# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在企业系统和科学研究中普遍存在、结构复杂的关系型数据库(Relational DataBase, RDB)场景中,基础模型的探索仍处于早期阶段。
这是因为RDB中的多表交互和异质特征,使传统通用大模型在此类结构化环境下难以直接发挥效能。
基于此,北京大学张牧涵团队联合亚马逊云科技共同提出了Griffin:一个具有开创性的、以图为中心的RDB基础模型。
Griffin将RDB视为动态异质图进行建模与推理,通过在超过1.5亿行的表格数据上进行预训练和监督微调,构建了一个具备可迁移性与强泛化能力的基础模型,
相关成果已被国际顶级会议ICML 2025正式接收。

关系数据库通过明确的模式(Schema)定义数据结构,广泛服务于金融、电商、科研、物流、政府信息系统等关键领域,是现代信息社会的核心数字基础设施。
根据市场预测,到2028年全球数据库管理系统(DBMS)市场将超过1330亿美元。
然而,RDB智能建模所面临的挑战极为复杂,集中体现在以下三方面:
数据以多表形式存储,并通过主键外键等约束关系构成复杂的图结构,传统单表范式难以捕捉全局上下文。
表内字段涵盖文本、数值、类别、时间序列等多种类型,信息表现形态各异,模型需具备统一表征能力。
表内外存在丰富的显性与隐性逻辑关系,对模型的关系理解和推理能力构成巨大挑战。
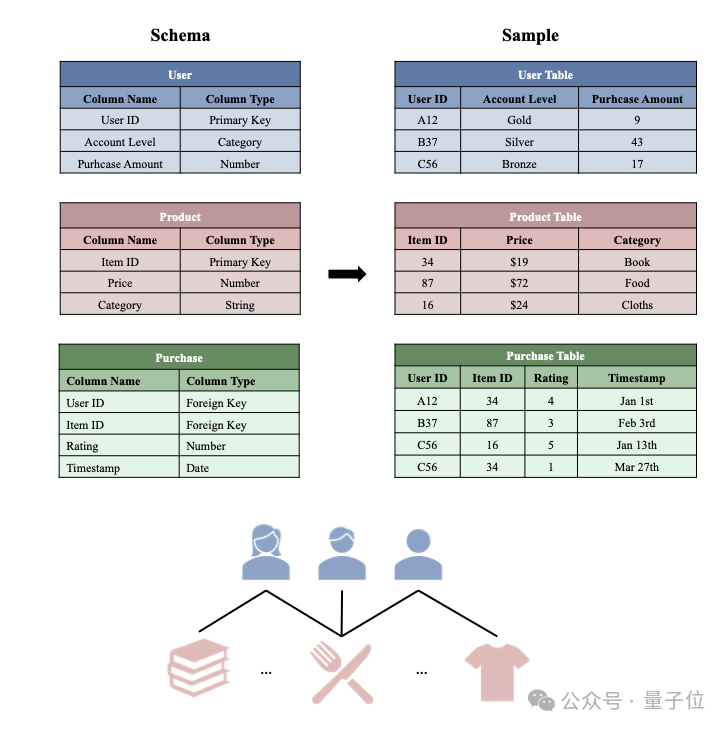
上图展示了一个典型的RDB,绿色的Purchase Table记录了交易数据(每一行包括用户ID、购买的商品ID、用户对商品的评分、以及购买日期)。
而每一行又可通过User ID这一外键链接到User Table里的对应行,或通过Item ID这一外键链接到Product Table里的对应行,来获取用户或商品的特定信息。
相比普通表格(单表)数据,RDB往往具有非常复杂的表间关系以及丰富的表内语义信息,对建模和基础模型训练提出了挑战。
同时,社区长期缺乏能真实反映生产场景的标准化基准。
诸如4DBInfer(arXiv:2404.18209)等数据集正缓慢填补空白,为新模型(包括Griffin)提供了统一的评测土壤。
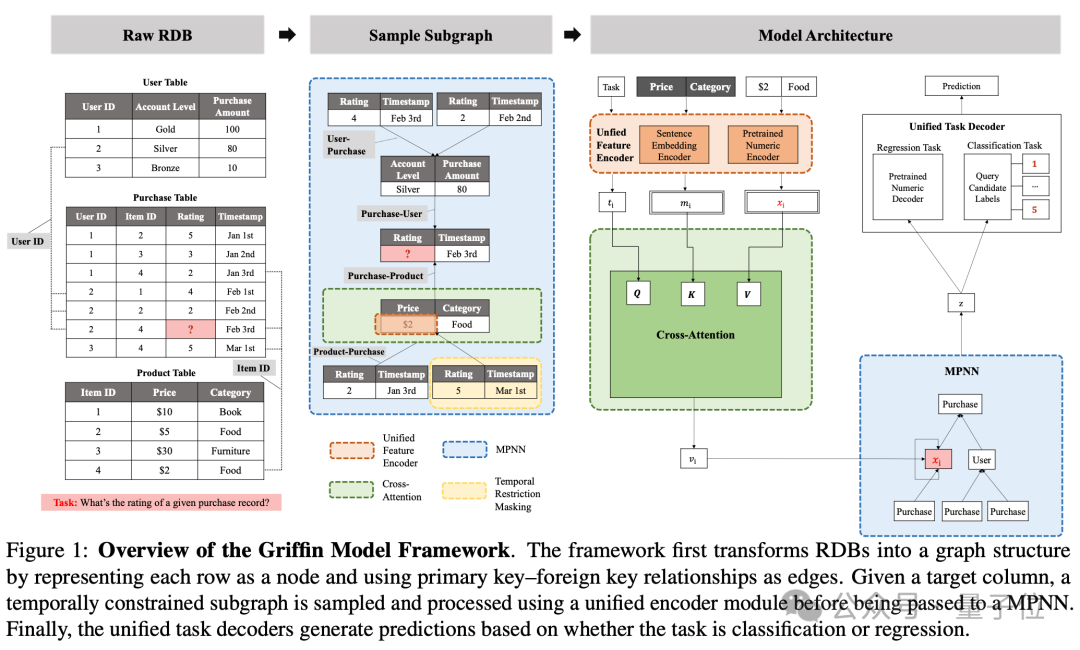
Griffin的核心思想是将关系型数据库整体抽象为时序异质图,再在此图上进行统一的编码、消息传递和解码,以此捕捉跨表、跨时间的深层依赖。
具体来说,它的创新设计可以拆解为以下几点:
RDB的数据建模:结构化图表示与时序感知
首先,Griffin把每张数据表中的一行记录映射为图中的一个节点,而主键-外键(PK-FK)约束被建模为带类型的有向边。
这样,原本分散在多张表中的记录就组成了一张异质图,其节点/边类型天然反映了模式信息。
为了避免未来信息泄漏并符合生产预测任务的因果约束,模型在训练和推理时会围绕目标节点采样“局部时序子图”:仅纳入时间戳早于目标节点的邻域。
该采样流程借鉴了4DBInfer等基准的成熟做法,可在保证效率的同时显式注入时间方向。
统一数据编码器:异构信息的规范化表征
RDB中既包含文本/类别字段,也有数值、时间序列等多模态特征。Griffin设计了一套统一编码机制,把不同类型转换为同一语义空间中的向量:
编码后必须能够无损地解码回原始浮点值,重构误差被最小化后这两个组件参数即被冻结。
同时,根据当前预测目标列名生成的任务描述会在后续所有层次参与注意力计算,指导模型聚焦目标。
经过上述步骤,原始多态信息被规范化为一组高语义的向量,为后续图消息传递奠定基础。
先进MPNN架构:深度关系推理网络
统一编码后的图被送入Griffin定制的Message Passing Neural Network (MPNN),其核心由两个互补模块构成:
交叉注意力(Cross-Attention)列内聚合:对每个节点,模型利用当前节点嵌入和任务嵌入生成查询向量,与列元数据和列特征进行交互,
动态评估不同列对当前任务的重要性并加权聚合。该设计天然满足列置换不变性,且可处理列数可变的表。
层级聚合(Hierarchical Aggregation)跨表推理:在消息传递的每一层,先对同一边类型的邻居消息做均值聚合,再在不同边类型间做最大池化。
这种两阶段层级策略提升了模型在处理具有复杂拓扑结构和多变邻居数量的表间关联时的稳定性。
通过多层迭代,MPNN能够捕获从近邻到远程的复合依赖,为下游任务提供信息丰富的节点表征。
统一任务解码器:多任务输出的一体化方案
MPNN输出的节点向量随后进入统一解码器,使Griffin能够在不改动架构的前提下同时处理多种预测任务。
分类任务:把候选类别标签本身的文本嵌入当作可学习的动态分类头,与节点向量做内积得到概率分布,能够拓展到可变类比数量的任务。
回归任务:直接将节点向量输入预训练DEC,反解得到最终的预测数值。
Griffin通过“自监督预训练→联合监督微调→下游任务微调”的三级管线,逐步注入从通用表格语义到特定RDB任务知识的能力层次。
第一阶段:补全预训练(Completion Pretraining)
Griffin首先在海量且多样化的单表数据集上进行自监督学习,任务形式类似“完形填空”。
模型根据一行数据中已知列信息来预测被遮蔽单元的嵌入表示,并最小化预测嵌入与真实嵌入间的余弦距离,从而建立对表格结构与语义的基础理解。
第二阶段:联合监督微调(Joint Supervised Fine-Tuning, SFT)
在完成自监督预训练后,Griffin使用单表任务或RDB任务的数据集进行监督微调,使模型进一步贴合真实场景中的预测需求与数据特性。
第三阶段:下游任务微调(Downstream Task Fine-Tuning)
最后,经过预训练和SFT的Griffin会针对具体下游RDB基准任务进行精细化微调,以在特定应用场景中取得最佳性能。
为全面评估各训练阶段对模型性能的具体贡献,对Griffin的三个关键变体进行深入分析:
Griffin-unpretrained(仅采用Griffin的基础架构,未经任何预训练)、
Griffin-pretrained(仅进行单表预训练及单表SFT)以及Griffin-RDB-SFT(经历完整的三阶段训练流程)。
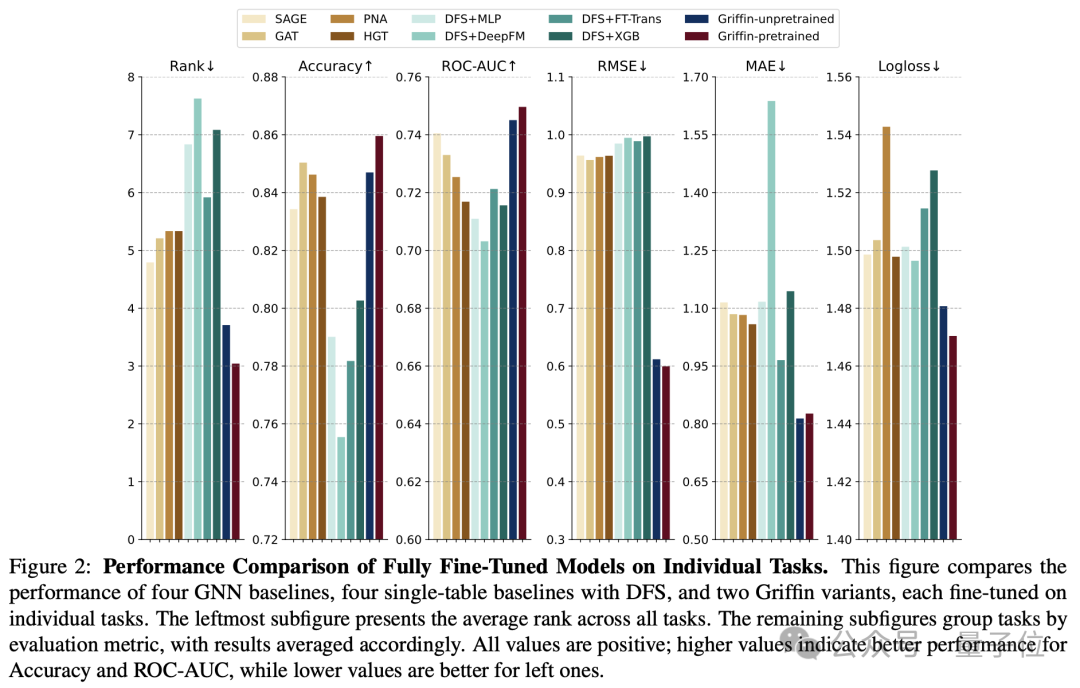
上图比较了四个 GNN 基线模型、四个使用 DFS 的单表基线模型以及两个 Griffin 变体的性能,每个模型均在单个任务上进行了微调。
最左侧的子图展示了所有任务上的平均排名,其余子图按评估指标对任务进行分组,结果相应地进行了平均。
通过系统实验验证了Griffin在架构设计和预训练策略上的有效性,发现Griffin在多个RDB基准测试(如4DBInfer和RelBench)中表现优异,
并进一步分析了其在少样本场景下的跨任务迁移能力与数据领域间关系的影响。
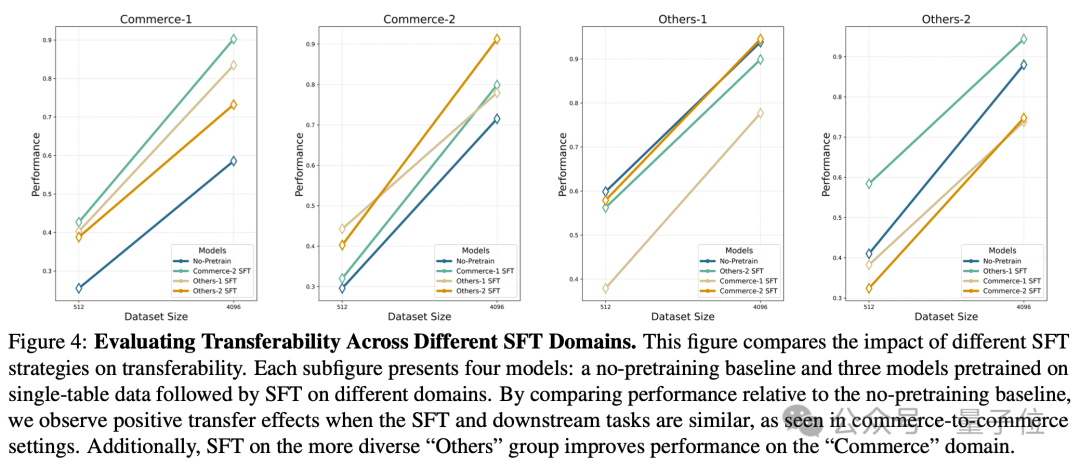
Griffin的核心优势可归纳为以下三点:
1.强大的基础架构性能
即便完全未预训练(Griffin-unpretrained),凭借统一编码、交叉注意力和层级化MPNN等设计,
模型在各下游RDB任务微调后的表现仍优于GNN基线方法及结合深度特征合成(DFS)的传统单表模型,体现了架构本身的先进性。
2.单表预训练的普适性增益
仅在大规模、多样化单表数据上完成预训练的Griffin-pretrained,相较未预训练版本取得性能提升,
验证单表场景中学习到的知识可迁移至复杂的RDB任务,增强模型泛化能力。
3.RDB-SFT驱动的迁移
当进一步在针对性RDB数据上进行监督微调(Griffin-RDB-SFT)后,模型在一定情况下展现出跨任务迁移能力,
尤其在小样本场景下更为突出,取决于以下2个因素:
同样能有效提升模型性能。
论文链接:https://arxiv.org/abs/2505.05568
代码链接:https://github.com/yanxwb/griffin
文章来自于微信公众号 “量子位”,作者 :Griffin团队




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
