# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
7 月 10 日,微软研究院 AI for Science 团队在《Science》杂志发表了题为「Scalable emulation of protein equilibrium ensembles with generative deep learning」的研究成果。
该研究提出了一种名为 BioEmu 的生成式深度学习模型,能够以前所未有的效率和精度模拟蛋白质的构象变化,为理解蛋白质功能机制和加速药物发现打开了新路径。
近年来,AlphaFold 等模型在蛋白质结构预测方面取得了突破性进展,但这些方法通常只能预测单一静态结构,难以捕捉蛋白质在功能过程中所经历的动态变化。蛋白质并非静止不动的分子,而是处于不断变化的构象系综(conformational ensemble)中,其功能往往依赖于这些结构之间的转换。
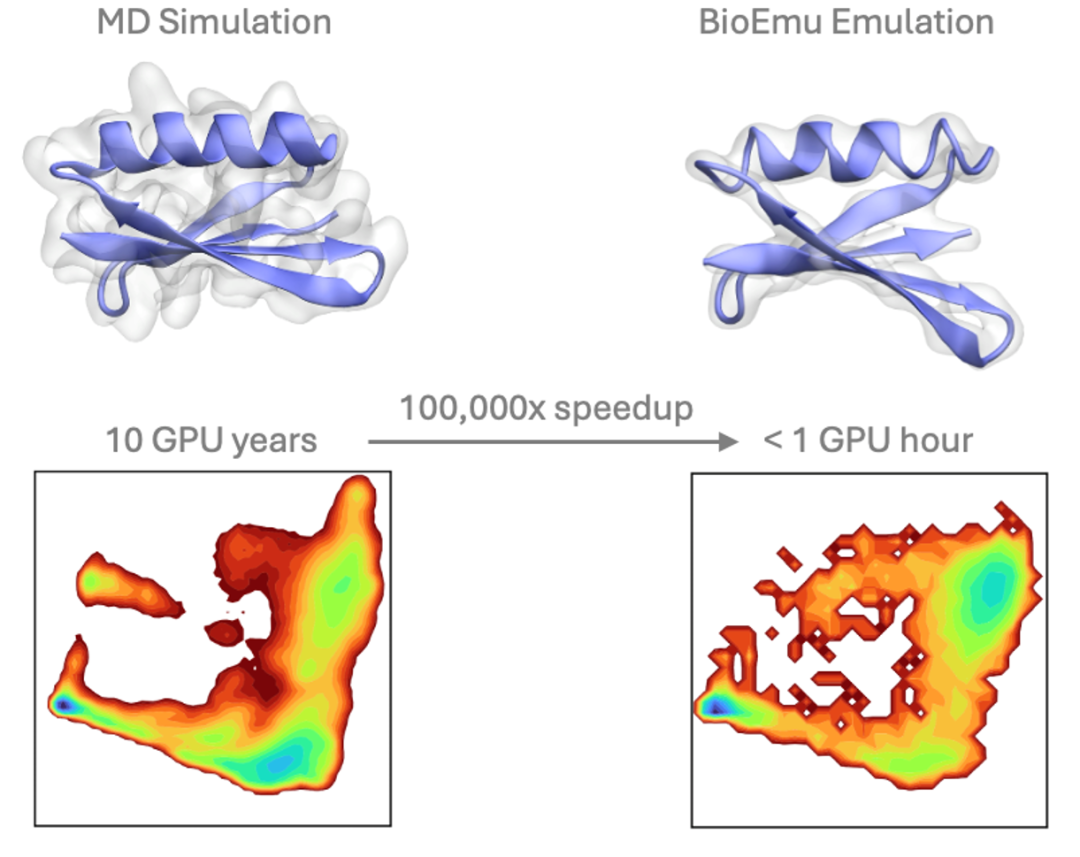
BioEmu 正是为了解决这一挑战而生。它通过结合 AlphaFold 数据库中的静态结构、超过 200 毫秒的分子动力学(MD)模拟数据,以及 50 万条蛋白稳定性实验数据,训练出一个能够在单张 GPU 上每小时生成上千个独立蛋白质结构的生成模型。
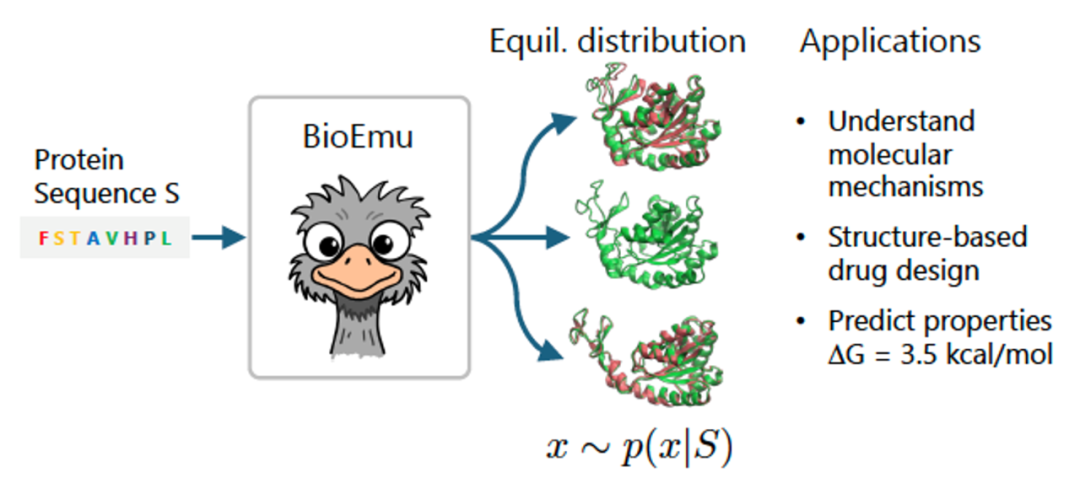
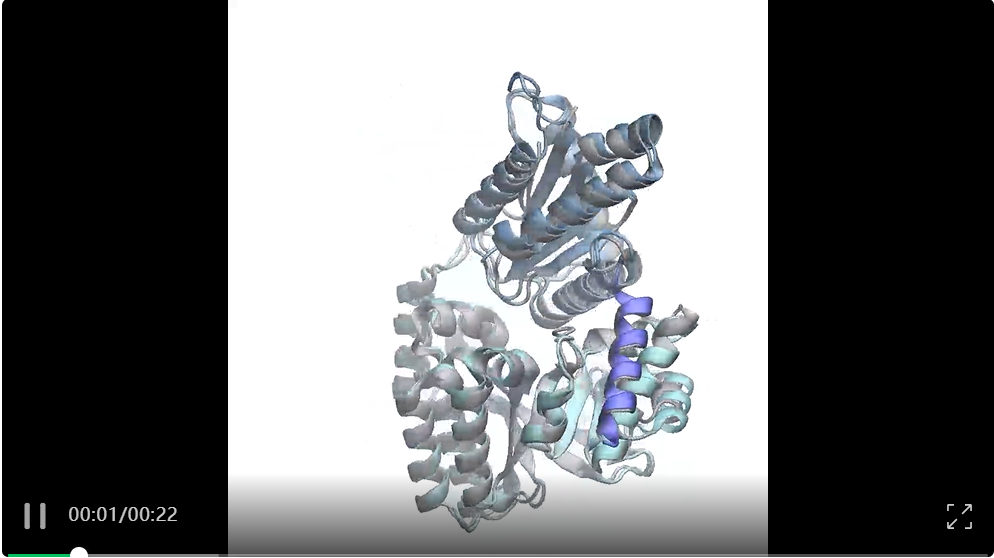
视频:BioEmu生成的蛋白质动态构象展示
BioEmu 承接自微软研究院的前期工作 DiG(Distributional Graphormer),基于扩散模型架构,结合 AlphaFold 的 evoformer 编码器和二阶积分采样技术,能够高效地从蛋白质构象分布中采样。其核心创新在于:
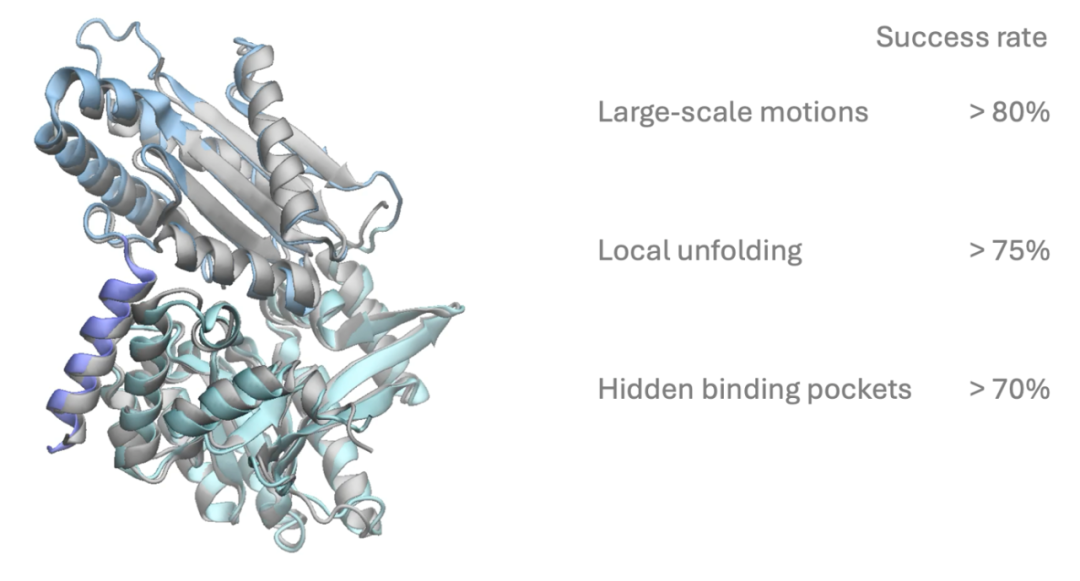
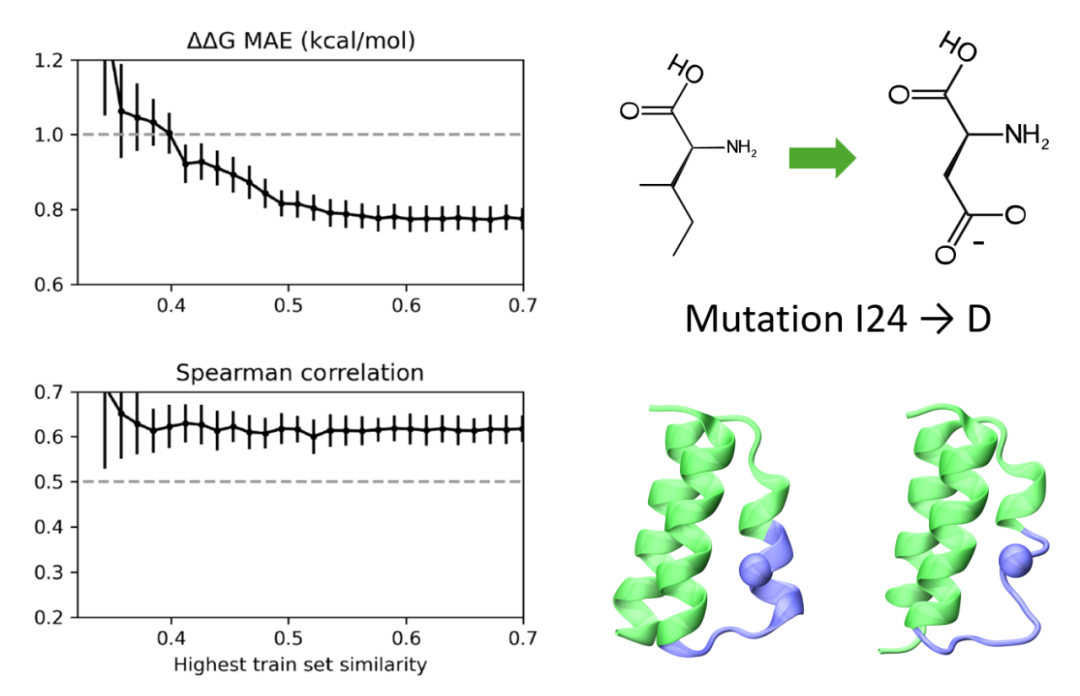
研究团队已在 GitHub 和 HuggingFace 上开源了模型参数和代码,还发布了超过 100 毫秒的 MD 模拟数据,涵盖数千个蛋白系统和数万个突变体,为后续研究提供了丰富资源。BioEmu 也部署在了 Azure AI Foundry 和 ColabFold 等平台,使得用户可以便捷地运行模型。
BioEmu 的开源发布也标志着微软在推动开放科学方面迈出的重要一步。目前,BioEmu 的建模对象主要是单体蛋白质。研究团队正在探索将其扩展到蛋白质复合物、蛋白-配体相互作用等更复杂的生物体系,并结合实验数据进一步提升模型的泛化能力和可解释性。在蛋白质科学、药物设计和合成生物学等领域,BioEmu 有望成为连接结构与功能、理论与实验的桥梁。
文章来自于微信公众号“机器之心”。


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
