# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
新增 Qwen3-0.6B 在 Ag_news 数据集 Zero-Shot 的效果。新增 Qwen3-0.6B 线性层分类方法的效果。
调整 Bert 训练参数(epoch、eval_steps),以实现更细致的观察,避免严重过拟合的情况。[25/04/28]
TODO:
最近在知乎上刷到一个很有意思的提问 Qwen3-0.6B 这种小模型有什么实际意义和用途。
查看了所有回答,有人提到小尺寸模型在边缘设备场景中的优势(低延迟)。
也有人提出小模型只是为了开放给其他研究者验证 scaling law(Qwen2.5 系列丰富的模型尺寸为开源社区验证方法有效性提供了基础)。
还有人说 4B、7B 的 Few-Shot 效果就已经很好了甚至直接调用更大的 LLM 也能很好的解决问题。
让我比较感兴趣的是有大佬提出小模型在向量搜索、命名实体识别(NER)和文本分类领域中很能打,而另一个被拿来对比的就是 Bert 模型。
在中文文本分类中,若对 TextCNN、FastText 效果不满意,可能会尝试 Bert 系列及其变种(RoBerta 等)。
但以中文语料为主的类 Encoder-Only 架构模型其实并不多(近期发布的 ModernBERT,也是以英文和 Code 语料为主),中文文本分类还是大量使用 bert-base-chinese 为基础模型进行微调,而距 Bert 发布已经过去了 6 年。
Decoder-Only 架构的 LLM 能在文本分类中击败参数量更小的 Bert 吗?所以我准备做一个实验来验证一下。
不想看实验细节的,可以直接看最后的结论和实验局限性部分。
GPU:RTX 3090(24G)。
模型配置:

数据集配置:fancyzhx/ag_news,分类数为 4,分别为 World(0)、Sports(1)、Business(2)、Sci/Tech(3)。训练样本数 120000,测试样本数 7600,样本数量绝对均衡。
数据集展示:
{
"text": "New iPad released Just like every other September, this one is no different. Apple is planning to release a bigger, heavier, fatter iPad that..."
"label": 3
}
选择该数据集是在 Paper with code 的 Text Classification 类中看到的榜单,并且该数据集元素基本上不超过 510 个 token(以 Bert Tokenizer 计算)。
因为 Bert 的最大输入长度是 510 个 token,超过会进行截断,保留前 510 个 token,所以为了进行公平的比较,尽量避免截断。
因为是多分类任务,我们以模型在测试集上的 F1 指标为标准,F1 值越高,模型效果越好。
Bert 的训练比较简单,将文本使用 Tokenizer 转换成 input_ids 后,使用 Trainer 进行正常训练即可。
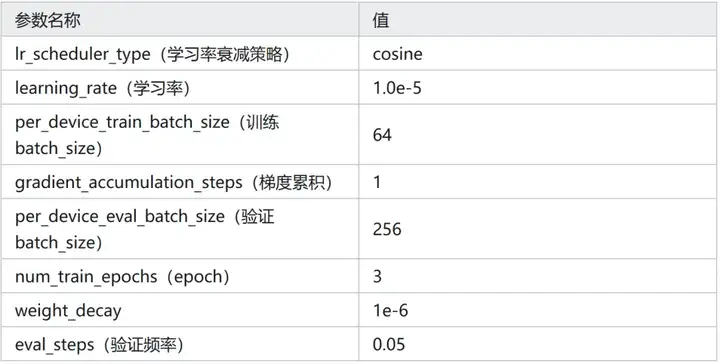
训练参数(若未单独指出,则代表使用 Trainer 默认值):
训练过程中模型对测试集的指标变化:
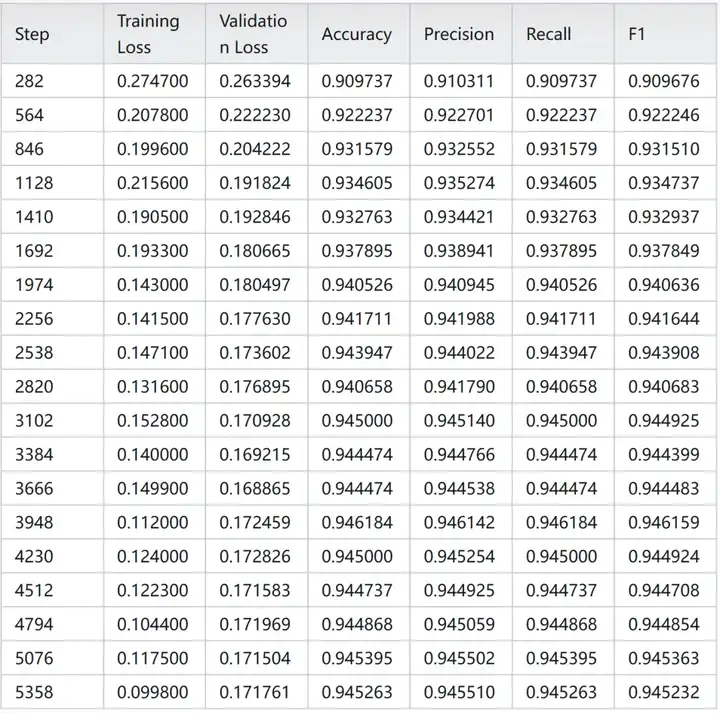
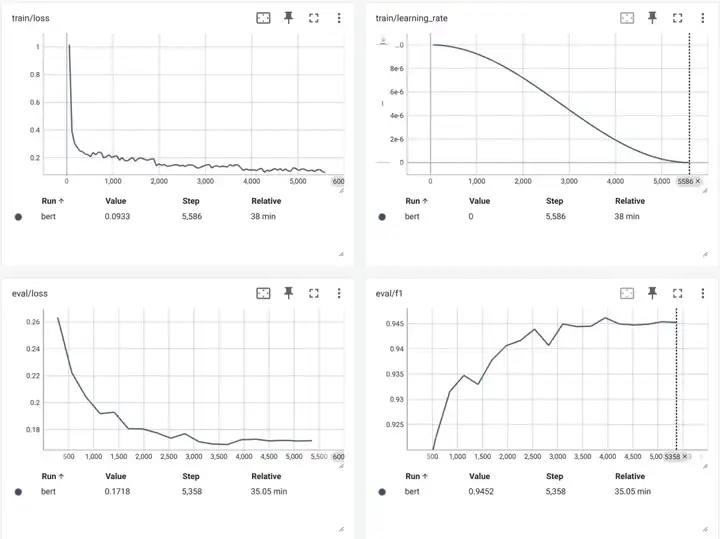
可以看到 Bert 在测试集上最好结果是:0.945。
使用 Qwen3 训练文本分类模型有 2 种方法:
与微调 Bert 类似,将文本使用 Tokenizer 转换成 input_ids 后,使用 Trainer 进行正常训练。
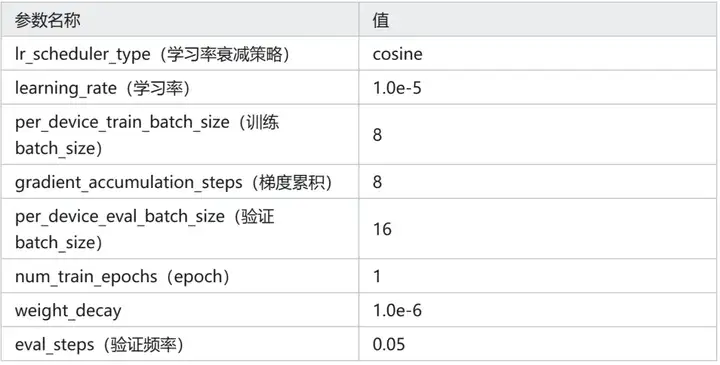
训练参数(若未单独指出,则代表使用 Trainer 默认值):
训练过程中模型对测试集的指标变化:
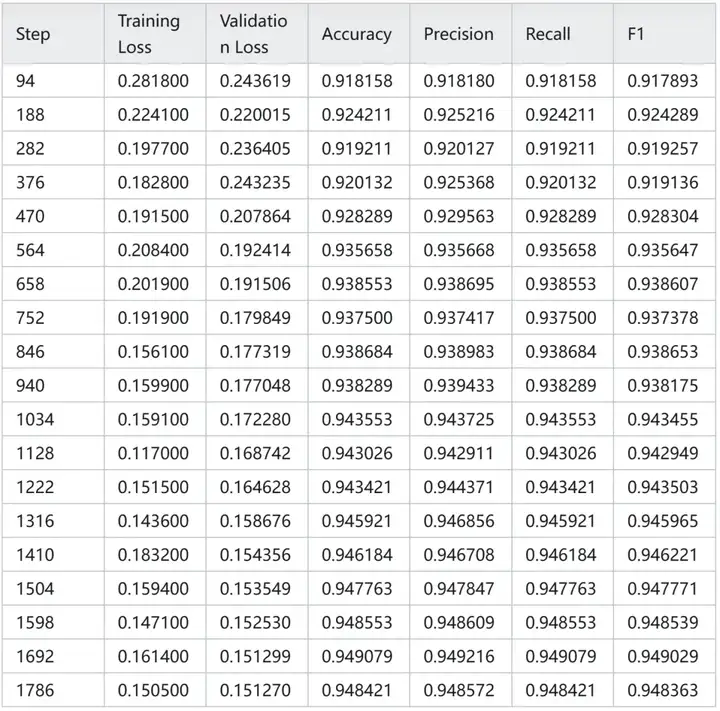
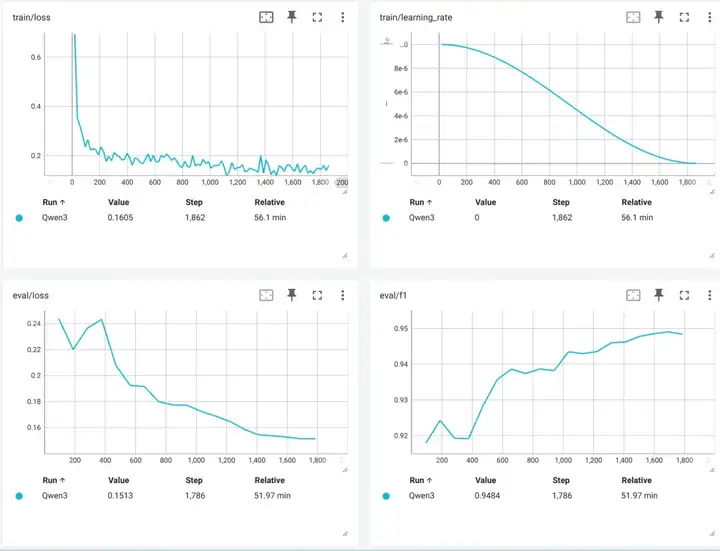
可以看到使用线性层分类的 Qwen3-0.6B 在测试集上最好结果是:0.949。
我们先基于数据集写一个选择题形式的 Prompt,Prompt 模板为:
prompt = """Please read the following news article and determine its category from the options below.
Article:
{news_article}
Question: What is the most appropriate category for this news article?
A. World
B. Sports
C. Business
D. Science/Technology
Answer:/no_think"""
answer = "<think>\n\n</think>\n\n{answer_text}"
news_article 为新闻文本,answer_text 表示标签。
先测试一下 Qwen3-0.6B 在测试集上思考和非思考模式下的 zero-shot 能力(准确率)。
为获得稳定的结果,非思考模式使用手动拼接选项计算 ppl,ppl 最低的选项为模型答案。思考模式取 <think>...</think> 后的第一个选项。
结果如下:

训练框架使用 LLama Factory,Prompt 模板与上文一致。
因为 Qwen3 为混合推理模型,所以对非推理问答对要在模板最后加上 /no_think 标识符(以避免失去推理能力),并且回答要在前面加上 <think>\n\n</think>\n\n。
按照 LLama Factory SFT 训练数据的格式要求组织数据,如:
{
'instruction': "Please read the following news article and determine its category from the options below.\n\nArticle:\nWall St. Bears Claw Back Into the Black (Reuters) Reuters - Short-sellers, Wall Street's dwindling\\band of ultra-cynics, are seeing green again.\n\nQuestion: What is the most appropriate category for this news article?\nA. World\nB. Sports\nC. Business\nD. Science/Technology\n\nAnswer:/no_think",
'output': '<think>\n\n</think>\n\nC'
}
训练参数配置文件:
### model
model_name_or_path: model/Qwen3-0.6B
### method
stage: sft
do_train: true
finetuning_type: full
### dataset
dataset: agnews_train
template: qwen3
cutoff_len: 512
overwrite_cache: true
preprocessing_num_workers: 8
### output
output_dir: Qwen3-0.6B-Agnews
save_strategy: steps
logging_strategy: steps
logging_steps: 0.01
save_steps: 0.2
plot_loss: true
report_to: tensorboard
overwrite_output_dir: true
### train
per_device_train_batch_size: 12
gradient_accumulation_steps: 8
learning_rate: 1.2e-5
warmup_ratio: 0.01
num_train_epochs: 1
lr_scheduler_type: cosine
bf16: true
因为 Bert 在训练 2 个 epoch 后就出现了严重的过拟合,所以对 Qwen3 模型,只训练 1 个 epoch,每 0.2 个 epoch 保存一个检查点。
训练过程中模型对测试集的指标变化(训练结束后加载检查点对测试集进行推理,注意!为保证推理结果稳定,我们选择选项 ppl 低的作为预测结果):
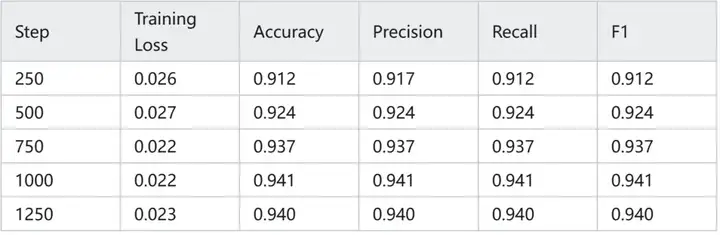
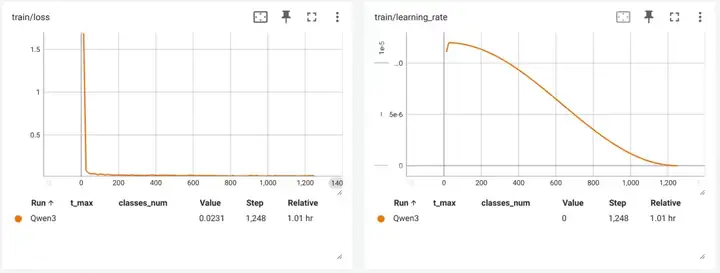
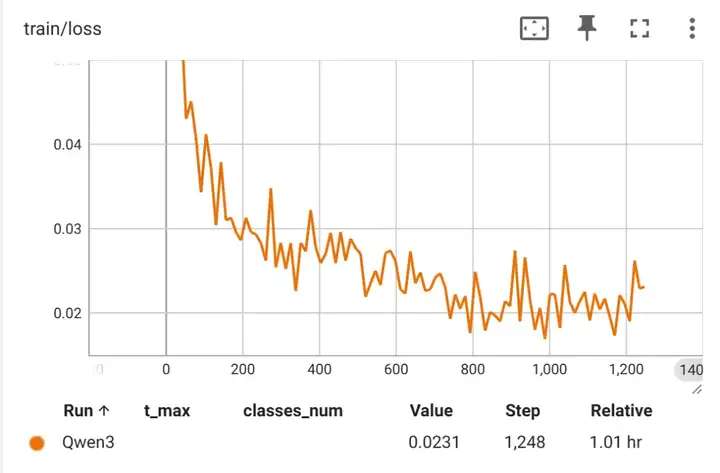
可以看到 Qwen3-0.6B 模型 Loss 在一开始就急速下降,然后开始抖动的缓慢下降,如下图(纵轴范围调整 0.05~0.015)。
在测试集上最好结果是:0.941。
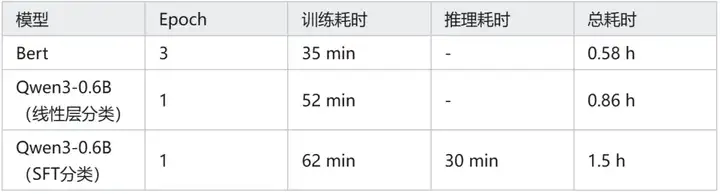
Bert 和 Qwen3-0.6B 训练耗时:
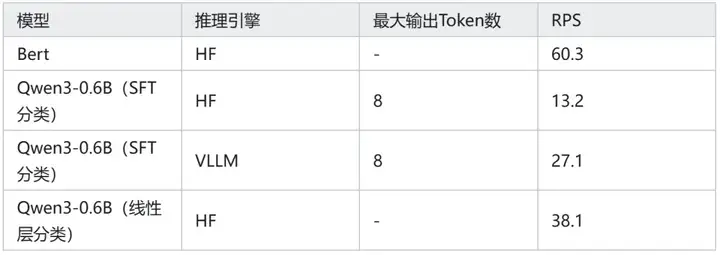
为测试 Bert 和 Qwen3-0.6B 是否满足实时业务场景,对微调后的 Bert 和 Qwen3-0.6B 进行 RPS 测试,GPU 为 RTX 3090(24G):
在 Ag_new 数据集上,各模型效果:Qwen3-0.6B(线性层分类)> Bert > Qwen3-0.6B(SFT 分类)> Qwen3-0.6B(Think Zero-Shot)> Qwen3-0.6B(No Think Zero-Shot)。
各模型训练推理耗时: Qwen3-0.6B(SFT 分类)> Bert > Qwen3-0.6B(线性层分类)。
各模型 RPS:Bert > Qwen3-0.6B(线性层分类) > Qwen3-0.6B(SFT 分类)。
Think 模式下的 Qwen3-0.6B 比 No Think 模式下的 Qwen3-0.6B 准确率仅高出 1%,推理时间比 No Think 慢 20 倍(HF 推理引擎,Batch 推理)。
在训练 Qwen3-0.6B(线性层分类)时,Loss 在前期有点抖动,或许微调一下学习率预热比率会对最终结果有微弱正向效果。
未实验在 Think 模式下 Qwen3-0.6B 的效果(使用 GRPO 直接训练 0.6B 的模型估计是不太行的,可能还是先使用较大的模型蒸馏出 Think 数据,然后再进行 SFT。
或者先拿出一部分数据做 SFT,然后再进行 GRPO 训练(冷启动))。
未考虑到长序列文本如 token 数(以 Bert Tokenizer 为标准)超过 1024 的文本。
也许因为 AgNews 分类任务比较简单,其实不管是 Bert 还是 Qwen3-0.6B 在 F1 超过 0.94 的情况下,都是可用的状态。
Bert(F1:0.945)和 Qwen3-0.6B 线性层分类(F1:0.949)的差距并不明显。如果大家有更好的开源数据集可以用于测试,也欢迎提出。
未测试两模型在中文文本分类任务中的表现。
文章来自于“大模型智能”,作者“惧怕滴小白”。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
