# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI+生物学的关键瓶颈——数据,迎来重大进展!
近日,Basecamp Research宣布推出生物序列数据库BaseData™,包含超过9.2万亿个Token的基因组数据以及98亿条经过严格筛选与校对的蛋白质序列,其中许多来自公司所发现的超过100万个新物种。
负责人表示,这是迄今为止规模最大、增长最快的生物序列数据库,也是首个专为基础模型(Foundation Model)训练而构建的数据库,采集自26个国家及地区的120多个站点。
Basecamp Research成立于2019年,专注于利用人工智能和全球生物多样性数据来解决生命科学领域的重大挑战,通过构建专有知识图谱来发现和设计新型蛋白质及生物系统,以开发新的药物、生物材料或优化工业酶,已与强生、宝洁、英伟达等公司建立合作。

其发表的预印本论文中分享了这项成果的更多细节,公司计划向感兴趣的生命科学研究人员提供早期访问权限。
史上最强生物数据库,专为AI打造
能够捕捉整个生物领域通用表征的基础模型有望彻底改变人类理解、编程和改造生物系统的能力。然而,最新研究表明相关模型的发展速度正在放缓。
造成这一情况的主要原因是缺乏足够多样化且经过整理的生物数据,当前生物领域的基础模型(如AlphaFold、ESM)严重依赖公共数据库进行训练,但这些数据库存在明显局限性。
例如,68%的SRA数据仅来自5个物种,且70%的数据集中在10个国家,反映出严重的采样偏差。更严峻的是,UniRef50等核心数据库的年增长率已降至10%以下,规模长期停滞不前。
数据增长的受限与多样性的匮乏已经成为阻碍当下生命科学研究的关键瓶颈。
为此,研究团队推出BaseData™,这个专为基础模型训练而打造的生物序列数据库拥有多项优势:
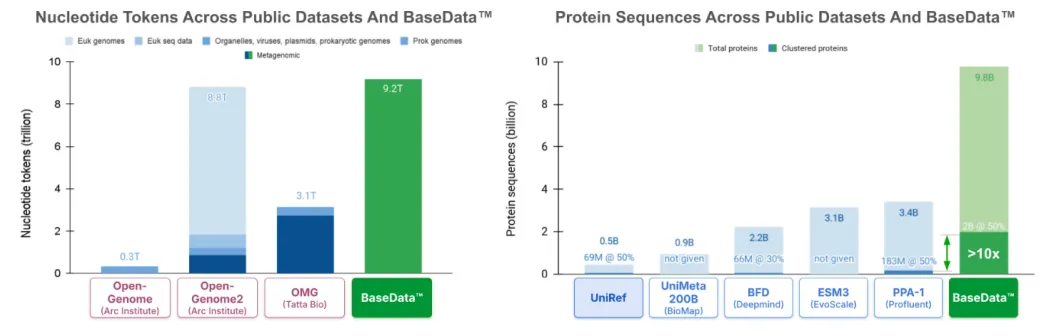
此外,BaseData™从底层架构就为AI训练进行了专门优化,其数据组织形式显著降低了冗余度,经过50%相似度聚类后仍保留2.0亿个非冗余蛋白簇,是传统数据库的10倍以上。
数据库还特别注重保留完整的生物学背景信息,如基因共表达网络、水平基因转移事件等,这些高阶生物关系对于提升模型的泛化能力至关重要。

图:BaseData™的全球采样网络
实践证明,在相同参数规模下,使用BaseData™训练的模型在ProteinGym等基准测试中展现出更优越的零样本预测性能,特别是在处理远缘物种和新型蛋白家族时优势明显。
牛津博士创业,打造生物版GPT
Basecamp Research成立于2019年,创始人为两位牛津大学博士:合成生物学家Glen Gowers和生物医学工程师Oliver Vince。
公司的核心理念——“超越已知生物学”,源于两人一次共同的极地探险经历。2018 年,两位创始人在冰岛的瓦特纳冰川完成了人类历史上首次在极地环境中完全离网的DNA测序。

图:Glen Gowers(左)和Oliver Vince(右)
这次探险不仅验证了在偏远地区进行复杂生物实验的可能性,更让他们深刻认识到地球上仍有大量未被探索的生物多样性,蕴藏着巨大的未知生物信息和潜力。
受到这次探险的启发,Basecamp Research于2019 年在伦敦成立,迄今已累计获得8500万美元融资,投资者包括一些知名企业高管,如罗氏公司副董事长André Hoffmann、飞利浦公司董事长兼帝斯曼前首席执行官Feike Sijbesma和联合利华前首席执行官Paul Polman。
两位创始人认为,要训练出真正强大的生物学GPT,首先需要一个庞大、多样且高质量的生物数据基础,公开可用的生物数据库远不足以捕捉自然界真正的生物复杂性。
Basecamp Research的愿景是构建一个前所未有的生物蛋白质序列知识图谱,通过从地球上最极端、生物多样性最丰富的环境中收集样本,来发现和设计全新的蛋白质及生物系统。
为了构建BaseData™,公司采取了一种根本不同的方法。该方案建立在完全独立、专门设计和可扩展的数据供应链基础上,通过结构化的商业伙伴关系获取生物多样性,这些伙伴关系建立在公平的双边准入和惠益分享协议基础上,覆盖26个国家和自治区域的120多个实地站点。
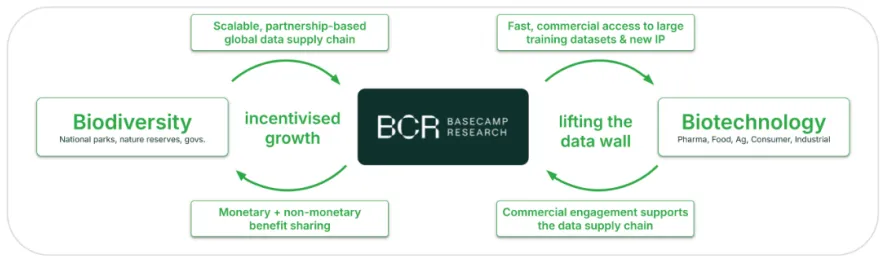
图:Basecamp Research围绕生物数据建立了一种新的经济模式
所有数据采集均通过预先谈判的商业使用授权协议完成,并建立了透明的利益分配机制,通过嵌入式的数据溯源系统,能够精确追踪每个序列的商业化使用情况,并按照使用量比例向数据来源方分配收益。
这种模式不仅解决了传统公共数据库的法律模糊性问题,更创造了可持续的生物数据经济生态。截至2024年底,BaseData™已向19个国家的52个受益方支付商业化分成。
模型层面,Basecamp Research开发了名为BaseFold™的深度学习模型,用于预测蛋白质的3D 结构,特别是针对大型和复杂的蛋白质。
公司表示BaseFold™ 在准确性方面优于DeepMind的AlphaFold2,尤其是在处理公共数据集中代表性不足的蛋白质时,其准确性可达AlphaFold2的六倍。
Basecamp Research已经与英伟达建立合作关系,包括将BaseFold™ 适配英伟达BioNeMo平台,以及加入英伟达Inception计划,以获得最新开发工具、GPU计算资源以及专业技术支持。
此外,Basecamp Research还与巴塞罗那分子生物学研究所Ferruz实验室合作,推出了ZymCTRL,这是首个基于文本的酶设计生成式AI模型。
ZymCTRL的突破性在于,它是一个端到端的蛋白质大型语言模型 (LLM),用户只需通过简单的文本输入(例如,酶的识别码或期望的催化活性),即可从头生成全新的酶序列。

令人印象深刻的是,ZymCTRL 能够生成与训练数据中已知序列仅有30% 相似度,但仍具有功能活性的酶序列,这表明模型不仅仅是复制现有知识,而是具备真正的创造能力,能够探索广阔的蛋白质序列空间。
ZymCTRL已被证明能够成功设计出用于工业实践的酶,例如用于冷水洗涤的高效清洁酶,Basecamp Research还将ZymCTRL开源,以促进全球研究人员的合作和应用。
文章来自微信公众号 “ 智药局 ”,作者 子任


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
