# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在 AI 工具风靡开发圈之前,一批经验丰富的资深程序员,对它们始终保持警惕。这些人,包括 Flask 作者 Armin Ronacher(17 年开发经验)、PSPDFKit 创始人 Peter Steinberger(17 年 iOS 和 macOS 开发经验),以及 Django 联合作者 Simon Willison(25 年编程经验)。然而,就在今年,他们的看法都发生了根本转变。
Armin 在过去几个月中彻底改观。他曾对 AI 工具“不敢授权”,如今却愿意将工程主导交给编程代理,自己转而去泡咖啡或陪孩子玩耍。“如今显而易见,我们正经历一场翻天覆地的变革。”

Peter 作为拥有 17 年经验的 iOS 和 Mac 开发者,近期重新开始捡起了编码工作。2021 年,PSPDFKit 获得 1 亿欧元融资时,他出售了自己在公司的全部股份,此后就只是偶尔写点东西。“现在,我们正处于技术发展的一个令人难以置信的十字路口。”“这些工具彻底改变了软件构建的方式。”“Agentic AI 工具是有史以来最大的一次变革。”
Simon 曾是 Django 的创始人,目前是一名独立软件工程师。对于当前 AI 工具在软件开发中的实际能力,他是这样评价的:“现在,编码代理(Coding Agents)真的能用了:你可以把一个 LLM 放进循环中,让它运行编译器、测试框架、linter 和其他工具,给它一个目标,然后看着它完成整个流程。在过去六个月,模型的进步已经从‘好玩的玩具演示’,跃升到了日常可用的生产工具。”
在这个背景下,像 Copilot、Cursor 和 Claude Code 这样的智能 IDE 无疑是促成大家看法转变的关键因素之一。与此同时,我们也注意到了一种新的产品类别正在兴起:Factory AI,它比Copilot、Cursor走得更远,声称目标是摆脱传统 IDE 的形态。
Factory AI 由理论物理学博士 Matan Grinberg 和曾任 Hugging Face 及微软数据科学家的 Eno Reyes 共同创立的公司打造。
Grinberg 指出,如今 AI 被视为超越以往所有平台变革的强大力量,但 Copilot 和 Cursor 依然是传统的 IDE。“尽管大家普遍认为软件开发模式会改变,但目前主流的做法仍是‘在原有流程上附加 AI’:开发者在 IDE 中编码 15 年,现在只是把 AI 塞进 IDE,成了 AI IDE。换句话说,真正的转型尚未发生。”
因此,Factory AI 的核心理念是重新思考软件工程,不仅仅是写代码,而是关注整个端到端的软件开发流程。
Factory 基于 Grinberg 所称的“Droid ”构建:一个引擎,用于提取和处理公司工程系统数据以构建知识库;以及一个算法,用于从知识库中提取洞察以解决各种工程问题。Droid 的第三个核心组件 Reflection Engine,充当 Factory 所利用的第三方 AI 模型的过滤器。
在过去的两年里,这家公司一直 只面向企业提供服务,据说在企业领域取得了显著成功,其客户涵盖了从“种子期”到“上市”等不同发展阶段的企业。一个月前,Factory AI 首次向公众开放,并获得了 MongoDB CEO 的高度赞扬:

有些人将其与 Devin 对比,但两者也存在不同的地方:Devin 宣扬的是“取代所有工程师”,但 Factory 更强调的是“增强”工程团队的能力。
Matan Grinberg 在最近的一次访谈中也体现出他对这个行业的独特见解。他认为 AI 的到来将使程序员的工作重心转向更高层次,并且“可解决的问题总量”也会因此变得更多。未来那些具备系统性思维、深入理解底层原理并善于利用 AI 工具的程序员,将更具价值。
我们翻译了 Matan 的访谈,来了解 Factory 的思想。一些亮点摘录如下:
Matthew Berman:Factory 是一个和传统 IDE 非常不同的产品。它本质上就不是一个传统意义上的 IDE。这可能也反映了你对当前 AI 与软件工程结合现状,以及未来走向的看法。那我们直接切入正题:你为什么要做 Factory?能先说说背后的故事吗?
Matan Grinberg: 好的,我可以从为什么开始做 Factory 说起。在做 Factory 之前,我当了十年理论物理学家,主要研究弦论。当时我执着地坚持这条路,并不是因为我觉得它最适合我,而是因为它很难——我对难的事情总是有种莫名的吸引力。后来我去了伯克利,开始攻读博士学位。
在伯克利期间,我开始接触一些 AI 的研究生课程,接触到了当时还叫“程序合成”(program synthesis)的领域——现在我们称之为“代码生成”。我一头栽进去,很快就彻底转向了 AI 研究。那是 2022 年初。代码生成让我着迷,是因为我从理论物理和弦论转过来,已经被训练成习惯关注那些最基础、最普遍的事物。而代码或软件开发,在整个 AI 领域里扮演了极其普适的基础角色。
模型在编码方面的能力,往往直接关联到它在其他下游任务中的表现。不管是写诗,还是回答学术问题,模型的编码能力越强,它在其他任务中的能力也越强。这种核心能力吸引了很多数学家和物理学家进入这一领域,这也是我当初被吸引的原因。
至于你刚才提到的“为什么关注 IDE 之外的新交互模式”这个问题,我想先引用一句我们在 Factory 很认同的话——亨利·福特曾说过:“如果我问人们他们想要什么,他们会说更快的马。”
我们认为软件工程的未来也是如此。现在的开发模式基本都建立在 IDE 上,这种范式已经存在二十多年了,开发者都很熟悉,形成了非常固定的使用习惯。而大家普遍也认同,软件开发在未来五年会变得非常不同。问题在于:我们现在是一个开发者写每一行代码的世界,而未来我们可能会进入一个开发者几乎不再写代码的世界。
有一种思路是:从当前“写满代码”的世界逐步演进到“零代码”的理想状态。但我们的观点是——这就像是试图从马演化出汽车。但历史上并不是这样发生的。我们是从第一性原理出发,直接造出了汽车。我们现在的做法就像是在重新思考“交通”这个问题一样,重构软件工程的方式。
我们把这种模式叫做 agent-native 软件开发,与传统的 IDE 编程方式有本质的不同。
传统开发者的思维是:“我怎么才能更快地完成这个任务?”于是会使用自动补全、单元测试等等工具来加快效率。但 agent-native 的模式,是思维方式发生转变:面对一个大任务,开发者要思考“我怎么把它拆解成离散、可验证、可并行执行的小步骤”,然后把这些步骤交给智能体去并行完成。
这和串行地更快工作是两种完全不同的提速方式。一个任务如果能并行拆成四个部分去做,其速度提升远超在原有流程中微优化。
Matthew Berman:我在使用 AI 产品时,最让我惊艳的时刻,往往是当我意识到可以“并行”处理任务的时候。第一次有这种感受,是我看到 OpenAI 的 operator,可以启动一个需要数分钟甚至几十分钟完成的长任务,然后再启动第二个任务。我意识到:我手里有多个 agent 同时处理我原本要一个个完成的任务,真的是非常震撼。我确实非常相信这种多智能体并行执行任务的未来愿景。
Matthew Berman:你刚刚提到一个很有意思的观点:代码生成的能力是模型其他强大能力的“上游”。那我就想问一下——你有没有看到苹果这个周末刚发布的那篇论文?你笑了,我猜你看过。这篇被大家广泛传播的论文探讨了“推理的错觉”——它指出语言模型可能并没有真正地在用自然语言进行推理。他们设置了一些谜题,当复杂度上升后,模型就无法解决这些谜题了。
但这篇论文没有提及的一点是:这些模型可以用代码解决这些谜题,而且在任意复杂度下都能做到。这让我特别想问你:你认为语言模型用代码进行逻辑推理、解谜题的能力,算是“智能”吗?你怎么看这篇论文?
Matan Grinberg:—坦白说,我没有认真读那篇论文,只看了摘要。没来得及通读全文。说实话这篇论文的发表时机,和苹果现在在 AI 市场的处境联系起来还挺有意思的。
至于“写代码算不算智能”?我觉得我们现在所处的时代特别有意思的一点是,整个“智能”这个概念本身正面临质疑。每当一个大模型做成某件事,我们总会本能地想:“哦,那不算智能,那只是记忆”或者“那只是训练数据的复现”。我们总会说它只是插值,不是真正的推理。
但这其实很难定义。我至今也没看到过一个真正清晰、统一的“智能”定义,能够明确划分“这算智能”、“那不算”。
我觉得有意思的一个方向是 ARC 奖(ARC Prize)那边在做的研究。他们强调泛化能力、模式匹配等等。这方面他们做了不少不错的探索。有一点非常明确:模型在训练数据中接触越多的任务类型,它在这些任务上的表现就越好。
当然,这也会引发一种质疑:“它只是做熟了,才会。”但人类也是这样。人类能泛化得更好一些,从一种题型推广到另一种题型,但本质上,我们也需要训练。
Sarah Guo 最近说了句话我挺认同:当人们谈论 AGI 或智能时,其实他们潜意识里说的是“意识”(consciousness),这两个概念经常在无意识中混淆。
回到你问的问题,我的看法是:要解决某些编码问题,确实需要智能。所以按这个标准来说,这些模型当然具备智能。至于它们有没有超越训练数据的“广义智能”?答案是否定的。但这正是各大实验室现在努力攻克的方向。
Matthew Berman:我也相信,相比于自然语言,模型通过写代码的方式,展现出的泛化能力要更强。我想回到“并行处理”这个话题上来。过去几十年里,人类工程师团队协同工作时,通常不会在同一段代码上一起开发——否则就会产生大量冲突。而 Git 就是为了解决这些冲突而生的。那么,智能体在并行协作时的方式和人类有何不同?
Matan Grinberg: 好问题。我认为这也涉及一个关键问题:当软件开发智能体越来越强大时,人类在其中扮演什么角色?
如果是两个完全独立的任务,比如开发功能一和功能二,那当然可以并行。但如你所说,如果它们要修改相同的核心代码区域,那就会出现合并冲突。
我认为人类工程师在未来将扮演一个非常重要的角色:比如在处理“功能一”的时候,如何最优地将任务拆解成子问题,而这些子问题必须是可以并行处理的。
那人类需要什么样的能力才能做到这种高效拆解?答案是:系统性思维(systems thinking)。
真正优秀的工程师从来都不是那种记住每门语言所有细节的人,而是具备系统性思维、能在各种限制条件下做出合理推断的人。现在我们拥有了一种全新的交互模式和开发方式:不再是“思考完怎么做,然后自己动手实现”,而是尽快地整理出一个完整的“任务包”,包含可执行的步骤,以及验证这些步骤是否完成的标准,然后交给智能体去实现。
Matthew Berman:你提到系统性思维,我很认同。我经常被问到一个问题,你可能也会遇到:现在还值得学编程吗?我问过 GitHub CEO 这个问题。我自己有两个年幼的孩子。对我来说,学会编程是我一生中最重要的技能之一,它让我可以把脑海中的想法变成现实,而不依赖他人。*
几年前,如果你问我,我会毫不犹豫地告诉我的孩子:“编程是最重要的技能,必须学。”
但之后有一段时间我产生了动摇。不过让我再次把这个问题拉回到系统性思维。除了学编程之外, 系统性思维本身也是我学到的最重要能力之一。即使未来大多数代码都由智能体来写,这种思维方式依然对整个工作流程至关重要,甚至放在整个“人生技能”范畴下也一样重要。你怎么看?
Matan Grinberg: 我完全同意,甚至想说个稍微更“激进”的观点:对现在还在读高中或大学的年轻人来说,他们学的是计算机、数学、物理还是生物,其实并没那么重要。
重要的是:他们进入的这些领域,问题空间都非常庞大、信息密度极高,还有几百年的学术历史——现实中没人有时间把所有细节都学一遍。
所以关键在于:你是否具备一种能力——进入一个复杂领域后,迅速搞清楚核心基础是什么,哪些细节是你必须弄懂的,哪些可以暂时模糊理解,但依然能继续往前推进。
我可能有点偏见,因为我自己花了十年时间研究物理。一个比喻是这样的:每次我站在黑板前写下一个公式时,我不会每次都重新推导相关定理——那样效率太低。但在我人生中的某个阶段,我确实做过这些推导,而且如果有人现在让我推一次,我也能推出来。
我觉得这和软件开发很相似。在大学的计算机课程中,我们通常会从底层逐步学到高级语言。现实中你可能永远不会用到机器码,但理解它是有帮助的。
这同样回到了系统性思维的问题:你得了解你所工作的“整个技术栈”的结构。就像物理学家和数学家也会使用计算器、用各种他人推导好的定理,他们不会每次都重头再证明一遍,但他们曾经学过这些推导,知道如何从头做一次。
如果你忽略了这些基本功,哪怕现在有智能体帮你写代码,最终也可能吃亏。因为你没有那个“在信息大山中摸索出路径”的经验和能力。
而这正是你说的那个关键技能:面对一个复杂领域,知道该深入掌握什么、又能对哪些东西保持模糊但足够用的理解,并继续往前推进。
Matthew Berman:我听你描述的其实是“抽象层”的概念。而放回软件工程的上下文里,今天很多人都在问:未来我们会成为 orchestrator(编排者)吗?我们是不是主要职责就是检查智能体的工作?无论是哪种角色,了解底层原理仍然是必须的。哪怕你不亲自去写每个算法、不从头实现每个函数,你也需要有基本的判断力才能检查智能体做的是否正确,或者调度它们正确地协作。
Matthew Berman:过去两年里,软件工程的变化速度真的令人震惊。让我意外的是:AI 对软件工程的影响居然是最大的(尽管现在看好像也不算意外了)。而且它的变化速度还在持续加快。你刚刚描述了未来几年可能出现的“智能体编排”形态,以及从 IDE 向更高抽象层的迁移。那么你觉得 5 年后、10 年后的世界会变成什么样?
Matan Grinberg: 当然我知道这类预测不可能准确,但我还是很想听听你的愿景。
我完全同意你说的“预测很难”这个前提。预测 5 年后的事情本来就极具不确定性。
2020 年的时候,可能有极少数人能预见我们今天的样子,但真的非常少。因为每一代模型的进步都会产生指数级连锁反应,而这些累积效应会影响未来每一年的节奏。
所以预测时,一个很重要的意识是:人类并不擅长处理“复利”这种非线性思维方式。
这不是我第一个提出来,也不会是最后一个这么说的人。我们习惯用线性方式思考,但科技进展是指数曲线。有一个很棒的梗图我想跟你分享。这来自 Daniel Kokotajlo 的博客。这张图非常形象地说明了我们在处理非线性增长时的无能。
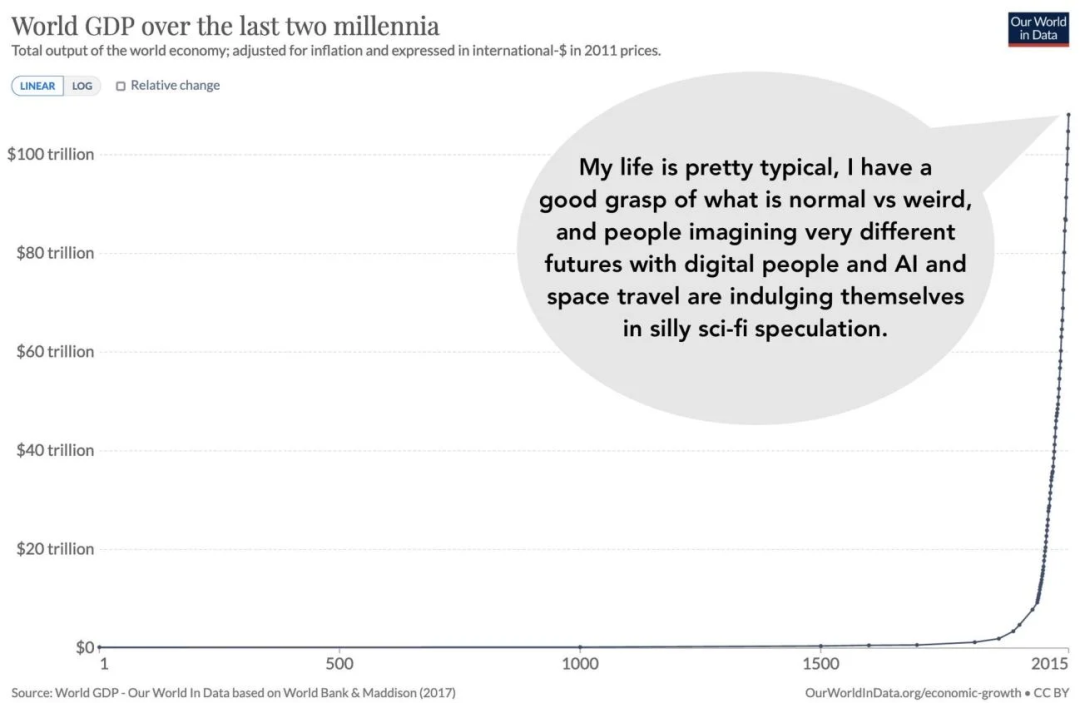
比如,全球 GDP 增长就是一种非常夸张的指数曲线。但在 2010 到 2020 这十年里,大多数人并没有觉得进展有多“疯狂”。但其实那段时间 GDP 曲线几乎是垂直往上的。
所以当我们试图思考未来 5~10 年时,我们其实很难做出有高置信度的判断。
我唯一能说的是,在思考未来时,我会尽量回归初衷。我们搞软件工程的初衷并不是为了写代码本身。我们不是为了代码而写代码,而是为了造出我们想造的东西。
我们写程序,是为了借助计算机这种比人类快得多的“计算机器”完成我们的目标。计算只是手段,不是目的。真正的目标,是用它来构建连接世界的工具、解决现实的问题。我们想要实现的是有意义的终点。比如,我们想要模拟某些科学现象,以便研发新药;又比如,我们只是想让打车这件事变得更高效,不必再等上三十分钟才叫到出租车。
这些才是我们的目的,而手段是软件,因为我们想用机器来完成这些事,而不是仅依靠人工系统。为了与机器交流,我们不得不学习一种非常精确的语言——编程语言。后来我们慢慢让这种语言变得越来越抽象,因为直接用比特与机器交流实在是太低效了。用更高层次的抽象语言,效率反而更高。所以我认为这个趋势还会持续下去。
过去,我们必须深入学习编程,才能知道如何与机器协作。但现在我们正开始“抽离”出来,重新关注我们真正想实现的目标。
所以回到你刚才的问题——我认为在未来的 5 到 10 年里,我们能以更快速度解决更多问题。比如,以前一个问题可能需要 1000 名工程师和 10 年时间去建立一家公司来解决它。但未来你可能只需要 10 个人,就能把一个想法变成现实并完成整个闭环。
从这个角度看,好像会出现公司人数下降、不会再有一万人的大公司了。但我认为还有另一个相反方向的力量存在:如果你有 1 万名工程师,而他们每个人都能把任务分派给几百个智能体——那么软件能实现的规模和复杂性也会大大提升。
现在我们都很难想象如何协调一个十万人规模的软件开发组织。但像微软这样的公司正在尝试这么做。虽然它们的效率肯定还存在瓶颈,但如果你把时间放到未来 5~10 年,届时软件系统的复杂性可能远超我们今天的想象。
那会是一个我们几乎无法理解的世界。想象一下“相当于一百万名软件工程师同时工作”的产出规模——这都难以想象。
Matthew Berman:听你讲完,我感觉我们对未来的看法其实非常一致,而且你也非常乐观。
很多人觉得,如果现在一款产品过去需要 1000 名工程师,而将来只需要 10 个,那公司一定会裁掉那 990 个人。但我持反例,甚至持更乐观的态度。因为真正发生的事是——“可解决的问题总量”会急剧扩大。 虽然现在 10 人就能解决一个问题 X,但之后你会有问题 Y、Z、α 等等。那些原本做 X 的工程师可以继续去解决这些新问题——他们只是“被超级加持了”。
所以我不认为最终会是那种“一个人领导一家公司,下面全是 AI 军团”的格局。我不认为未来世界只剩下 10 家公司,每家就一个人 + 一堆智能体。恰恰相反。以前有些“长尾问题”之所以没人解决,不是因为它们不重要,而是 解决它们的“智力成本”不划算——但这一点即将改变。
Matan Grinberg: 确实如此。通常一个问题的“可服务市场规模”(TAM)会决定它能吸引多少工程师和资金来解决。比如某个问题只影响全世界 20 万人,那你就会根据他们的消费能力来判断值不值得投入资源去解决。
以前,也许这种问题只值几百工程师的投入。但现在情况不同了:哪怕某个问题只影响几千人,你也可以投入相当于十万工程师的“智能体产能”去解决它。
我觉得这太酷了。哪怕一个问题只影响 2000 人,我也觉得值得解决——理想世界里,不该有人被遗留,而现在我们可以把这种“计算力”集中起来去解决这些问题。
Matthew Berman: 甚至可能最终把问题细化到只影响一个人的程度。而那时,软件的开发成本也会降到如此之低,以至于哪怕是“为一个人量身定制”的解决方案都能盈利。这真的非常有趣。当然,我们刚才讨论的,是那种极致长尾的问题。未来也还有另一类——我们现在甚至想象不出的庞大问题。这些也许是几十年以后的事。但假如我们未来走向星辰大海,一定会产生一些巨大的软件问题,是全人类的工程师都解决不了的。
但在那个未来,每一位人类工程师都会拥有属于自己的“虚拟工程师军团”。所以也许,到时候这些原本无法解决的问题就变得可解了。
Matan Grinberg: 完全同意。我特别喜欢你刚才说的那种描述方式:这不是为了软件工程本身而做软件工程,而是每个人有自己的问题——他手上有 AI 工程军团,能用来解决问题。
无论是探索宇宙,还是别的什么,人们总会在路上遇到各种挑战,而他们可以更高效地解决这些问题。这种效率的提升,显然是对整个社会的巨大正向推动。
Matthew Berman:说回 Factory 产品本身。我最初使用它时,最打动我的是它的“设计”。
不仅是 UI,更是整个使用体验(UX)。它显然不是一个 IDE。所以,谈谈你们的设计理念吧。Factory 的 UI/UX 正在走向什么方向?它如何影响人与产品之间的交互?
Matan Grinberg: 首先,我要大大表扬我们的设计师 Cal——他其实是我亲哥哥。能和他一起工作,真是一种乐趣。我们设计上的几个亮点之一是:Cal 的背景其实是工业设计,他毕业于 RISD(美国最顶尖的艺术院校)。而 Factory 有 22 位世界顶尖的工程师。
我认为我们特别注重在设计时吸收不同视角,哪怕我们做的是给程序员用的工具。很多人会直觉地认为:“这是程序员用的产品,那就让程序员来设计吧,听听他们的意见就行。”比如功能 A 放这儿还是放那儿,大家一起投票决定。但 Cal 作为一个“局外人”,他的设计背景和 UX/UI 视角,其实带来了非常宝贵的价值。
因为我们的目标之一,是摆脱 IDE 的形态。
而市面上最顶尖的程序员过去十几年都一直在使用传统 IDE,所以他们脑子里已经形成了非常深的习惯。反而是 Cal——他从没用过 IDE,所以他根本没有这些“旧习惯”,这就让他能提出一些全新的视角。
这有点像物理学领域也会出现的现象:为什么很多物理学家的“最强突破”都发生在 27 岁左右?因为那时候他们既有足够的专业背景,又没被各种教条和惯性思维束缚住。他们还有勇气和能力去“质疑一切”。
这种心态在我们的设计工作中非常有帮助。
至于产品未来的走向,如我之前所说,我们在尝试构建一辆“车”,而不是在“马车”上反复加速。传统做法是在 IDE 上堆叠更多 AI 功能。但我们的目标是彻底跳出 IDE。
最终理想是,人类开发者不再需要手动去写代码。开发者只需要提供一份清晰的计划——不仅仅是“给我做个仪表盘”这种模糊需求,而是通过设计正确的交互,引导他们提供真正准确、可操作的限制条件和目标定义。这样我们才能真正理解开发者的意图,并尽可能忠实地将其实现。
我们希望能有确定性的方式来验证生成结果。举个稍微有点傻的例子:假设我想做一个蓝色的仪表盘。我对 Factory 说:“嘿,帮我做一个符合 Factory 主题风格的仪表盘。”结果它给我生成了一个粉色的界面——这显然违背了我们现有的设计系统。
我们想要的是,即使 Factory 出现这种偏差,生成了不符合我们预期约束的内容,它也应该具备能力去发现这个问题,然后自动迭代修正,而不是通知我“我搞定了”,然后我点开一看——结果居然是粉色的。然后我还得说:“我们通常是深色模式啊。”
所以,我们正在塑造一种交互模式,让人类开发者可以更清晰地表达他们的约束条件,或者系统能随着使用不断学习这些约束,这样他们就不需要每次都重复说明。
与此同时,在底层的系统层面,我们也在确保检索和代码生成的能力始终保持领先。确保那些执行代码的“droid”(智能代理)能基于运行结果进行迭代,比如某个测试失败了,它能据此修复而不是让人来回手动干预。
我们越能搞定这一点,开发者就越不需要自己手动修改代码——这也是我们走向“Agent-Native”未来的重要一步:人类开发者只需要清晰地定义他们的目标和任务范围,然后把它交给代理去完成。
Matthew Berman:Factory 对企业的代码库理解得非常深。那么,你能不能分享一些幕后内容,比如 Factory 的 droid(智能代理)是如何理解代码、保持模式一致、不做不该做的修改的?Factory 在这些方面有哪些独特的方法?
Matan Grinberg: 我觉得主要有三点关键技术,我们可以一一聊一下:
首先是原生集成。
MCP 服务器确实挺强的,但我觉得它目前有点被过度炒作了。MCP 的优点在于,它能把 IDE 中的信息注入到模型里,但它的缺点也很明显——对于大型代码库或企业环境,它的计算都是临时完成的,这和人类工程师的工作方式非常不同。
人类工程师在处理问题时,并不会“清空记忆”然后重新搜索所有相关内容。通常他们已经对自己的代码库和团队架构有一定的“先验理解”,遇到问题时可以直接想到:“哦,这个跟那块代码有关”,然后快速定位、解决问题。
Factory 采用类似的思路。我们和 GitHub、Slack、Jira、Sentry、Datadog 等工具进行了深度原生集成,并且预先计算了它们之间的关联关系。
比如:某个 Notion 文档里写了一份技术设计方案,它是基于一些客户需求或问题产生的,然后你提交了一个 PR 去实现它,之后 Sentry 报告了这个 PR 引发的故障。现在,如果你要追溯问题来源,我们不需要临时从各个系统中“抓信息”,而是已经知道这些内容的上下文链条。你可以更快、更高质量地排查和修改问题。
所以相比 MCP,Factory 的原生集成方式在大型企业中更节省时间,也更稳定可靠。
Matthew Berman:好的,那我们再聊聊“记忆”这一块。我本来也想问这个,因为像 ChatGPT 的记忆功能就非常重要,它提升了交互质量。那么 Factory 是如何实现记忆机制的?
Matan Grinberg:Factory 的记忆分为多个层级,能让系统逐步“了解你”:
这些记忆会随着使用持续学习和进化,当然,你也可以手动修改或配置这些记忆,不管是组织负责人、团队 leader 还是个人开发者都可以自定义。
第三个关键点是——Factory 可以执行代码。
具体来说,Factory 提供了两种执行模式:
另外,具备真实的代码执行能力,意味着你不再是“写完代码就盲目提交”,而是能够真正运行它、验证它能否编译通过、测试是否成功,以及它是否真的按照你的预期功能去执行。
这与人类工程师的工作方式非常相似。人类不会只是写完代码就提交 PR,觉得“应该能行”。他们会实际运行、检查并确认:“这个代码真的完成了我想要的功能吗?所有测试都通过了吗?”
Matthew Berman:现在 Factory 大大降低了写代码的门槛,让高质量、规模化的代码生产变得容易。这让我在思考:垂直型 SaaS 公司会不会受到冲击?比如以前那些不是技术型的企业,没有富余的工程师团队,也无法自建系统解决内部需求。那么你觉得这些企业是否该采用 Factory,自建一些工具?
Matan Grinberg: 事实上,我们目前最大的一些客户,其核心竞争力也并不是软件开发。比如说我们的一位客户是德国制药巨头拜耳(Bayer),也就是那个做阿司匹林的公司。他们就是我们的用户之一。
他们并不卖软件,但现实情况是,今天的每一家企业,在某种程度上都依赖软件。即便软件不是你直接销售的产品,它对企业提高杠杆效率来说依然至关重要。
如果你现在能让“droid”(智能代理)来帮你分担任务,或者说你之前为了一些旧系统支付了大量费用,但实际上只需要用到其中的一小部分功能——现在你完全可以自己内部搭建一个更符合需求的工具。
或者说,你可以用更少的工程师,更快地发布产品。因为对于那些软件不是核心业务的公司来说,他们手上的工程师本来就不多。那你就更需要给他们配备最前沿、高效的工具。
而且还有“乘数效应”——每位工程师都能有多个智能代理协作,这种一对多的工作方式会极大提高产出。所以我的答案是:是的,非技术公司特别适合使用 Factory。
Matthew Berman:尤其是因为 Factory 的存在,才让那些没有太多开发经验的人,也能真正写出优秀的软件。这一点非常有意义。那我们接着说吧。像 Factory 这样的产品正在把软件开发的成本压缩到接近零。那么,这对垂直型 SaaS 公司意味着什么?
Matan Grinberg: 是的,现在确实是一个非常有意思的时间点。这其实也呼应了你刚刚提到的一个观点:如果 AI 工具能让每个工程师的效率提升 10 倍,那公司是否会因此裁员?
如果世界上不存在竞争,那也许会这样。但现实是——每一家你的竞争对手现在也能让他们的工程师效率提升 10 倍。
所以你当然可以裁员,然后保持当前的生产效率。但如果你的对手没有裁员,反而用这些效率工具让自己变得更强,那他们的整体产出将是你的 100 倍,最终你只会被甩在后面。
这对软件用户来说是好事,因为这意味着——你所用软件的门槛和质量标准将会显著提高。
这其实就像博弈论的经典场景:如果只有你一个人拥有 AI 技术,那你当然可以靠它降本增效。但现实是,大家都有这项技术。这种竞争态势会强制性地抬高“好软件”的标准。
类似的例子还有 90 年代的网站。当时要做出一个漂亮的网站非常难,而现在有了各种低代码工具,几分钟就能搞定炫酷网站。所以现在我们眼里的“好网站”门槛,比以前高了很多——90 年代那种顶尖网站,现在只能算入门水平。
Matthew Berman:最后一个问题,Matan。你觉得大家接下来该关注什么?你们未来 6 个月会做哪些新东西?
Matan Grinberg: 我觉得最值得期待的是,智能代理(agents)会变得更可靠,质量更高,你用更少的提示,它们就能更准确地完成你想要的任务。
现在我们看到,真正沉浸在 “Agent Native” 软件开发方式里的用户,在使用 Factory 时会有一种“魔法般的体验”。但即使在那些拥有上万名开发者的大公司里,仍有很多人对 AI 和 Agent 不感冒。他们可能并没有太强烈的意愿去尝试这些新工具,因为现在确实还需要一些“善意的投入”——你要去写清楚你希望 Agent 做什么,才能让它给你一个好的结果。
但我相信,再过 六个月,哪怕你完全不在乎 AI、依然每天待在你的 Emacs 里、只想按照老方式写代码,只要你肯花一分钟尝试一下 Factory——你就会被惊艳到。
那种提升开发者能力和工作杠杆的方式,会真正让你感受到 empowered,让你愿意拥抱这种新的范式。
参考链接:
https://www.youtube.com/watch?v=sI3D1UY-cV0&t=5s
https://www.youtube.com/watch?v=8gKN29Ea-J8
https://techcrunch.com/2023/11/02/factory-wants-to-use-ai-to-automate-the-software-dev-lifecycle/
文章来自于微信公众号“InfoQ”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
