# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大家好,我是徐小夕。
曾任职多家上市公司,多年架构经验,打造过上亿用户规模的产品,目前全职创业,聚集于“Dooring AI零代码平台”和“flowmixAI多模态解决方案”。
最近推出了《架构师精选》专栏,会分享一线企业技术实践和架构经验,并和大家拆解可视化搭建平台,AI产品,办公协同软件的源码实现。
上篇文章和大家聊了自研的多维表格编辑器pxcharts。今天和大家继续分享一款我最近发现的宝藏AI工具——AI-Media2Doc。

先和大家聊一个真实的场景。当我们看到一段精彩的教学视频想整理成笔记,或是想把访谈音频转成结构化文档,又或是需要将短视频快速改写成小红书文案时,是否都是通过手动一条条转录、然后手动把文档格式调整成自己想要的效果呢?
如果有一款AI工具,能自动化把这些音视频转换为我们想要的文档,那将极大地提高我们的工作效率。而 AI-Media2Doc,就是解决上面场景的非常有用的开源工具。
github地址:https://github.com/hanshuaikang/AI-Media2Doc
接下来我就和大家全面剖析这款AI开源项目。
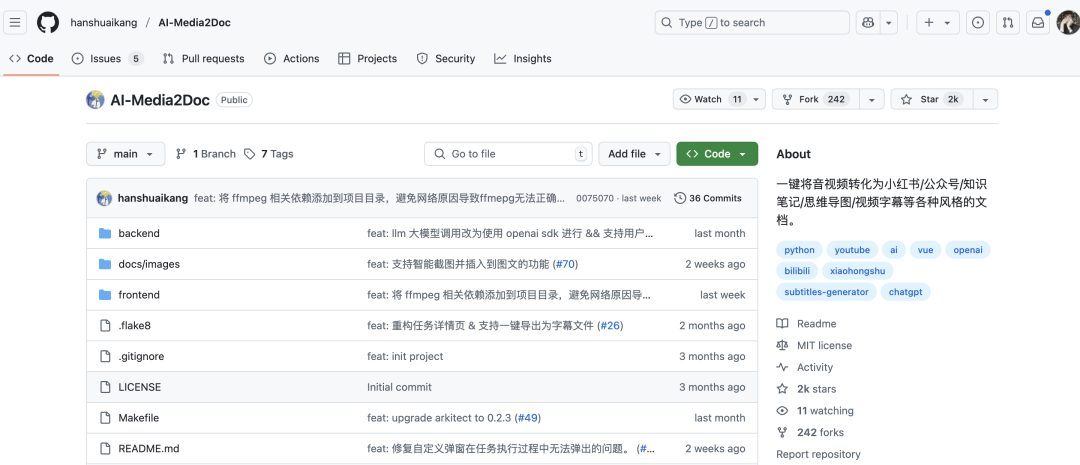
AI-Media2Doc 是一款基于 Web 的 AI 音视频处理工具,核心能力是将视频 / 音频文件一键转化为多风格结构化文档。它的底层逻辑是通过 “音视频解析→文字转录→AI 风格生成” 的全流程自动化,解决用户 “内容格式转换效率低、隐私顾虑重、工具使用成本高” 的痛点。

与市面上多数同类工具相比,它有三个鲜明标签:
1. 全链路本地化
前后端支持本地部署,数据不经过第三方服务器,任务记录保存在用户设备本地。
2. 零门槛使用
无需注册登录,打开工具即可上传文件,操作流程简化到 “上传→选择风格→生成” 三步。
3. 高度开源自由
基于 MIT 协议开源,代码完全透明,支持二次开发和自定义扩展。
接下来我们聊聊它的核心功能亮点。

AI-Media2Doc 的功能覆盖了从音视频处理到文档生成的全链条,且每个环节都针对实际需求做了优化,我通过 “处理流程” 拆解出了它的3大核心能力:
传统音视频转文字工具往往需要用户本地安装 ffmpeg(一款专业音视频处理工具),而 AI-Media2Doc 通过ffmpeg wasm 技术,将这一过程搬到了浏览器前端。用户只需上传 MP4、MOV、AVI、MP3 等格式文件(最大支持 100MB),前端会自动完成音频提取、格式转换等预处理,无需复杂配置。
预处理后的音频会通过 ASR(自动语音识别)转成文字,再由 AI 大模型根据用户选择的风格生成文档。目前支持的风格包括:
小红书风格
自带 emoji、口语化表达,适配短平快的种草内容(如 “宝子们,今天发现一个隐藏技巧…”);
公众号风格
结构清晰,分点论述,适合长文科普(如 “一、起源:屋顶盒的诞生…”);
知识笔记
Markdown 格式,突出关键信息,便于复习(如 “### 梵高的创作困境:10 年 2100 幅画仅卖出 1 幅”);
思维导图
以层级结构呈现核心逻辑,适合梳理框架;
内容总结
提炼核心观点,压缩信息密度。
更灵活的是,用户可以自定义 Prompt(提示词),比如要求 “用学术论文风格总结视频内容”,AI 会严格按照提示调整输出形式。
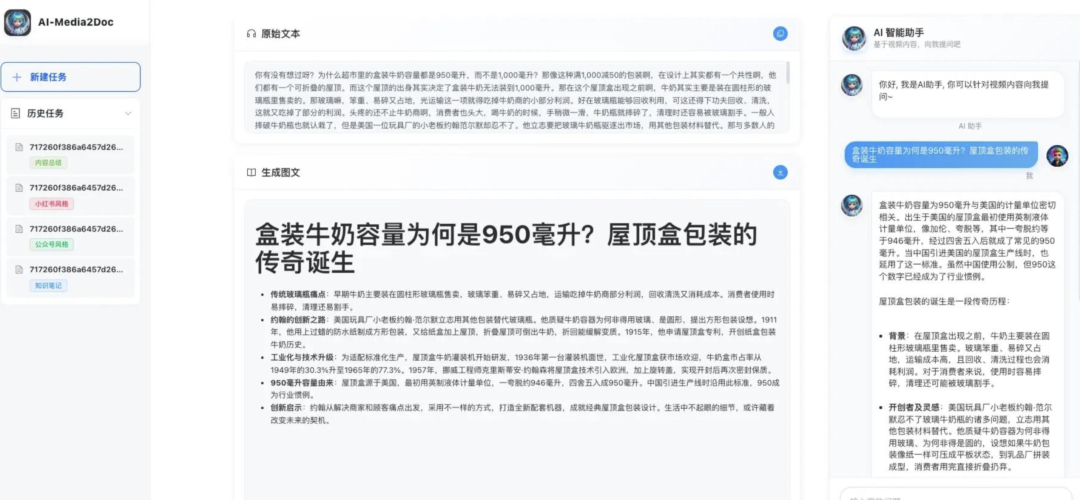
智能截图
无需依赖视觉大模型,仅通过字幕时间戳定位视频关键帧,自动截取画面并插入文档对应位置(如讲解 “梵高割耳事件” 时,自动插入视频中该时段的画面),实现 “文字 + 场景” 的精准匹配;
字幕导出
支持将转录的文字一键导出为字幕文件,方便自媒体人直接用于视频剪辑。
介绍完功能亮点之后,接下来和大家介绍一下如何使用。
无论是普通用户还是开发者,都能快速上手 AI-Media2Doc,这里重点介绍最便捷的Docker 一键部署方案:
步骤 1:准备环境
确保本地安装了 Docker(可参考官网教程),克隆项目代码:
git clone https://github.com/hanshuaikang/AI-Media2Doc.git
cd AI-Media2Doc
步骤 2:配置与构建
make docker-image
步骤 3:启动工具
运行以下命令启动服务,浏览器访问 http://localhost:8000 即可使用:
make run
使用流程:
1. 点击 “上传视频或 MP3 音频”,选择本地文件;
2.上传完成后,选择输出风格(如 “公众号”),也可自定义 Prompt;
3.等待处理完成(根据文件大小,通常几分钟内),即可查看生成的文档,支持复制、导出字幕或继续 AI 对话。
上面就是 AI-Media2Doc的本地启动方式,是不是很简单?
我深度研究了一下它的代码实现,前端使用的是 vite + vue,后端采用的python 和 fastAPI。我梳理了一个该项目的技术架构:
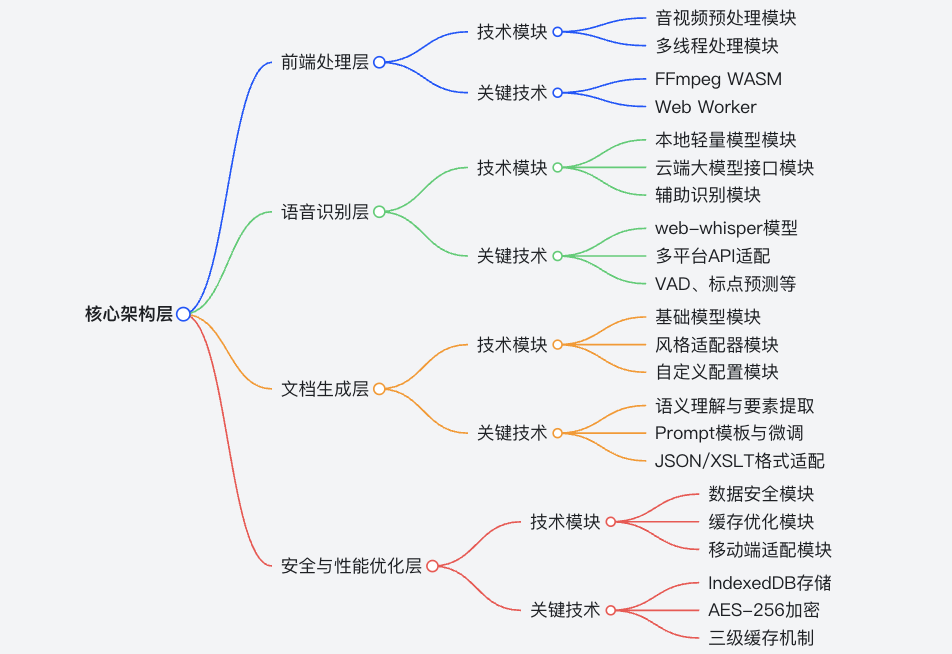
下面我重点和大家分享一下前端层的核心技术实现方案。
1.音视频预处理模块
负责对用户上传的音视频文件进行前期处理,是后续语音识别和文档生成的基础。具体功能包括:
1.1 提取音频轨道,剥离视频画面以减少数据处理量;
1.2 将音频统一转换为16kHz单声道PCM格式,确保适配后续的语音识别需求;
1.3 对长音频进行分段切割,每 30 秒生成一个处理单元,避免因文件过大导致浏览器内存溢出。
2. 多线程处理模块
主要作用是实现音视频处理过程中的多线程操作,提升处理效率,保障用户体验。通过合理分配线程资源,让音视频预处理等耗时操作在后台线程进行,避免因单线程处理而导致的页面卡顿、无响应等问题,确保用户在处理文件时仍能顺畅地进行其他操作。
1.FFmpeg WASM
这是将 FFmpeg 通过 Emscripten 编译为 WebAssembly 模块的技术,使浏览器能够直接处理音视频文件。借助该技术,无需用户在本地配置 FFmpeg 环境,实现了工具的开箱即用,大大降低了用户的使用门槛,同时也减少了因环境配置问题带来的麻烦。
2. Web Worker
是实现多线程处理的核心技术,能够在后台创建独立的线程来处理音视频预处理等耗时任务。它让主线程(负责页面渲染和用户交互)能够从繁重的处理工作中解放出来,保证页面的流畅运行,提升了工具的整体性能和用户体验。
在深度体验了这个AI项目之后,我觉得它对笔记整理,会议纪要,自媒体从业者有非常大的帮助,比如我自己在运营自媒体账号,很多时候也需要将视频或者音频内容转换成文本在不同平台发布,有了这个开源工具,一切都变得简单而高效。当然这个项目还有很多优化的空间,大家也可以基于它自行扩展,实现更加强大的音视频转文档工具。
最近我研发的多维表格也在持续迭代中,有很多功能我会在接下来的文章中和大家持续分享。
体验地址:http://pxcharts.com
文章来自于微信公众号“趣谈AI”,作者是“徐小夕”。


【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
