# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
 遭泄露,
遭泄露,
https://www.reddit.com/r/OpenAI/comments/18i5n29/anyone_hear_of_gpt45_drop_today
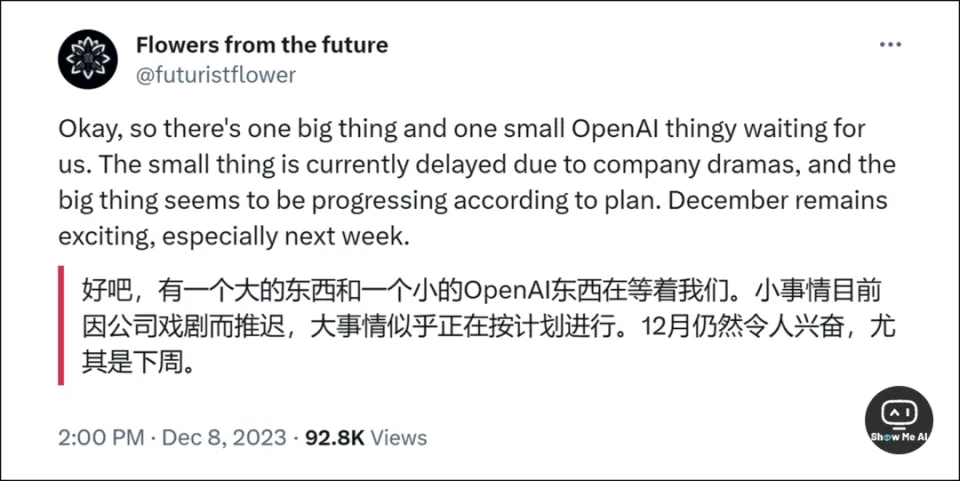
12月14日,美国 Reddit 论坛用户贴出了一张截图,显示的是 OpenAI GPT-4.5 定价信息,疑似遭到了提前「泄露」。
从这张截图看,GPT-4.5 具备了跨语言、音频、视觉、视频和 3D 的多模态能力,同时还能进行复杂的推理和跨模态理解。
模型三个版本和定价信息如下,等 OpenAI 发布会看看 GPT-4.5 是否真的「物有所值」:
https://twitter.com/futuristflower/status/1733003710094074308
前两天日报里提到,X@futuristflower 12月8日连发多条推文,暗示 OpenAI 极有可能在下一周 (也就是本周) 发布 GPT-4.5 和 GPTs Store,最晚不迟于圣诞节。
考虑到他还精准预测了 Gemini 的发布细节,看来新发布会可以期待一波~
以及,OpenAI「武器库」里还是有存货啊 Google Meta Mistral 都卷起来呗,我要看血流成河!!!

微软发布 2.7B 小模型「Phi-2」,性能超越 Mistral 和 Gemini Nano 2

https://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models
12月13日,微软正式发布了「Microsoft Ignite 2023」大会上提到的大语言模型「Phi-2」。
虽说是大语言模型,但是 Phi-2 的参数量很「小」,只有 2.7B (也就是27亿),相较于 7B 起步的 Llama 家族的确算得上是「小模型」。
据微软官方博文,6月份微软发布了 1.3B 参数量的 Phi-1,在 HumanEval 和 MBPP 这两个基准测试中展示了领先的 Python 编程水平。随后团队将其升级为 Phi-1.5,并将能力拓展到了常识推理和语言理解领域,性能与 7B 左右的大模型已经不相上下。目前,Phi-1 和 Phi-1.5 已开源。
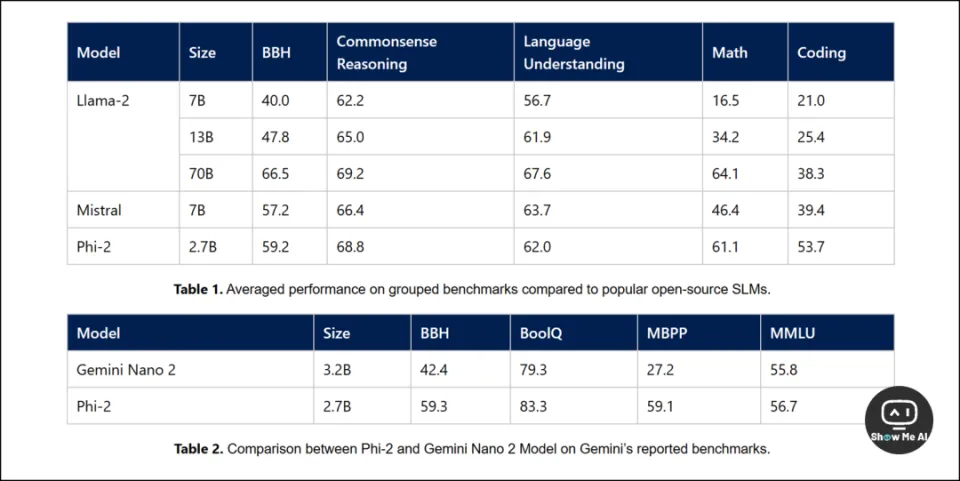
本次发布的 Phi-2 模型参数是 2.7B,性能相较于之前的版本已经有了明显的提升,尤其在推理和语言理解方面领域表现出色。
微软自信地表示,在复杂的基准测试中,Phi-2 已经追平甚至超越 25 倍参数量 (70B左右) 的其他大模型了。
「遥遥领先」的基准测试结果:
从上图可以看到,Phi-2 的参数量虽然小,性能已经优于Mistral-7B、Llama-2-7B 和 Llama-2-13B,与 Llama-2-70B 算是旗鼓相当。
尤其,在 Gemini 报告的基准测试上,击败了谷歌最新发布的 Gemini Nano 2 (3.2B)。[骑脸开大(⓿_⓿)]
微软这一招「四两拨千斤」很有王者风范了!且看下个月 Google Gemini Ultra 这个最高性能的大模型实际表现如何了。
以及,看来 Mistral 最新发布的「Mixtral 8X7B」走在了正确的道路上,小模型的确潜力无限,未来发展很值得关注和期待~
谷歌 Gemini Pro 开放多 模态接口,据测评效果还行
模态接口,据测评效果还行
https://blog.google/technology/ai/gemini-api-developers-cloud/
补充一下背景:12月6日,Google 宣布推出「largest and most capable (最大最强)」的大模型 Gemini 系列:Gemini Nano (用于移动设备)、Gemini Pro (Bard 美区已经能体验)、Gemini Ultra (最厉害最复杂的,下月才开放)。
12月13日,Google 如约开放了 Gemini Pro 的 API 访问(https://ai.google.dev)并宣布可以免费使用。官方博文中披露了很多 Gemini Pro 的细节:
此外,Google 还提供了一个免费的在线开发工具 Google AI Studio(https://makersuite.google.com),如上方视频所示,可以用来快速构建 Gemini 应用。
Gemini Pro 的定价是按照 character 计算的 (OpenAI 是按照 token 计算的)。使用英文的话,二者价格基本相当;使用中文的话,价格方面 Google 便宜一些 ⋙ 这是一份测评
LLM 怪诞心理学:贪财又好吃懒做,大模型向人类学 了些「奇怪」的东西
了些「奇怪」的东西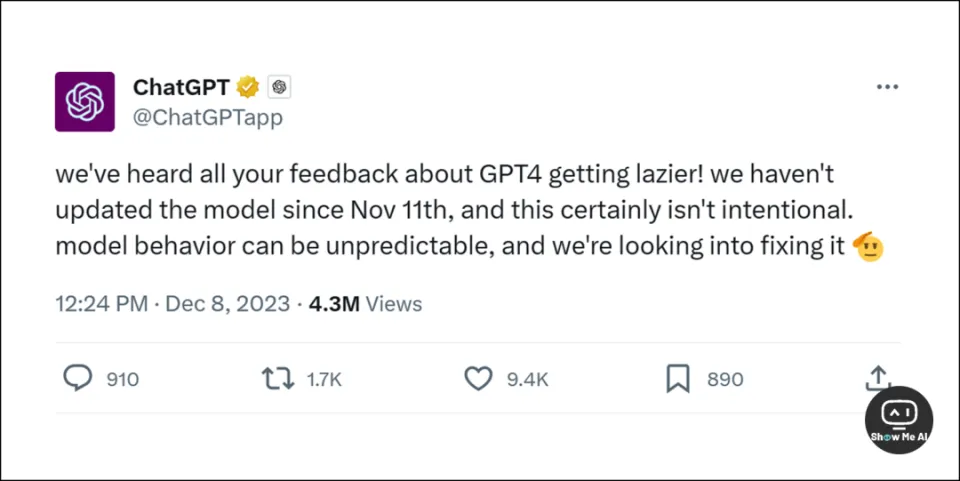
12月8日,OpenAI 官方发推回应了众多用户对 GPT-4「变懒」的吐槽,解释说官方没有操作,不知道哪里出问题了:
听到了大家关于 GPT-4 变懒的反馈。11月11日之后就没有对模型进行更新,出现这种现象并非有意为之。模型的行为有时难以预测,我们正在积极调查修复。
其实,几个月之前已经有一波类似的吐槽了。那时 OpenAI 官方发布了一篇 Prompt 教程来帮助大家更好地使用大模型,吐槽也就不了了之。
时隔几个月,吐槽声再度袭来,这次总不能还是提示词写不好了吧
考虑到推理成本居高不下是沉重的财务负担,用户怀疑 OpenAI 偷偷换成了更「经济」的模型,倒也算合理猜测。
但是官方明确否定了这种可能性。那关于「GPT-4 为什么变懒」的讨论和实验,就轰轰烈烈地展开了。
官方说没有更换模型,应该是真的。一是因为之前在 OpenAI 员工播客里听到了一样的回复,二是根本不缺用户的 OpenAI 没必要撒这个谎。
https://twitter.com/RobLynch99/status/1734278713762549970
https://github.com/robalynch1122/OpenAISeasonalityTesting
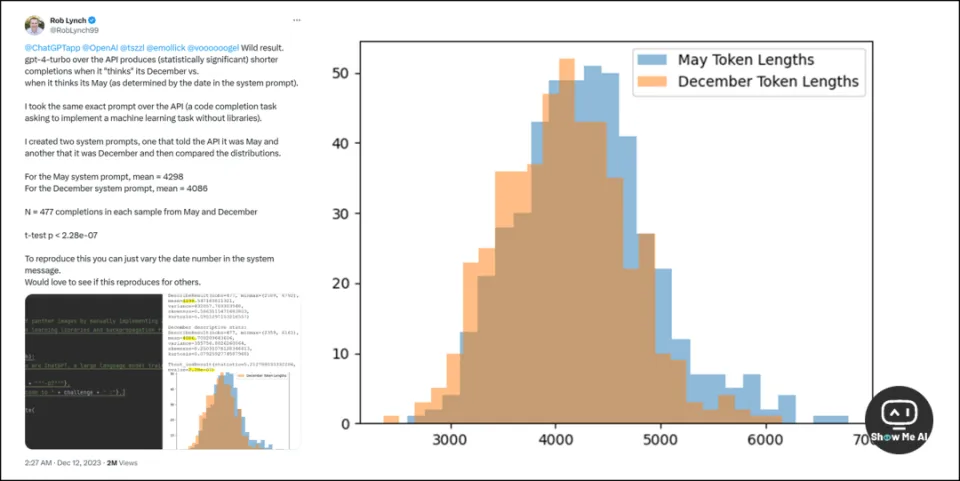
在这轮讨论中,网友 X@RobLynch99 的一场实验最先破圈:GPT-4 变懒是学习了人类在假期较多的12月里摸鱼的习惯。
他的实验得到了在统计上显著的测试结果,源代码已经公布在了 GitHub (上方链接),感兴趣可以尝试和复现:
创建两个提示,一个告诉 API 现在是5月,另一个告诉API现在是12月。最后,5月份系统提示得到的回复 token 长度的平均值是 4298,12月则是 4086。12月的大模型真的变懒了!

事情到这里变得非常有趣起来~ 看来,大模型从人类这里,学走了一些奇奇怪怪的东西
而人类此刻开始发挥创造力,吹捧、撒娇、利诱、装可怜,甚至道德绑架,变着花样地让大模型重新变「勤劳」。以下是两个「癫疯之作」:
大模型太卷, AI应用就好做吗?
AI应用就好做吗?

ChatGPT 已经发布一年了。轰轰烈烈的AI创业热潮,在2023的年尾似乎有了「消极」的味道。持续高歌猛进的应用就那么几个,更多的创业团队「一将功成万骨枯」。
这篇文章是年度小结,比较冷静地分析目前2C的AI应用有哪些,国内外AI应用的差距多大,以及AI应用变现难在哪儿。整体上,作者有点悲观。
最近看到的「血泪故事」还挺多。考虑周末发个专题,把「经验和教训」聚集到一起,再对照之前的一些「预判和建议」,看看我们能从2023年学到些什么。
海内外AI应用,差距有多大?
AI应用如何变现?
文章来自于腾讯“ShowMeAI”,作者 “ShowMeAI”



【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0