# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

当前,大语言模型(LLMs)在编程领域的能力受到广泛关注,相关论断在市场中普遍存在,例如 DeepMind 的 AlphaCode 曾宣称达到人类竞技编程选手的水平;OpenAI 的顶尖模型屡屡被报道能通过谷歌高级编程面试,并在 LeetCode 挑战中表现出较高能力。
然而,将这些能力宣称与实际评测结果进行对比时,当前评估体系的深层问题便随之显现:
这些鲜明的对比,共同指向一个核心问题:当前对 LLM 编程能力的评估,往往存在 “宣传与现实的认知鸿沟”。这种差异不仅源于模型能力边界的复杂性,也暴露出现有评估体系的诸多局限性。具体表现为:
为了解决上述这些评估困境、评测出全球顶尖模型真实的编程能力, Meituan-M17团队 推出了更真实、更具区分度的评估基准 OIBench 数据集,并托管于 AGI-Eval 评测社区。基于此数据集,我们对全球 18 个主流大模型的算法编程能力进行了系统评测并量化得分,详细评分榜单如下所示,可以看到全球顶尖大模型距离以往所宣称的编程能力还存在很大差距,哪怕是最高分的 o4-mini-high 也仅仅只有 36.35 分,距离人类竞赛选手的水平还相差甚远,甚至很多模型只有个位数的得分。
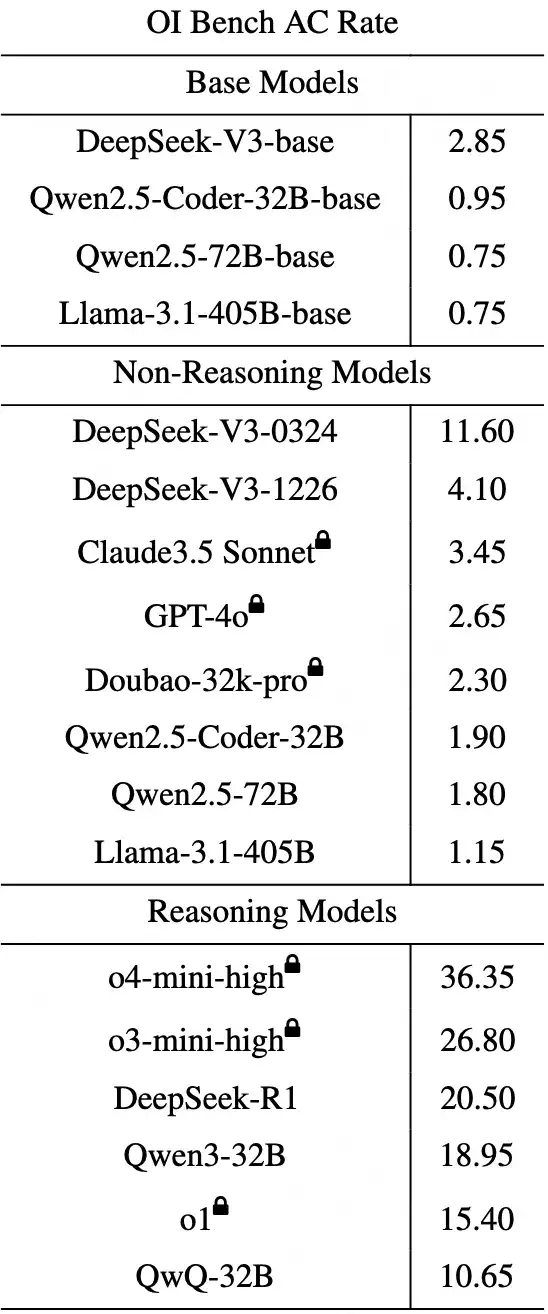
OIBench 的评测榜单未来将由 AGI-Eval 评测社区长期维护更新,欢迎持续关注。榜单地址如下
本文数据均引用自 OIBench v1.0 论文(arxiv:2506.10481v3),发布日期 2025 年 6 月 13 日
接下来为大家详细介绍 OIBench 数据集是如何构建以及如何对大模型进行评测的。
1. OIBench 的构建与创新
OIBench 是一个高质量、私有且极具挑战性的信息学奥赛级别算法题库,旨在提供一个更真实、更具区分度的评估基准。该数据集的算法题主要来源于中国 ACM-ICPC 队伍和信息学奥赛的高校教练团队精心编纂,他们拥有丰富的高难度算法题设计经验和独到见解。
为了确保 OIBench 题目的高质量和高挑战性,我们制定了三条严格的准入标准,OIBench 具备以下关键特性:
我们还在论文中展示了 OIBench 与其他主流评测集的对比(见下表),可以看到 OIBench 在题目难度和测试用例规模上都相对更高。
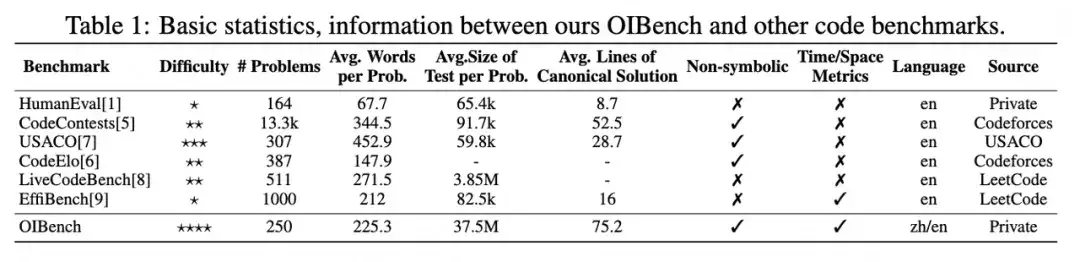
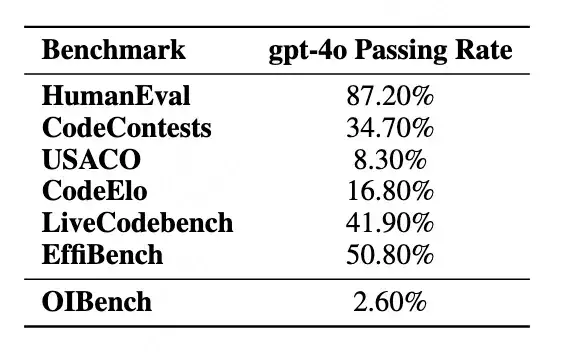
OIBench 在题目难度和测试用例规模上显著领先于其他主流评测集。例如,在其他榜单上表现较好的 GPT-4o 模型在 OIBench 上仅能答对 2.6% 的题目,同时 OIBench 的测试用例数量大幅超过了其他算法竞赛基准,对标真实的竞赛环境。
强抗数据污染能力: 在评测集设计中,“同源污染” 是一个重要挑战。由于大模型的预训练和微调数据往往会爬取大量互联网内容,容易出现模型在训练阶段就见过类似题目的情况,从而导致评测分数虚高,无法真实反映模型实际能力。虽然 OIBench 在数据构造时极力避免使用互联网可公开检索的题目,但一些相近的题目仍可能在大模型的预训练或微调阶段带来数据污染。为此,我们专门设计了实验来验证 OIBench 的抗污染能力:
2. OIBench 评测结果与发现
参评模型与评测方式
OIBench 对 18 个主流大模型(包括 14 个指令微调模型和 4 个基础模型)进行了 zero-shot 评测,涵盖 C++、Python、Java、JavaScript 四种语言。
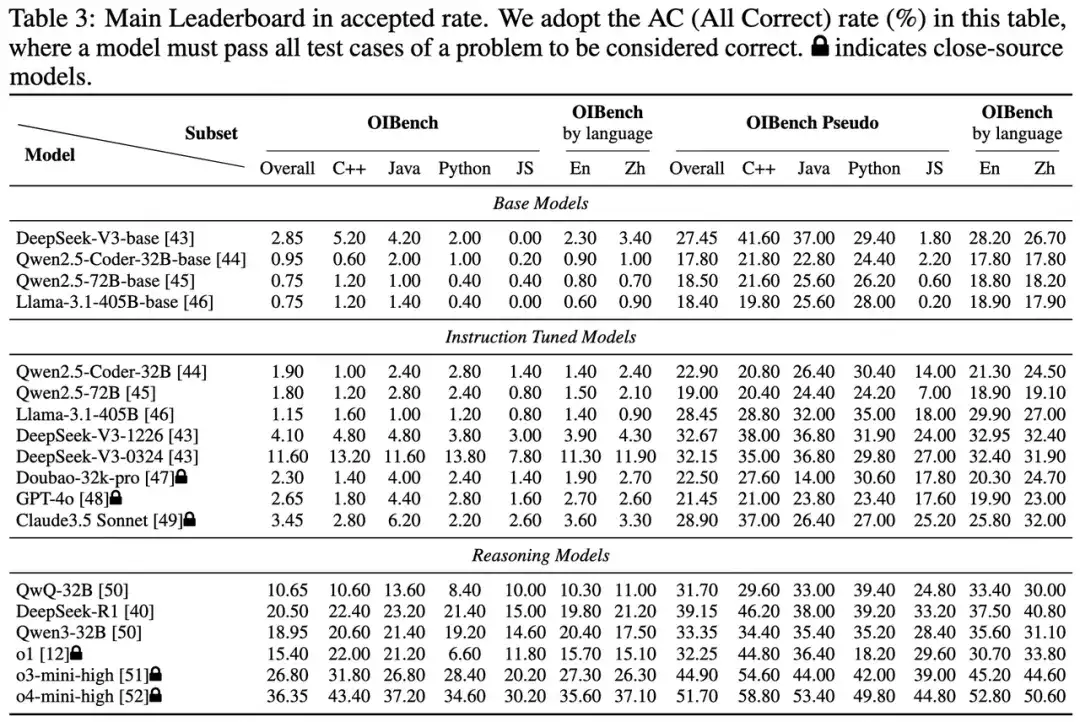
主榜单结果
语言偏好与中英文差异: 模型在 JavaScript 和 Python 上的表现平均比 C++ 和 Java 低 10% 以上,可能与训练数据分布有关;中英文题目表现差异极小,甚至中文略优。
伪代码(Pseudocode)提示的积极作用
OIBench 的高难度对普通模型来说挑战巨大。为了更细致地分析模型的能力,我们还引入了 “伪代码提示” 评测:将标准解答转为伪代码并作为提示输入,考查模型理解和复现解题思路的能力。
结果显示,所有模型在有伪代码提示时表现均有明显提升,尤其是强推理模型(如 o3-mini-high 和 o4-mini-high)提升尤为显著。这说明伪代码极大降低了题目的推理难度,更能考查模型的代码理解与生成能力。同时,推理模型在理解解题思路方面依然具备优势。进一步分析发现,指令微调模型的表现与其基础模型高度相关,说明代码生成能力主要取决于预训练水平。
在提供伪代码提示后,所有模型表现均有明显提升,尤其是强推理模型,这说明伪代码能有效降低推理难度,更能考查模型的代码理解与生成能力。
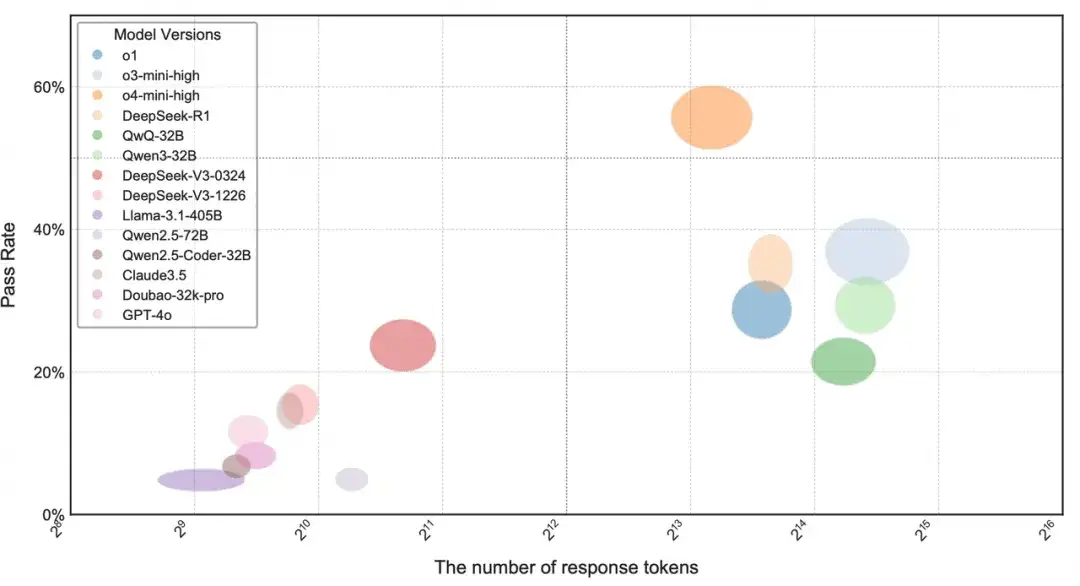
推理效率: 随着 “测试时推理” 成为提升大模型能力的重要手段, OpenAI-o1、DeepSeek-R1 等模型在解题时会生成大量推理内容。我们统计了各模型推理时的 Token 消耗与通过率的关系,发现 o4-mini-high 能以更少的 Token 解出更多题目,推理效率最高;DeepSeek-V3-0324 虽然表现不俗,但推理 Token 数量也最多,体现其长链推理的特点。
3. 模型与人类选手的对比
许多技术人员都关心:现在的大语言模型在算法编程题上的表现,和真正的竞赛选手相比到底如何?OpenAI、 DeepSeek 会用线上编程平台 Codeforces 的 Elo 评分体系来做模型与人类的对比,并报告自家模型最新的 Elo 分数,但这种方式存在一些问题:比如数据时间跨度长(一般需要半年以上的参赛记录)、在线选手水平波动大,导致对比结果不够精确,也不容易复现。
OIBench 创新性地采用了更可控的方法:邀请了中国 985 级别高校 ACM 校队选手参与部分题目的作答,并将其成绩与大模型直接对比,提供了更精准、可复现的人机对比数据;我们用小提琴图展示了每个模型在所有人类选手中的排名分布,能直观反映模型与人类在不同题目上的表现差异。
排名规则参考了信息学奥赛(IOI)的标准:先比较通过的测试用例数量,数量相同则按运行时间排序(越快越高);
提交标准:人类选手的答案以最后一次提交为准。
人类解答开源: 分析中所涉及的人类解答记录也将匿名化并开源,便于后续研究和复现。
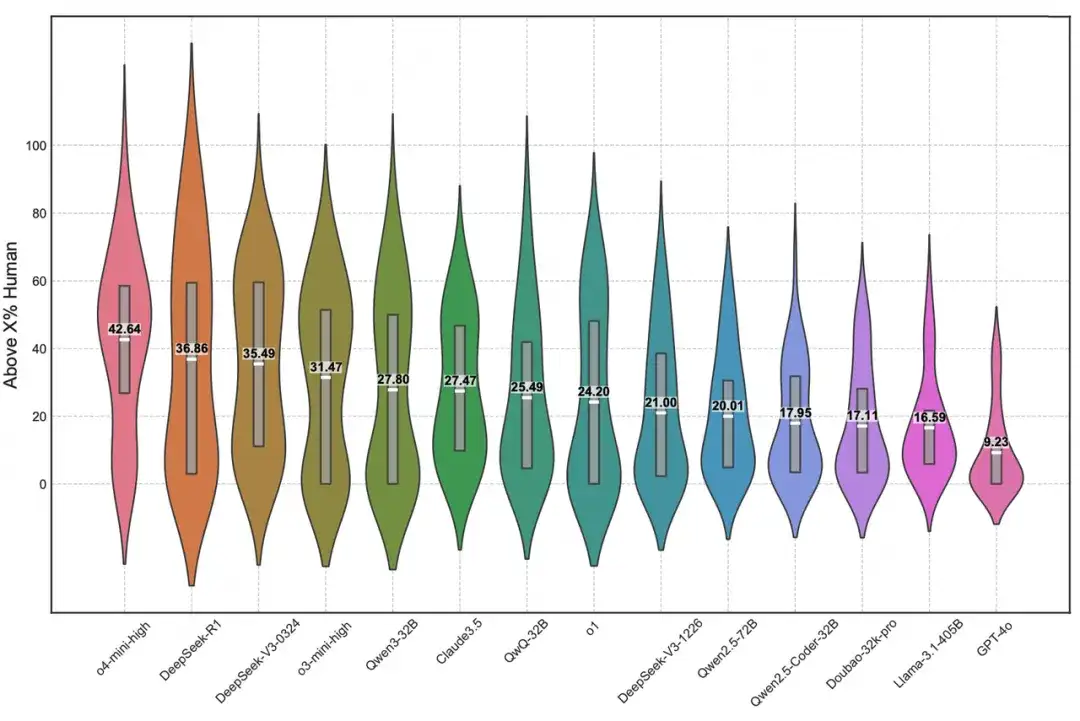
在小提琴图中,各模型在每道题中的人类排名位置会作为一个数据点,这些数据点形成的概率密度图就是小提琴图中的“琴身”。“琴身”的宽度显示模型排名分布的密度,越宽表示模型在对应的排名区间内出现的频率越高,从而直观地反映出模型排名表现的集中趋势。中央的框线代表排名数据最集中的区域,以o4-mini-high举例,它的排名大致超过了42%的人类选手。
4. 总结与展望
本文深入分析了当前大模型编程能力评估中存在的认知鸿沟,揭示了 “宣传” 与 “现实” 之间的差距。Meituan-M17团队 通过 OIBench 这一高质量、高区分度的私有数据集,清晰揭示了顶级 LLM 在面对复杂算法挑战时,与人类顶尖水平之间的真实差距。不仅为大语言模型的算法推理能力评测树立了一个全新标杆,也为整个行业带来了更多思考。
它让我们看到:即使在模型能力突飞猛进的今天,真正高质量、高难度的算法挑战依然能够 “难倒” 最先进的 AI。尤为重要的是,希望 OIBench 的开源和透明能够为社区协作和持续创新做出一些贡献。我们期待它能成为连接学术、产业和开发者的桥梁,推动大模型在算法智能领域迈向新高度。未来,随着模型能力和评测需求的不断演进,OIBench 也会持续迭代,与大家共同见证 AI 推理的进化之路。
与此同时,我们也观察到,对于大多数人类开发者来说,即使他们接受过专业的算法设计训练,面对高难度算法和复杂系统设计,同样需要工具和智能助手的辅助才能更上一层楼。大模型的强大推理和代码生成能力,正好能为人类开发者提供有力支持,帮助他们提升算法设计和代码实现的效率。OIBench 促使我们深入思考:未来的代码开发,已超越 “人” 或 “模型” 单打独斗的模式,转变为人机协同、优势互补的新范式。
5. OI 赛题之外 —— Code Agent 催生的评测范式迁移
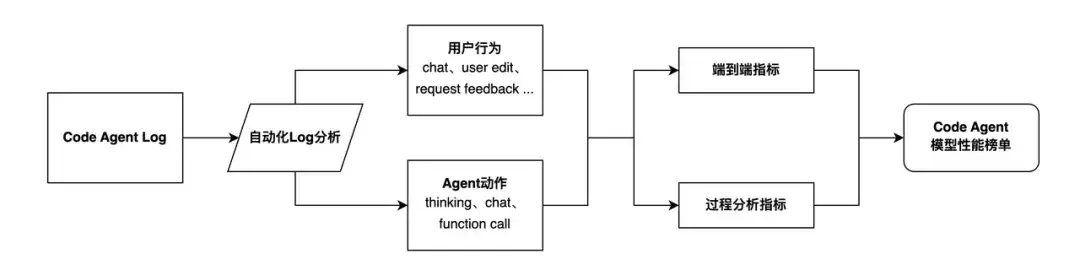
当前大量涌现的 Code Agent 类框架与产品,使得人机协作解决更加复杂的工程问题成为可能,这预示着对 Code Agent 在实际工程场景中与人类协作能力的评估,将变得日益关键。然而,现有的 Code Agent 评测基准(如 SWE-bench 系列)存在一个核心问题:它们将人类开发者完全排除在评估流程之外。这种 “端到端” 的自动化评测,虽然能比较容易的量化模型在封闭任务上的表现,却无法回答一个更关键的问题:在真实、开放的开发环境中,Code Agent 能否与人类高效协作?当前多数 Code Agent 框架在交互设计上对人机交互的忽视,导致其评测结果与实际应用价值之间存在明显脱节。
结合 OIBench 引发的关于人机协同、优势互补的思考,Meituan-M17团队 也开始关注人机协作评测这一新的评测范式在 Code Agent 场景的应用,进而弥补当前范式引起的评测结果与实际应用价值间的鸿沟。基于此,我们与 AGI-Eval 评测社区合作,设计并计划举办一项创新的人机协作编程竞赛。
竞赛核心设计如下:
评测流程如下:
这项竞赛不仅填补了现有评测体系的空白,更为探索未来人机协作的无限可能提供了宝贵的数据和实践参考。对这项比赛感兴趣的小伙伴,欢迎前往 AGI-Eval 评测社区了解详情。
网页端地址:https://agi-eval.cn/competition/activity
文章来自公众号“机器之心”


【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
