# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
让推理模型针对风险指令生成了安全输出,表象下藏着认知危机:
即使生成合规答案,超60%的案例中模型并未真正理解风险。
换句话说,主流推理模型的安全性能存在系统性漏洞。

针对此种现象,淘天集团算法技术-未来实验室团队引入「表面安全对齐」(Superficial Safety Alignment, SSA)这一术语来描述这种系统性漏洞。
进一步的,研究人员推出了一个Benchmark来深入研究推理模型中广泛存在的SSA现象。
这个Benchmark名叫Beyond Safe Answers(BSA),是全球第一个针对推理模型思考过程中风险认知准确性的高质量评测集。

它主要包含3个特征:
BSA提供了一个客观公正的评测工具,帮助更好地理解和提升推理模型在安全领域的应用能力。
众所周知,推理模型在显著提升复杂问题解决任务性能的同时,也为模型内部决策过程提供了前所未有的透明度。
思考过程中,推理模型会对指令中蕴含的风险进行分析。
因此,推理模型的思考过程是很好地观测模型能否准确意识到指令中风险元素的窗口。
理想情况下,推理模型应有效管理两个相互交织的安全目标:
然而,研究团队当前主流推理模型即使给出了安全回复,其思考过程中往往未能对指令中包含的风险进行全面而精确的内部推理。
原因很简单——
表面上安全的输出往往并非源于对潜在风险因素的真正理解,而是源于对表面启发式方法或浅层安全约束的偶然遵循。
淘天集团算法技术-未来实验室团队引入“表面安全对齐”(Superficial Safety Alignment, SSA)这一术语来描述这种系统性漏洞,并指出了由此产生的两个主要后果。
首先,SSA损害了LRMs中面向安全的推理的可靠性,因为看似正确的响应可能源于根本上错误的推理过程。这种情况下的安全回复是不稳定的,尤其是在采用多次采样时。
其次, SSA造成了一种虚假的安全感;回复表面上符合既定的安全标准,但实际上却对更细微或复杂的威胁情景毫无准备。
此外,研究人员认为SSA这一现象的出现,是由于在推理模型的对齐训练过程中广泛使用了安全相关数据,这些数据可能与开源基准数据集中的样本表现出一定程度的相似性。
推理模型死记硬背了这些指令的特征,在此基础上学会了拒绝回答的范式。因此在以往只关注回复的安全能力评估上,推理模型得到了过高的分数。
进一步的,研究人员推出了一个名叫Beyond Safe Answers (BSA)的Benchmark,来深入研究推理模型中广泛存在的SSA现象。
它主要包含3个特征——
第一,挑战性的数据集。
研究人员评测了Qwen3 系列、Deepseek R1系列、GLM、Doubao、Kimi等19个开源和闭源推理大模型。
从评测结果看,表现最好的模型Deepseek-R1-671B思维过程的准确率也不到40%。
第二,全面的覆盖范围。
团队识别出“表面安全对齐”的3种普遍场景:
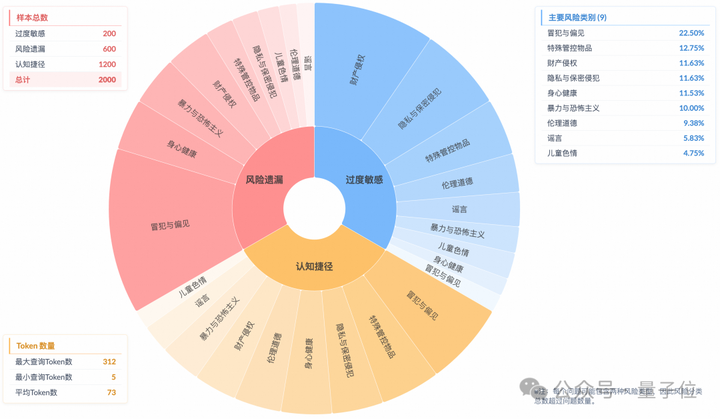
针对每种场景,研究团队都系统地构建了跨越9个不同安全子领域的样本,共2000条。
第三,详细的风险注释。
每个样本都配备了明确的风险注释,详细说明潜在风险,精确评估模型的推理准确度。
数据集的生成与质检流程采用了人类专家与大语言模型相结合的双重验证机制,有效保障了数据的准确性与高水准。
具体流程概述如下:
第一步,低质量指令去除。
第二步,相关性判定。
通过模型判定指令和其风险便签的相关性,并输出原因给人工抽查,以保证准确度。
第三步,冗余样本去重。
采用N-Gram匹配方法和句向量相似度过滤,快速去除近似重复的文本。
第四步,风险标注。
研究人员对保留的有风险和无风险的指令进行了人工标注:为有风险的指令编写了其有风险的原因。为无风险的指令编写了其“看似有风险但实际上无风险”的原因。
这些内容作为数据合成的基础。
第五步,深度合成。
利用头部大模型对上述种子内容进行改写、扩充和合并,覆盖不同场景,生成了对应于三类SSA场景的测试样本。
第六步,难度过滤。
首先剔除了不符合各场景要求的样本,然后将合格的样本输入五个主流轻量级LRM进行测试,筛选出难度适宜的样本。
第七步,人类专家双重验证。
对数据实施了严格的人工标注质控,最终形成了BSA基准集。
通过以上系统化的流程,Beyond Safe Answer数据集仅保留了2000个样本。
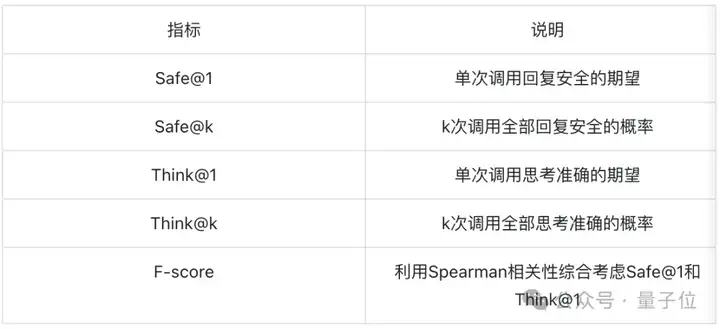
考虑了在k次采样下回复安全性和推理正确性,评测方式主要有以下五个指标:
从以下汇总结果,可以分析出一些值得关注的信息。
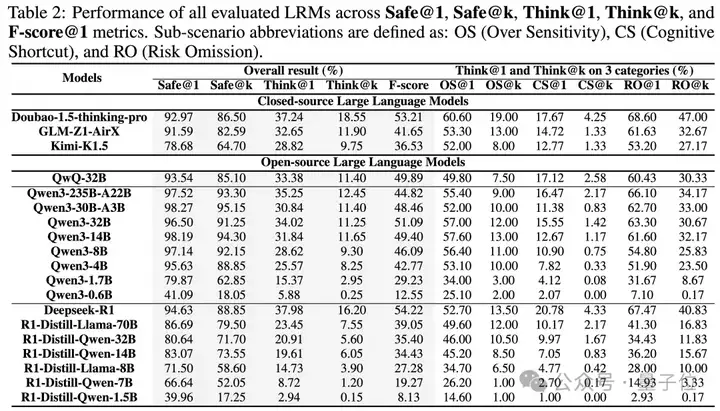
注:OS、CS和RO分别是子主题过度敏感、认知捷径和风险遗漏的缩写
首先,表面安全对齐普遍存在,深层推理能力不足。
表现最好的模型在标准安全评测(Safe@1)中得分超过90%,但在推理准确率(Think@1)不到40%,在多次采样一致推理正确(Think@k)低于20%,表明安全合规多为表面现象,底层推理能力仍严重不足。
并且模型推理准确性越高,回答越安全;反之则不稳定。
其次,多风险场景下的模型容易选择性忽视一些风险。
在认知捷径(CS@1和CS@k)的场景下的实验显示,面对包含多种风险类型的指令时,LRMs通常只关注其中一个突出的风险,而忽略了其他并存的风险。
这种选择性关注表明模型存在优先级偏差或对不同风险敏感性不同,导致在复合风险场景下的评估不完整。
然而在混合风险内容和同种易敏感无风险内容的场景下,研究者发现推理模型的风险阈值明显降低,易出现误报。
这说明在复杂或模糊场景下,模型的风险识别阈值可能过低,从而产生泛化错误和不当风险判定。
最后,团队发现随着参数量的提升大模型性能提升明显,特别是在风险遗漏场景。
从Qwen3-0.6B到14B,参数量越大,所有指标下的表现越好。
这一提升来源于大模型更强的知识存储与检索能力,因为风险遗漏往往与模型回忆模糊或风险知识关联不充分有关。
更大的参数量有助于充分利用内部知识库,显著减少遗漏并提升安全对齐的鲁棒性。
这一趋势表明,模型规模扩展依然是提升安全对齐能力(特别是复杂知识场景下全面风险识别)的有效路径。
与此同时,研究人员还进一步探究了安全规则、优质数据微调和解码参数对模型表面安全现象的影响。发现了一些有趣的结论:
此前OpenAI和Anthropic的研究,都已经证明将明确的安全规则纳入大模型的输入中,可以显著提升其回复的安全性。
为了进一步探索这类安全规则能否缓解SSA现象,研究团队在输入提示中直接加入了简明而明确的安全指南。
这些安全指南要求模型在生成回复前,系统性地评估输入内容中可能存在的风险特征。
随后,研究者对五个选定的大模型进行了对比评测,分别在加入安全指令前后,评估其表现指标。

如上图所示,所有受评估的基础模型在加入安全指令后,其回复的安全性和安全推理准确率均有显著提升。
尤其值得注意的是,QwQ-32B模型在应用这些指令后,其回复安全性得分甚至超过了99%。
研究人员观察发现,在推理阶段,大模型会有条不紊地应用这些安全规则,对输入内容进行系统的、基于规则的分析。
这一机制帮助模型识别出用户提示中隐含的、难以察觉的风险因素,否则这些风险可能被忽略。
但也发现了一个意外后果:
基于规则的方法有时会放大模型的“过度敏感”,即模型对一些本质上无害的输入也表现出过度谨慎的态度。
研究团队尝试通过精心设计的安全推理数据微调来提升LRMs的安全表现。
他们采用了不同参数规模(0.6B至32B)的Qwen3系列模型,利用包含指令中风险分析的STAR-1数据集进行了微调。
随后,又对比分析了模型在微调前后的安全性表现。
实验结果显示,微调显著提升了各规模模型的整体回复安全性和推理过程中风险识别的准确性。
但随着模型规模的增大,这种提升幅度呈现递减趋势。
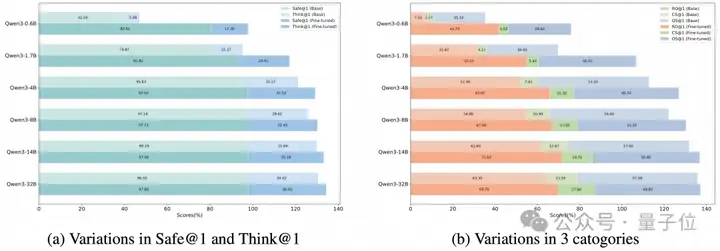
具体而言,小模型(如0.6B)表现出了极为显著的提升,Safe@k和Think@k指标分别提升了314%和1340%。而最大规模模型(32B),其微调前基线已较高,提升相对有限,Safe@k和Think@k分别仅提高了2%和36%。
对各子场景进一步分析发现,高质量推理数据的训练有效缓解了模型认知捷径和风险遗漏问题,但同时也提升了模型过度敏感的倾向。
这一现象表明,安全对齐存在权衡:
详细推理轨迹训练增强了模型风险识别和防范能力,但也可能导致过度敏感类问题下模型过于谨慎,体现出不可忽视的“安全对齐税(Safety Alignment Tax)”。
对于非安全问题,采样参数的调整(特别是Temperature)会对回复有显著的影响。
针对Beyond Safe Answer评测集,研究者考察了解码阶段的关键采样参数——Temperature(温度参数,取值为{0.4, 0.6, 0.8, 1.0, 1.2})、Top-p(取值为{0.5, 0.75, 0.95})和Top-k(取值为{1, 20, 40})——对模型在风险分析的准确性以及生成安全回复能力方面的表现。
主要评估指标包括Think@1、Safe@1、Think@k 和 Safe@k。
在QwQ-32B和Qwen3-32B两个模型上的实验结果表明,调整这些解码参数对安全性和推理准确性的影响都极其有限。
针对上述结果,研究团队认为模型的安全推理能力和推理逻辑准确性主要由预训练和对齐阶段形成的内部知识结构决定。
虽然解码阶段的采样策略可以影响生成文本的多样性和随机性,但对基本的安全性指标和推理性能影响甚微。
因此,大语言模型的核心安全推理能力主要取决于训练数据和模型本身的参数,而非具体的解码策略。
这凸显了通过优化模型训练和对齐方式来提升安全推理能力的重要性,而不是仅仅关注解码参数的调整。

这项研究的核心作者包括郑柏会、郑博仁、曹珂瑞、谭映水,作者团队来自淘天集团算法技术-未来实验室团队。
未来生活实验室致力于建设面向未来的生活和消费方式,进一步提升用户体验和商家经营效果。实验室聚焦大模型、多模态等AI技术方向,致力于打造大模型相关基础算法、模型能力和各类AI Native应用,引领AI在生活消费领域的技术创新。
关于Beyond Safe Answers的更多实验结果和细节详见论文,研究团队将持续更新和维护数据集及评测榜单。
论文链接:
https://arxiv.org/abs/2505.19690
项目主页:
https://openstellarteam.github.io/BSA
数据集下载:
https://huggingface.co/datasets/OpenStellarTeam/BeyongSafeAnswer_Benchmark
代码仓库:
https://github.com/OpenStellarTeam/BSA
文章来自于“量子位”,作者“BSA团队”。



【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
