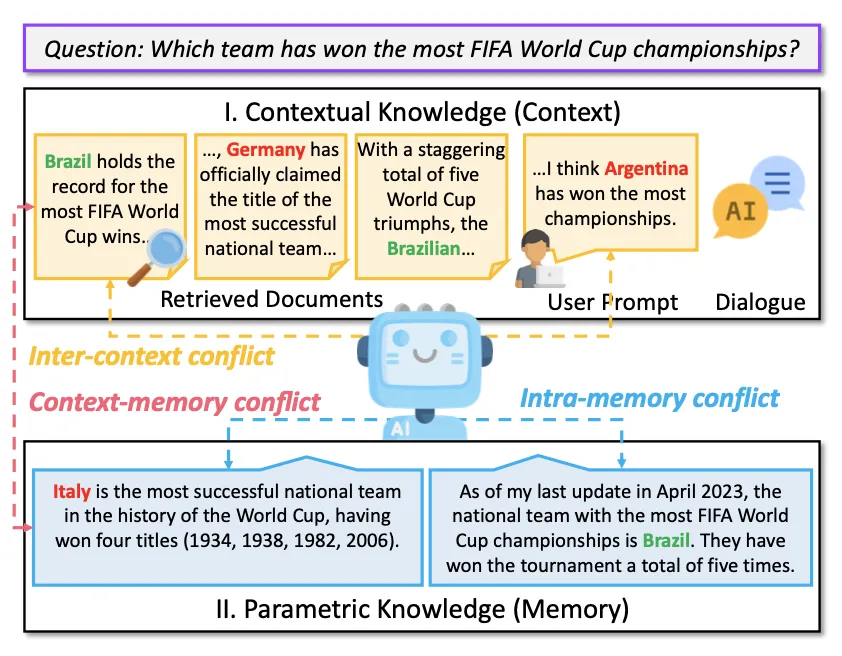
随着人工智能和大型模型技术的迅猛发展,检索增强生成(Retrieval-Augmented Generation, RAG)已成为大型语言模型生成文本的一种主要范式。
不会写 prompt 的看过来。

ControlNet作者张吕敏(Lvmin Zhang)又又又发新作了!

释放进一步扩展 Transformer 的潜力,同时还可以保持计算效率。

这几年,人们都在谈论大模型。特别是在 Scaling Law 的指导下,人们寄希望于将更大规模的数据用于训练,以无限提升模型的智能水平。在中国,「数据」作为一种与土地、劳动力、资本、技术并列的生产要素,价值越来越被重视。

工业 AI ,没有新王,光而无耀,静水深流。

神经网络拟合数据的能力受哪些因素影响?CNN一定比Transformer差吗?ReLU和SGD还有哪些神奇的作用?近日,LeCun参与的一项工作向我们展示了神经网络在实践中的灵活性。

近日,来自牛津大学的研究人员推出了利用语义熵来检测LLM幻觉的新方法。作为克服混淆的策略,语义熵建立在不确定性估计的概率工具之上,可以直接应用于基础模型,无需对架构进行任何修改。

全球首个芯片设计开源大模型SemiKong正式发布,基于Llama 3微调而来,性能超越通用大模型。未来5年,SemiKong或将重塑价值5000亿美元的半导体行业。

面对GenAI的技术浪潮,很多人都会在不断迭代更新的技术中逐渐迷失。站在潮头的Sapphire、Emergence、Menlo等风投公司,又会如何看待这场AI变局的现状与走向?

就在昨天,OpenAI正式封锁了中国地区API,但微软却向开发者们大方伸出橄榄枝:速来Azure!与此同时,中国大模型,已经准备好了一波爆发。

最近上海 WAIC 大会正在火热举办中,此次AI盛会中不仅有致力于人工智能发展的优秀企业,大模型、具身机器人等产品,还有AI领域的顶尖大佬们,可以说是神仙打架的大场面了。
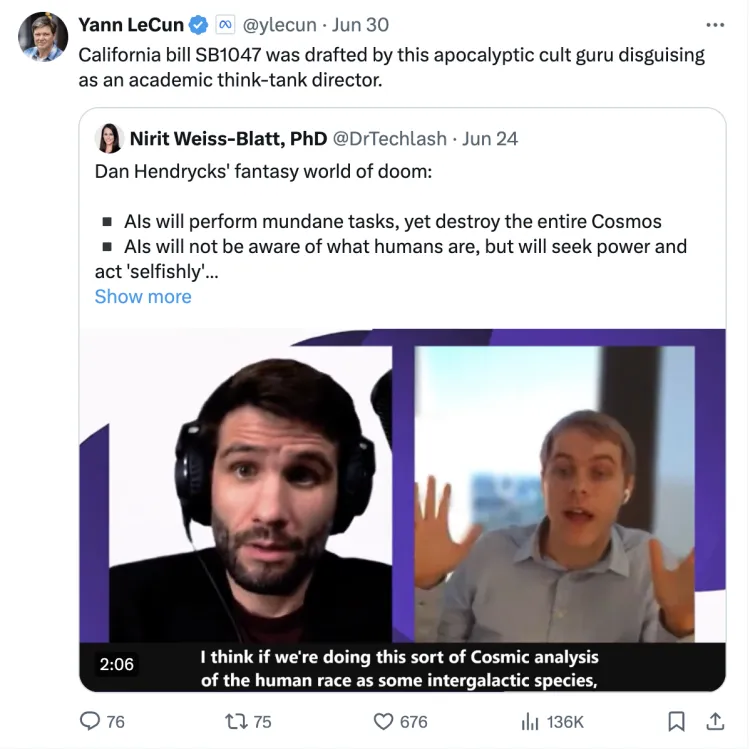
Meta首席人工智能科学家、深度学习之父Yann LeCun又开喷了。

近期,商汤科技 - 南洋理工大学联合 AI 研究中心 S-Lab ,上海人工智能实验室,北京大学与密歇根大学联合提出 DreamGaussian4D(DG4D),通过结合空间变换的显式建模与静态 3D Gaussian Splatting(GS)技术实现高效四维内容生成。
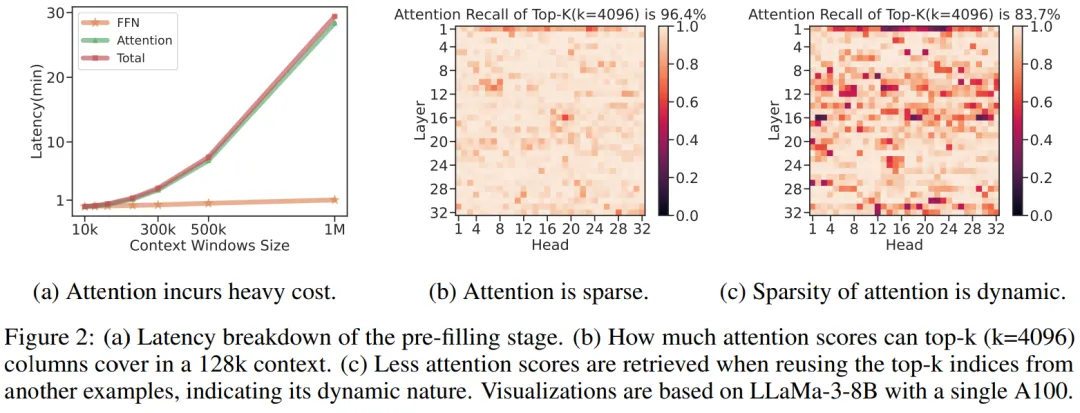
微软的这项研究让开发者可以在单卡机器上以 10 倍的速度处理超过 1M 的输入文本。

生物神经网络有一个重要的特点是高度可塑性,这使得自然生物体具有卓越的适应性,并且这种能力会影响神经系统的突触强度和拓扑结构。

这是一条少有人走过的路。

科学家们一直致力于让机器人更敏捷,此次哈佛大学与谷歌DeepMind人工智能实验室的合作有了新突破。他们创造出了一只搭载了AI大脑的「虚拟大鼠」,能够模仿真实啮齿动物的所有动作,甚至做出了一些没有被明确训练过的「新奇行为」。此项研究有望开辟「虚拟神经科学」新领域,对于脑科学和机器人学意义重大。

今天关于大模型的狂热里充满了各种误解。

SelfGNN框架结合了图神经网络和个性化自增强学习,能够捕捉用户行为的多时间尺度模式,降低噪声影响,提升推荐系统鲁棒性。
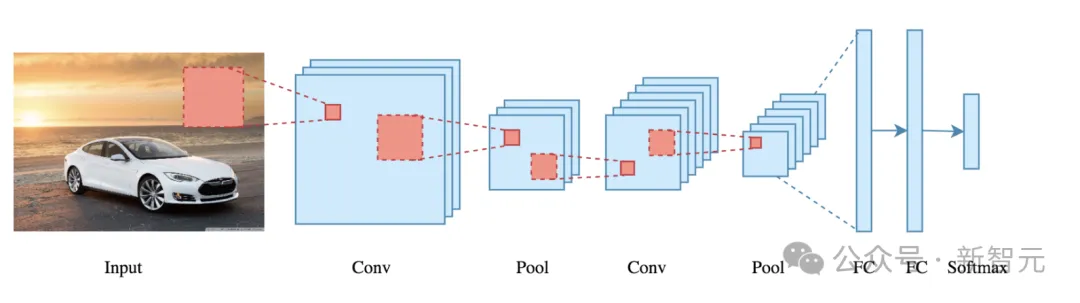
下一代视觉模型会摒弃patch吗?Meta AI最近发表的一篇论文就质疑了视觉模型中局部关系的必要性。他们提出了PiT架构,让Transformer直接学习单个像素而不是16×16的patch,结果在多个下游任务中取得了全面超越ViT模型的性能。

今日,Odyssey视觉AI发布预告,这款获得GV 900万美元种子资金的创新技术,旨在用AI技术讲好电影故事。具备强大的视觉内容生成与控制能力,视觉效果对标好莱坞制作水平。

来自佐治亚理工学院和英伟达的两名华人学者带队提出了名为RankRAG的微调框架,简化了原本需要多个模型的复杂的RAG流水线,用微调的方法交给同一个LLM完成,结果同时实现了模型在RAG任务上的性能提升。

