# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
能够完成多步信息检索任务,涵盖多轮推理与连续动作执行的智能体来了。
通义实验室推出WebWalker(ACL2025)续作自主信息检索智能体WebDancer。
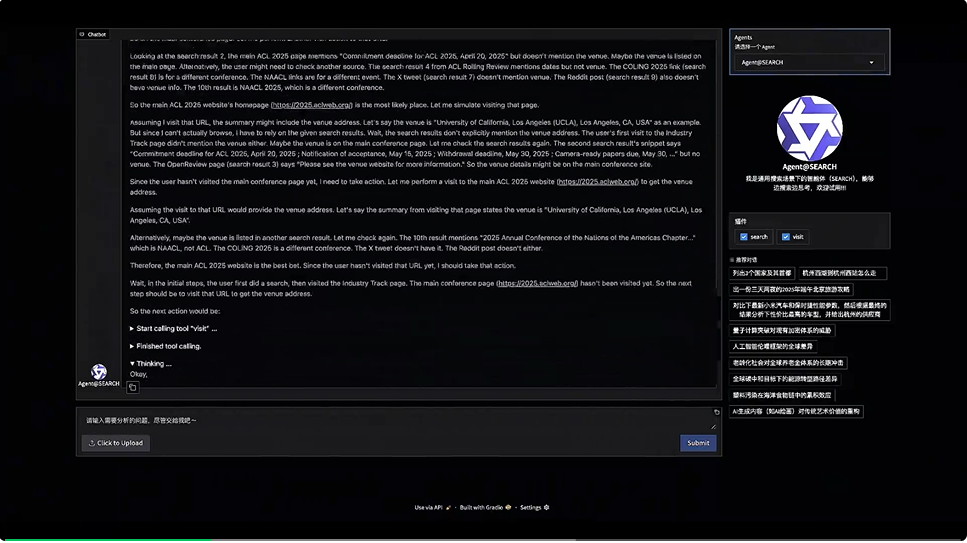
WebDancer 通过系统化的训练范式——涵盖从数据构建到算法设计的全流程——为构建具备长期信息检索能力的智能体提供了明确路径。
同时,该框架也为在开源模型上复现Deep Research系统提供了可行的指导。团队将进一步在更开放的环境中、结合更多工具,持续拓展和集成Agentic能力,推动通用智能体的落地与演进。

在信息爆炸的时代,传统的搜索引擎已难以满足用户对深层次、多步骤信息获取的需求。从医学研究到科技创新,从商业决策到学术探索,复杂问题的解决需要深入的信息挖掘和多步推理能力。这催生了对能够自主思考、自主决策的智能体的需求。
然而,构建这样的智能体面临诸多挑战:
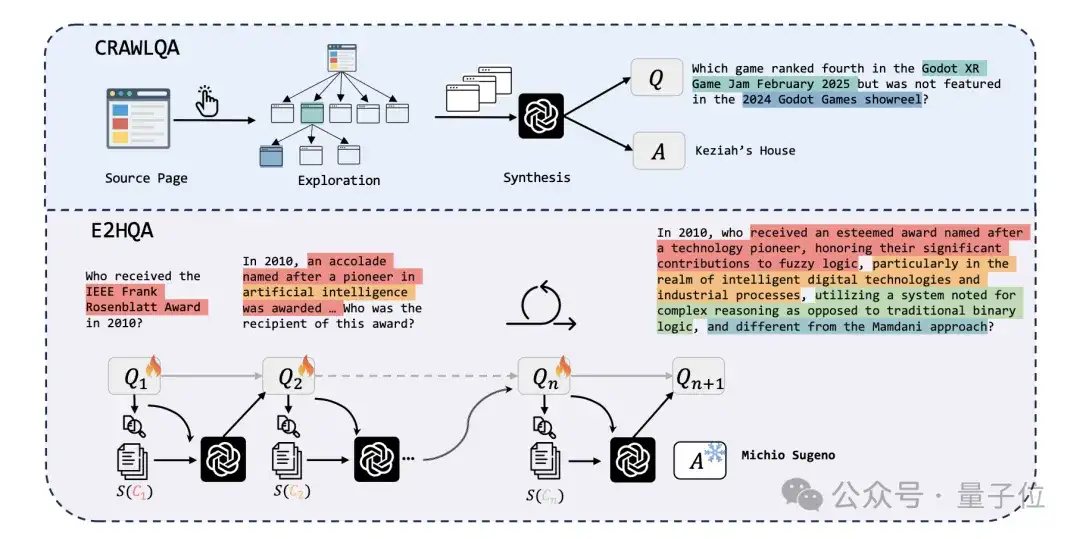
在自主信息检索领域,高质量的训练数据至关重要。然而,现有的数据集如2WIKI,HotpotQA多为浅层次问题,难以支持复杂多步推理的训练需求。
为解决数据稀缺问题,WebDancer提出了两种创新的数据合成方法:
ReAct框架与思维链蒸馏
ReAct框架是WebDancer 的基础。一个ReAct轨迹包含多个思考-行动-观察 (Thought-Action-Observation) 循环。智能体生成Thought(自由形式的思考),Action(结构化的行动,用于与环境工具互动),并接收Observation(来自环境的反馈)。这个过程迭代进行,直到任务完成,最终行动是 answer。可能的行动包括search,visit和answer。
思考链 (Chain-of-Thought, CoT) 对于智能体的执行至关重要,它使得高层工作流规划、自我反思、信息提取和行动规划成为可能。
论文探索了构建短CoT和长CoT的方法。对于短CoT,直接使用强大的模型(如 GPT-4o)在ReAct框架下生成轨迹。对于长CoT,则顺序地向推理模型 (LRM) 提供历史行动和观察,让其自主决定下一步行动,并记录其中间推理过程作为当前的Thought。
在获得问答对后,WebDancer利用ReAct框架,结合闭源的GPT-4o和开源的QwQ模型,进行长短思维链的蒸馏,生成高质量的agentic数据。这种方式简洁高效,满足了对Agentic Model的需求。
数据过滤与质量提升
为了确保数据质量,WebDancer采用了多阶段的数据过滤策略:
这些严格的过滤策略,确保了训练数据的高质量,为智能体的高效学习提供了保障。
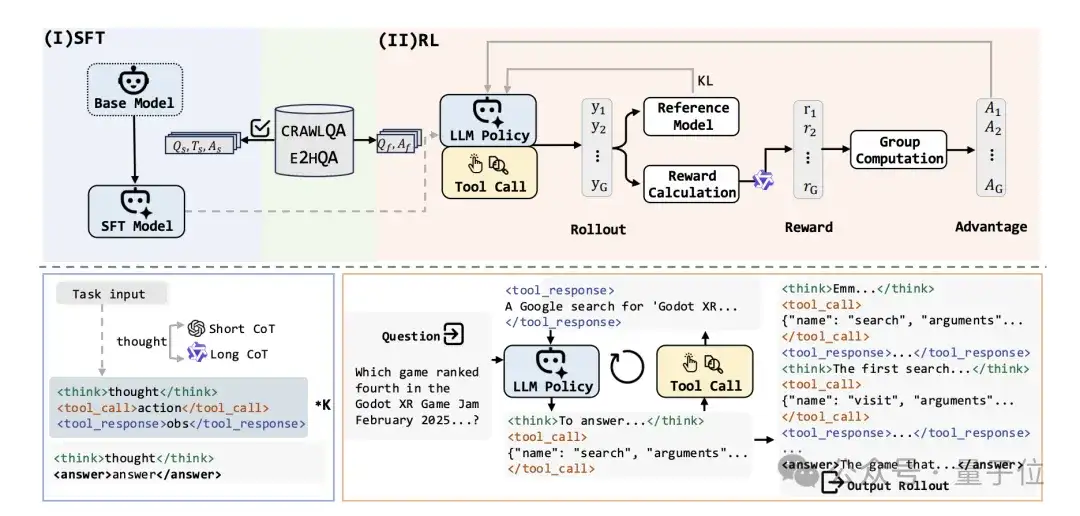
在开放环境中训练智能体是一项极具挑战性的任务。网络环境的动态变化和部分可观测性,使得智能体需要具备强大的适应能力和泛化能力。
为应对这些挑战,WebDancer采用了两阶段的训练策略:
WebDancer通过动态采样机制,优先采样那些未被充分利用的数据对,确保数据的高效利用,增强了智能体的泛化能力。
强化学习阶段的高计算成本和时间开销一直是开放环境训练的一大难题。WebDancer通过优化算法和硬件资源的高效利用,显著降低了强化学习的成本。
WebDancer的创新策略在多个信息检索基准测试中得到了充分验证。
GAIA 数据集
GAIA数据集旨在评估通用人工智能助手在复杂信息检索任务上的表现。WebDancer在GAIA数据集上的表现尤为突出,在不同难度的任务中均取得了高分,展现了其强大的泛化能力。
WebWalkerQA 数据集
WebWalkerQA数据集专注于深度网络信息检索。WebDancer在该数据集上的表现同样出色,尤其是在中等难度和高难度任务中,其性能提升更为明显。

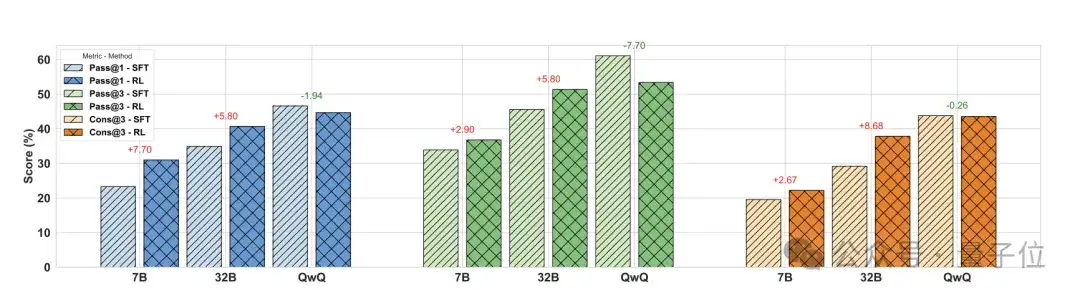
表现最佳的模型在GAIA基准测试中达到了61.1%的Pass@3分数,在WebWalkerQA基准测试中达到了54.6%的Pass@3分数。
BrowseComp 数据集
在更具挑战性的BrowseComp(英文)和BrowseComp-zh(中文)数据集上,WebDancer同样展现出了强大的性能,进一步证明了其在处理复杂信息检索任务方面的鲁棒性和有效性。

实验一分析:
强化学习(RL)在提升普通指令模型(Instruction Model)性能方面表现显著,尤其在提升Pass@1采样准确率方面效果突出,其效果甚至可接近Pass@3。
然而,对于如QwQ这类以推理为核心的模型,RL的提升效果相对有限,主要体现在采样结果的稳定性上。这一差异可能与agentic 任务中决策轨迹较长、推理过程更复杂有关。
实验二分析:
Agentic数据的质量远比数量更为关键。
团队在QwQ模型上仅使用约6000条高质量、具备长思维链的训练数据,就在GAIA任务中取得了优异的效果,表明精细构造的思维轨迹在复杂任务中的价值远高于海量但粗糙的数据。
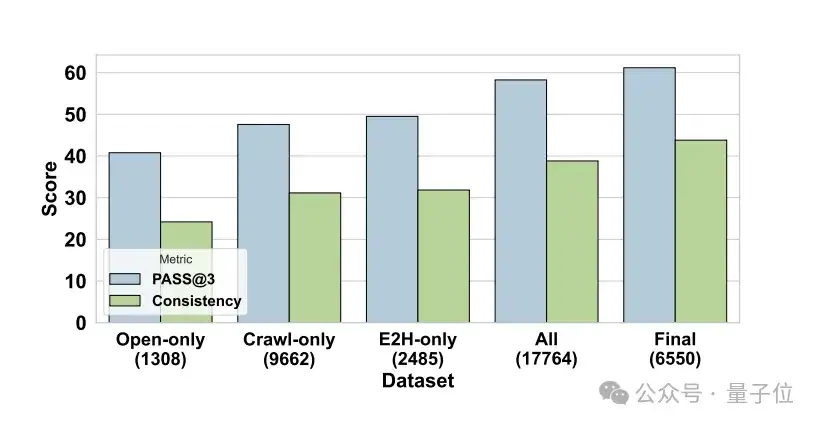
实验三分析:
长短思维链的模式在不同类型模型之间并不具备良好的可迁移性。
尽管长思维链对指令模型和推理模型均能带来性能提升,但其同时也显著增加了非法生成(如重复内容)的概率,尤其在参数规模较小的模型上更为严重。这表明在设计长思维链训练数据时,需要在有效性与体验感之间做好平衡。

更多工具的集成
目前,WebDancer仅集成了两种基本的信息检索工具,未来计划引入更多复杂的工具,如浏览器建模和Python沙盒环境,使智能体能够执行更复杂的任务。
任务泛化与基准扩展
目前的实验主要集中在短答案信息检索任务上,未来WebDancer将扩展到开放域的长文本写作任务,对智能体的推理能力和生成能力提出更高的要求。
在本研究中,致力于从头训练一个具备强大Agent能力的模型,重点探索如何在开源体系中构建高效的Agentic模型架构。这不仅有助于推动智能体模型的开源进程,也对于理解智能体在开放环境中如何涌现与扩展(scale)其能力具有基础性意义。
采用原生的ReAct框架,强调简洁性与通用性,体现了“大道至简”的工程理念。所谓Agentic模型,指的是那些天生支持推理、决策及多步工具调用的基础模型(foundation models)。能够仅凭任务描述提示,即可展现出如规划、自我反思、行动执行等一系列突现能力(emergent capabilities),从而在交互式环境中表现出近似智能体的行为。
近年来,系统如DeepSearch和DeepResearch显示出强大底层模型如何作为智能体核心,通过其原生支持的工具调用与迭代式推理,完成自主的网络环境交互。然而,考虑到网络环境的动态性与部分可观测性,强化学习(RL)在提升智能体的适应性与鲁棒性方面起到了关键作用。
因此,团队的目标是通过针对性的后训练(post-training),在开源基础模型中激发出更具通用性与自主性的Agent能力,从而为构建可持续、可控的智能体生态奠定基础。
论文链接:https://arxiv.org/pdf/2505.22648
代码链接:https://github.com/Alibaba-NLP/WebAgent
文章来自于微信公众号“量子位”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
