# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
WebAgent 续作《WebShaper: Agentically Data Synthesizing via Information-Seeking Formalization》中,作者们首次提出了对 information-seeking(IS)任务的形式化建模 并基于该建模设计了 IS 任务训练数据合成方法,并用全开源模型方案取得了 GAIA 评测最高 60.1 分的 SOTA 表现。
WebShaper 补足了做 GAIA、Browsecomp 上缺少高质量训练数据的问题,通义实验室开源了高质量 QA 数据!
WebShaper 体现了通义实验室对 IS 任务的认知从前期的启发式理解到形式化定义的深化。
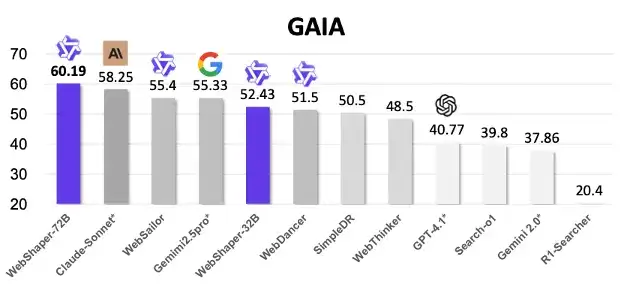
图表 1:WebShaper 在 GAIA 上取得开源方案 SOTA。
WebShaper —— 合成数据范式的转变
在大模型时代,「信息检索(Information Seeking, IS)」早已不是简单的 「搜索 + 回答」 那么简单,而是 AI 智能体(Agent)能力的重要基石。无论是 OpenAI 的 Deep Research、Google 的 Gemini,还是国内的 Doubao、Kimi,它们都把 「能不能上网找信息」 当作核心竞争力。
系统性地构造高质量的信息检索训练数据成为激发智能体信息检索能力的关键,同时也是瓶颈。当前主流方法依赖 「信息驱动」 的合成范式 —— 先通过网络检索构建知识图谱,再由大模型生成问答对(如 WebDancer、WebWalker 等方案)。这种模式存在两大缺陷:知识结构与推理逻辑的不一致性,以及预检索内容的局限导致的任务类型、激发能力和知识覆盖有限。
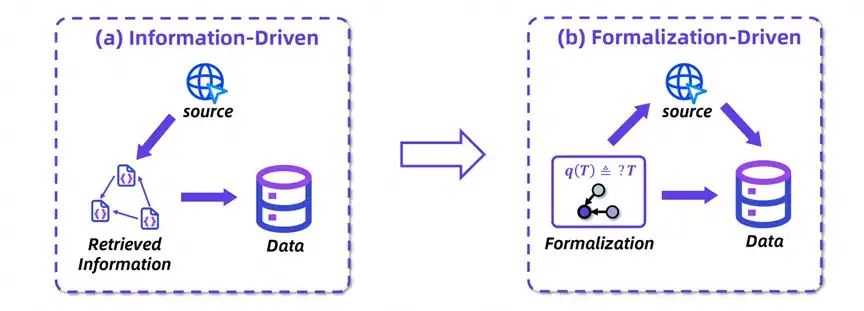
图表 2:WebShaper 从 「信息驱动」到 「形式化驱动」 的范式转变。
WebShaper 系统开创性提出 「形式化驱动」 新范式,通过数学建模 IS 任务,并基于该形式化,检索信息,合成训练数据。形式化驱动的优点包括:
1. 全域任务覆盖 :基于形式化框架的系统探索,突破预检索数据边界,实现覆盖更广任务、能力、知识的数据生成。
2. 精准结构控制 :通过形式化建模,可精确调控推理复杂度与逻辑结构。
3. 结构语义对齐 :任务形式化使信息结构和推理结构一致,减少数据合成中产生的错误。
Information Seeking 形式化建模
图表 3: 形式化建模
WebShaper 首先提出基于集合论的 IS 任务形式化模型。
该模型包含核心概念「知识投影(Knowledge Projection)」,他是一个包含实体的集合:
该形式化建模让 WebShaper 不再依赖自然语言理解的歧义,而是可控、可解释、可扩展的数据合成方案。
智能体式扩展合成:让 Agent 自己 「写题」
为了与形式化建模保持一致,WebShaper 整个流程开始于预先构建且形式化的基础种子任务,然后在形式化的驱动下,将种子问题多步扩展为最终的合成数据。此过程采用专用的代理扩展器 (Expander) 模块,旨在通过关键过程 (KP) 表征来解释任务需求。在每个扩展阶段,系统都会实现逐层扩展机制,以最小化冗余,同时通过控制复杂度进程来防止推理捷径。
种子任务构建
为了构建种子任务,作者下载了全部 WikiPedia,并在词条中随机游走检索信息,合成基础的种子 IS 任务。
KP 表示
IS 任务形式化模型是复杂度的,其中包含大量的交、R - 并和递归操作。为了在 Expander 中表示和使用该模型,作者提出了一种 KP 表示。其中通过引入 「变量」 和 「常量」,以及 R - 并的可交换性质,表示了 IS 形式化模型。
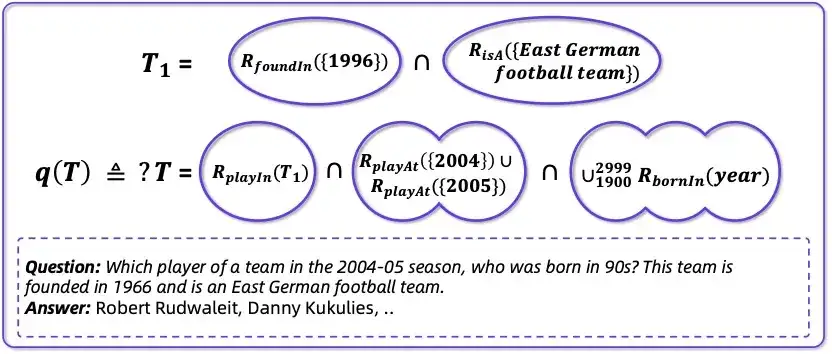
如,将如下的问题:
「Which player of a team in the 2004-05 season, who was born in 90s? This team is founded in 1966 and is an East German football team.」
表示为:

图表 4 :形式化表示。
逐层扩展结构
数据扩展的策略是数据合成的关键。之前的方法在我们的形式化模型中将得到下图中的 Random Structure 和 Sequential Structure:
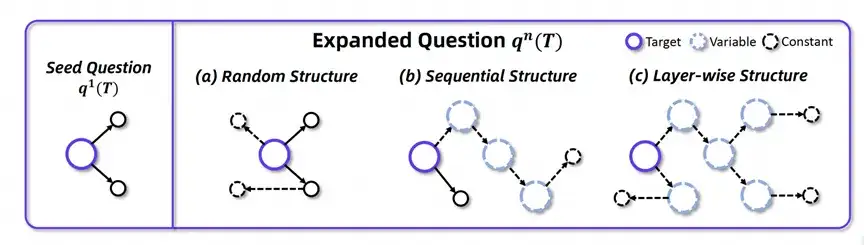
图表 5 :扩展策略对比。
这样的结构存在两个问题:
为此,作者提出如上图所示的逐层结构,每次扩展都选择叶结点常量进行扩展,有效地解决了上述的两个问题。
扩展智能体
具体扩展是由 Expander 智能体负责执行,他接受当前问题的形式化表示:
这一步,使得我们不仅能构建覆盖度广的任务,更能确保任务正确性和推理链条的严谨性,大幅减少错误传播。
Agent 训练
基于形式化生成的高质量任务和完整的行为轨迹,作者使用监督微调(SFT)+ GRPO 强化学习策略来训练 Agent。WebShaper 最终得到 5k 的训练轨迹。
训练后,模型在 GAIA 基准任务中获得:
我们在全使用开源模型方案下拉近了用最强闭源模型 o4 mini 的差距,大幅领先第二名的开源方案。
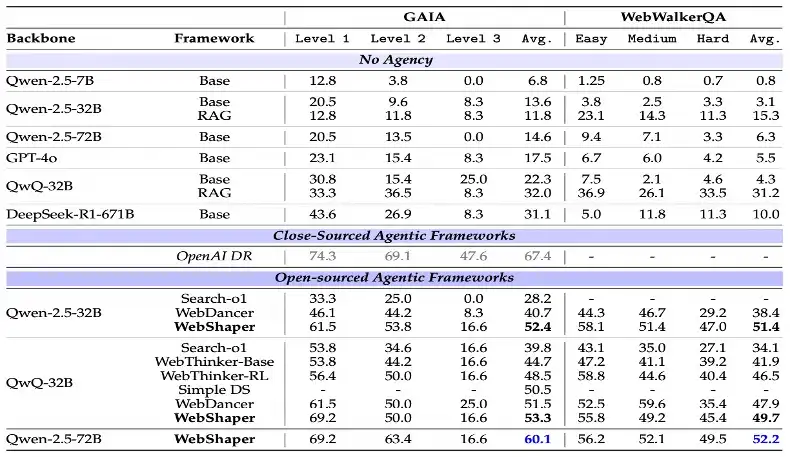
图表 6 :与最新基线方法的对比。
进一步分析
论文中,作者还进一步分析了数据和训练模型,发现:
1. WebShaper 数据领域覆盖充分。
2. 在 WebShaper 数据上,通过 RL 训练能大幅激发模型的 IS 能力。
3. 消融实验验证了形式化建模和逐层扩展策略的有效性。
4. 求解 WebShaper 任务,相比于基线数据要求更多的智能体 action。
为什么这件事重要?
用开源数据 + 模型做到 GAIA 60 分,你也可以。
现在就来试试:https://github.com/Alibaba-NLP/WebAgent
文章来自公众号“机器之心”


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
