# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
前几天晚上,我在 GitHub 上看到一个让我眼睛发直的项目。
一个叫 shareAI‑lab 的团队对 Claude Code 进行了彻底逆向,并把完整的研究资料、中间的分析过程全部 po 了出来。
Claude Code 可是 Anthropic 家的当红炸子鸡,是他们在 AI coding 这条路上最拿得出手的产品。
但现在,Claude Code 的底裤被一个民间逆向仓库扒了,曝光了核心技术架构、实现机制和运行逻辑,相当于做了个开箱拆机,连怎么听懂人话、怎么调用工具、怎么记住上下文、怎么防恶意指令,全都曝光了。
仓库地址我放在这里了:
https://github.com/shareAI-lab/analysis_claude_code
(PS:这个项目目前在 archive,作者佬在小红书回应还在更新中)
先铺个背景方便大家伙儿理解——
大家都知道 Claude Code 本身是闭源的,但为了让 CLI 正常跑,他们还是得把代码随安装包发给用户。所以 CLI 里还打包了一份 50 k+ 行的混淆 JavaScript 代码,只是这份代码被 刻意“打乱、加密、改名”,目的就是把核心算法和 Prompt 逻辑藏起来,让人看不懂,避免别人抄袭了去。这就叫 JavaScript 混淆。
但是 JS 终究要跑在本地,再怎么混淆,Node.js 终究要看到可执行的明文逻辑,这就给逆向者提供了入口。
那这位民间逆向者是咋做的呢?
他们是用 claude code 去分析 claude code(v1.0.33)本身的混淆后代码** **,(哎?听起来像套娃)

也就是对 5 万行的混淆代码切片,借助 Claude Code 的力量分析 15 个 chunks 文件,再用人肉 + 调试补洞,最后拼出来一份 95% 准确度的“推断版架构”。

【友情提示】:下面的逆向笔记并非官方文档,README 里写得很直白——“非 100 % 准确,分析过程中 LLM 难免出现幻觉,仅供学习参考”。
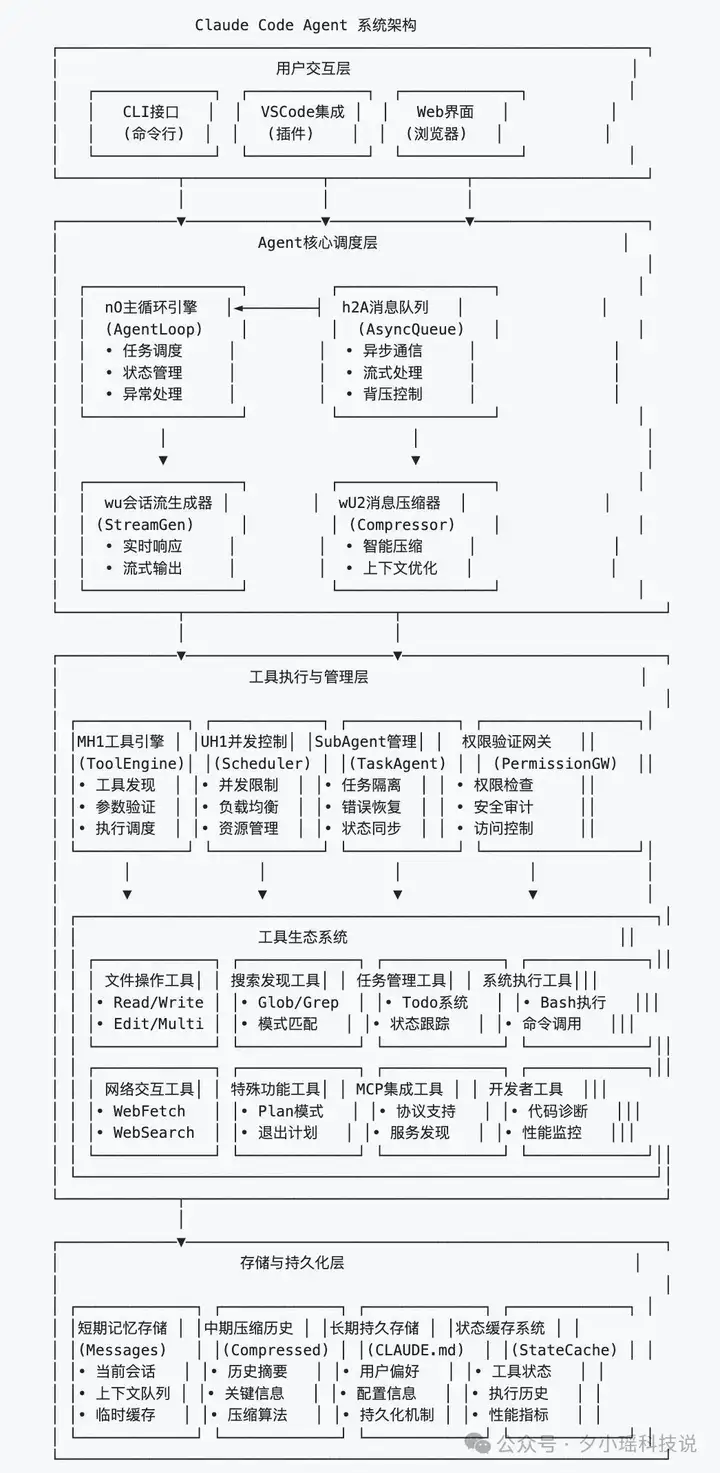
先来看看这份逆向推断版的 Claude Code 系统架构全景图:
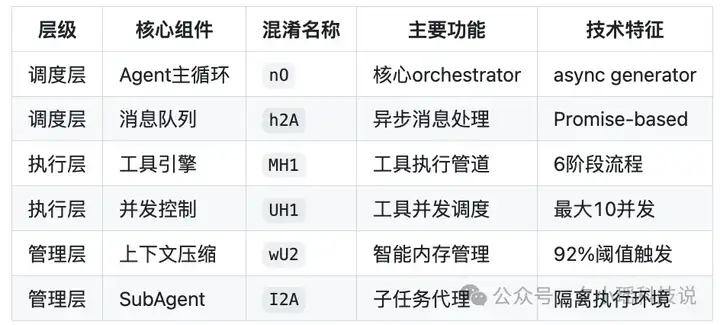
最核心的技术映射如下——
最顶层是用户交互层。
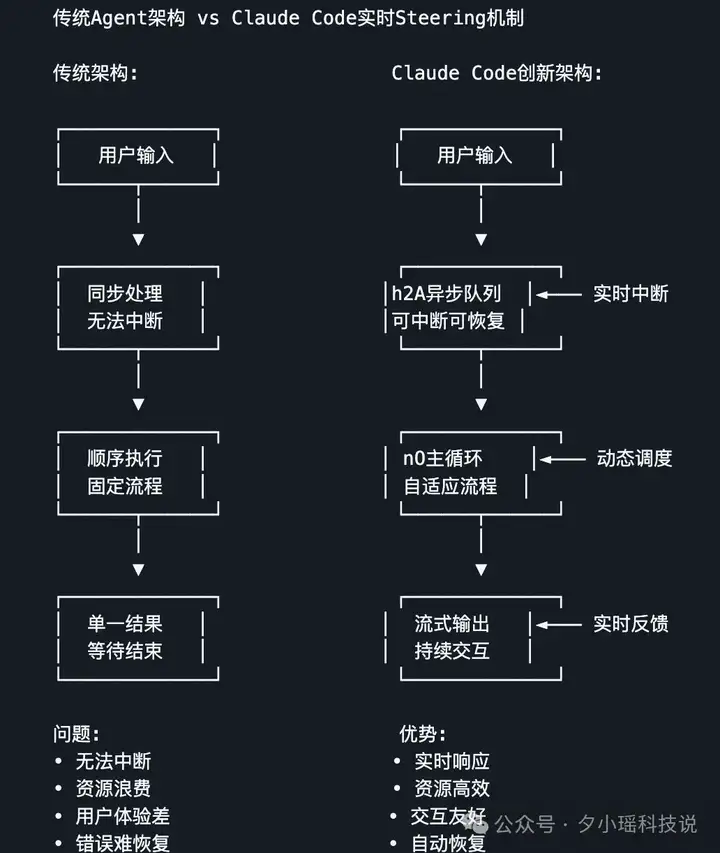
无论你是在命令行里敲 Claude、在 VSCode 用插件,还是在 Web 页面上跑,它们背后对接的其实是同一套调度系统。
这一层只负责接收你的指令,并把它们统一编码为 Claude Agent 系统能理解的请求格式。也就是说,不管你从哪个入口发出指令,最终都会被转化为统一的数据格式,由 “Claude 模型大脑”接收和处理。
而这个“大脑”在中间层——Agent 核心调度层。
中心是一个叫 nO 的主循环引擎(其实就是 AgentLoop),它负责管理一切智能体行为的“总调度室”。流程图是这样的:
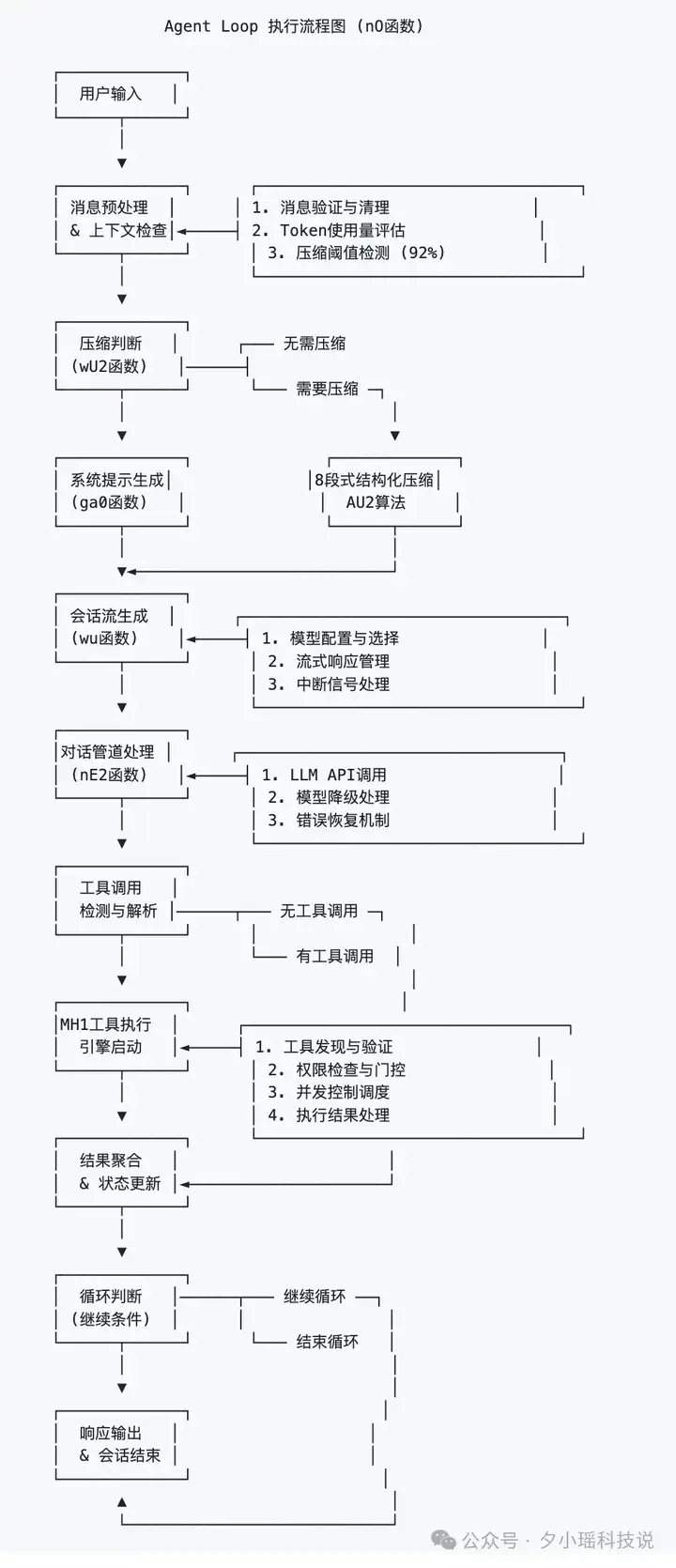
你每输一句话,它就得判断:
这些决策的执行,要靠它左手的h2A 消息队列(负责异步传输和流式反馈),右手的 wu 会话流生成器(实时生成文字输出),加上一套名为 wU2 的压缩引擎来动态优化你用过的上下文。
注意,这里没有一个地方是模型在跑。模型本身只是调度结果中的一个工具,它只是整个流程中的一个“被调用者”。真正做判断、做协调的,是这一整套调度引擎和运行时逻辑。
往下是工具执行与管理层,也是 Claude Code 最像“中台”的地方。
它负责调度具体的子 Agent。比如你发一个“运行 shell 命令”的请求,它就会调出负责 bash 执行的 Agent;你要求读取项目目录,它就找出读写权限最小的文件管理 Agent。
这些 Agent 都受控于几大核心部件:
也就是说,Claude 不是一次性调一个“大助手”来干活,而是每个任务都生成一个独立的“子 Agent”,然后严格按照权限、状态、工具能力来分发执行。
继续往下,是工具生态系统。
这就是 Claude Code 真正的“武器库”。上百个分类明确、职责清晰的小工具,从文件读写、命令执行,到网络搜索、任务管理、MCP 集成、性能诊断应有尽有。
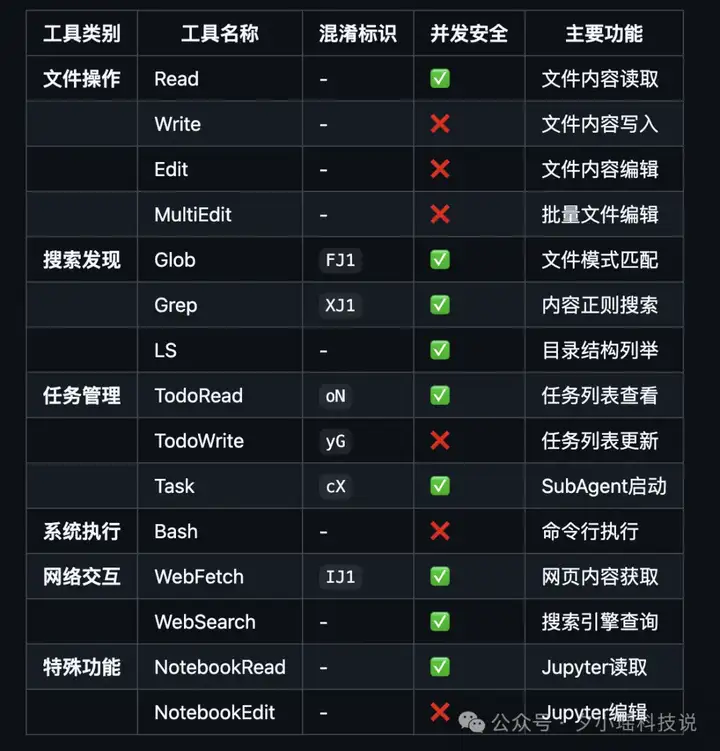
你以为 Claude 在思考,其实它只是在调用:
这种工具生态不是插件,而是结构化地配置在系统里。
工具的定义方式是文件级别,每一个工具都是一个可管理、可审计、可热加载的模块单元。你甚至可以自己写一个 .yaml 文件扔进目录里,Claude 立马能发现它、加载它、赋权限。
最底层,是存储与持久化系统。
这是 Claude 记忆力的来源,整个记忆架构分三层。
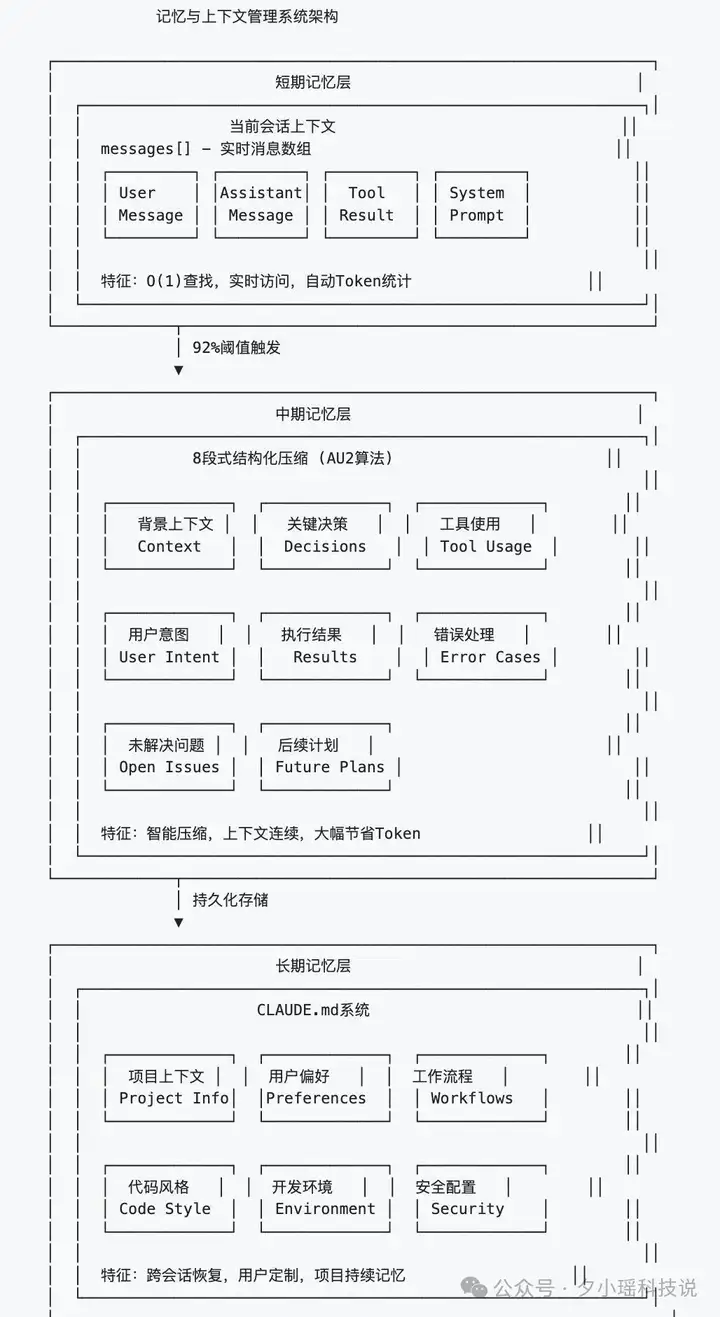
它是按时间维度、压缩策略、任务粒度分层处理记忆:
每一次调用、每一个决策,其实都依赖于这些存储结构的回忆。
Claude Code 并不依赖于云端记忆,而是靠本地状态文件、上下文压缩算法、状态缓存系统构建出一个“类人记忆”的思维体系。
这就是 Claude Code 系统架构的全貌。
它把一套多 Agent 系统跑得像流水线一样顺滑。Claude Code 早就不是一个“智能补全”的工具了,它是一套 AI 时代的“本地分布式 Agent 操作系统”。
说到这里,很多人可能还是觉得,这不就是多加了几个 Agent 和工具嘛,有啥真正厉害的地方?
错了。
如果你真的打开那份逆向分析文档,你会看到一个句子像电流一样穿过代码注释和调度日志:Claude Code 的真正突破,不在于调了几个工具,而在于它让这些 Agent 之间的协作,变成了“实时的、稳态的、动态可控”的过程。
简单说,它不仅能调,还能边调边改方向,边跑边让不同 Agent 对齐节奏。这听起来像废话,但工程上能做到的几乎没有。
另外,项目作者还整理了这里面的重要的技术创新,实时 Steering 技术和 智能上下文压缩算法。
大多数 AI 工具的调度逻辑是触发式的,也就是你下个请求,我执行一次;你换个指令,我再跑一遍。但 Claude Code 的 h2A 消息队列,不是“等你发完才处理”,而是能在指令刚输入一半时就启动流程,并边接收、边调度、边调整。
我们在逆向文档里看到它的核心机制用的是“双缓冲队列 + 条件触发消费”,伪代码如下:
class h2AAsyncMessageQueue {
enqueue(message) {
// 策略1: 零延迟路径 - 直接传递给等待的读取者
if (this.readResolve) {
this.readResolve({ done: false, value: message });
this.readResolve = null;
return;
}
// 策略2: 缓冲路径 - 存储到循环缓冲区
this.primaryBuffer.push(message);
this.processBackpressure();
}
}
简单来说,它不是等消息“堆满”才动,而是只要有人等,它就立刻传;没人等,它就缓冲 + 限流。再加上流式写回机制,这就保证了 Claude 可以边生成文字、边调整任务、边响应新输入。
这才是真正的“Steering”,你能在它做的时候,随时发指令“换方向”,它立刻响应。
Claude 的第二个重大创新,是我们看到的 wU2 上下文压缩系统。
很多 AI 产品都在解决一个问题:上下文太长,token 爆炸,要裁剪。但大多数产品是靠“历史越久越删”“内容越长越删”,要么全砍,要么硬塞。
Claude 不一样。它用了一种 “重要性加权 + 策略性摘要”的压缩法。
比如这段触发逻辑:
// 压缩触发逻辑
if (tokenUsage > CONTEXT_THRESHOLD * 0.92) {
const compressedContext = await wU2Compressor.compress({
messages: currentContext,
preserveRatio: 0.3,
importanceScoring: true
});
}
意思是,当 token 使用量超过阈值 92%,系统就会调用压缩器进行上下文重构。但不是压缩全部,而是按“重要性”打分,只保留 30% 的最关键段落,剩下的提炼成摘要。
这一设计让 Claude 在执行任务时,可以更精准地维持上下文的“记忆完整度”。压缩操作不以时间或长度为主维度,而是以内容关键性为准则,减少冗余信息对模型推理的干扰,同时维持对历史任务、用户偏好和中间变量的追踪能力。
这也是为什么用户在与 Claude 进行长时间交互时,会感觉它记得住,并且记得的都是重点,不容易断片。
从这次的逆向文档中,我们第一次清晰地看到了什么是真正有工程厚度的 Agent 产品。
它并不追求一句话能做多少事,而是让每一句话的背后,都能安全、高效、合理地调度十个 Agent。
而且关键是,它是真的跑起来了。
它让我们看到一个事实:
未来的 AI 编程助手,不会是 ChatGPT 的一个功能分支,而是一个具备工程稳定性、安全性、组织能力的智能体操作平台。
文章来自于“夕小瑶科技说”,作者“R.Zen”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】ai-renamer是一个用AI帮你做文件夹或者图片命名的项目。该项目会根据文件夹或者图片内容来为文件进行重新命名,让你的文件管理更加便利。
项目地址:https://github.com/ozgrozer/ai-renamer
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
