# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
你刷的每一条短视频,背后都隐藏着推荐算法的迭代与革新。
作为最新成果,字节跳动的算法团队提出的全新推荐排序模型架构RankMixer,在兼顾算力利用率的同时,实现了模型效果的可扩展性。

RankMixer以软硬件协同的视角重新设计推荐模型,“马车换跑车”,将抖音推荐精排模型的Dense参数量从一千万量级(16M)扩大两个数量级到了10亿(1B)量级。
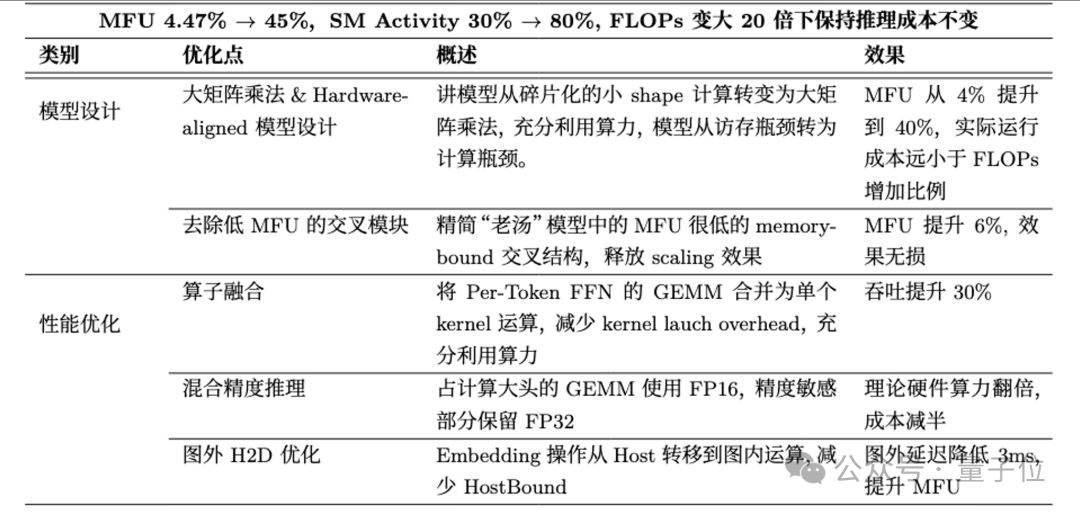
同时通过充分发挥GPU的算力和极致的工程优化,研究团队将模型的MFU提升近10倍到40%+,推理SM Activity从30%提升到80%,大幅降低Scaling Up推理成本,在参数量变大两个数量级下推理成本不增加。
在抖音主feed推荐场景,RankMixer-1B模型在不增加延迟下已经全量生效,累计带来了超过0.3%的LT30收益和超过1%的用户时长收益,并且推广到字节内部几十个业务场景完成上线。
抖音每天为数亿用户提供个性化信息流服务。而支撑这一切的,正是其幕后强大的推荐算法模型。
近年来随着推荐领域海量内容和数据量爆炸式增长、大语言模型算法的变革、以及大规模算力的升级换代,业界对推荐大模型的兴趣与日俱增。
推荐模型是否也能像大语言模型那样存在Scaling Law(规模定律),即通过持续扩大模型参数规模持续提升推荐效果? 然而在实践中还存在着诸多阻碍。
业务上:亿级用户平台下高并发的机器成本和低延迟要求对模型效率提出极高的要求。如果推理慢上哪怕几十毫秒,用户体验就会显著下降。支撑模型Scale Up的机器成本也需要严格满足业务ROI。
算力上:传统模型的算力利用率(MFU, Model FLOPs Utilization)过低只有个位数,难以充分发挥GPU性能。
推荐模型长期以来依赖于堆叠人工设计的特征交叉模块,CPU时代的模型结构无法适应今天的GPU特性,访存瓶颈和个位数的算力利用率,90%以上算力是浪费的。
用大算力的GPU硬件跑传统的推荐模型结构,堪称“高速公路跑马车”。
算法上:传统的模型加宽加深提升有限,目前主流的推荐模型难以通过简单堆叠层数或宽度来大幅提升模型效果,Scaling Up的边际收益较低。
DNN结构容易受特征淹没和过参数化冗余的影响,MMoE容易出现专家训练不平衡、Transformer结构不适应推荐数据特性且计算复杂度太大。
针对上述问题,字节跳动算法团队提出兼顾算力利用率和效果可扩展性的全新推荐模型架构:RankMixer。
RankMixer的设计动机
RankMixer核心思想是一方面从模型结构上对齐GPU硬件特性,让模型的主要计算都能转化为大矩阵乘法等GPU高效执行的操作,从访存瓶颈转变为,充分利用GPU的算力。
另一方面同时兼顾算力利用和推荐数据特性,强化模型参数空间对多样的特征交互信号的捕捉。
RankMixer模型结构如下图所示:
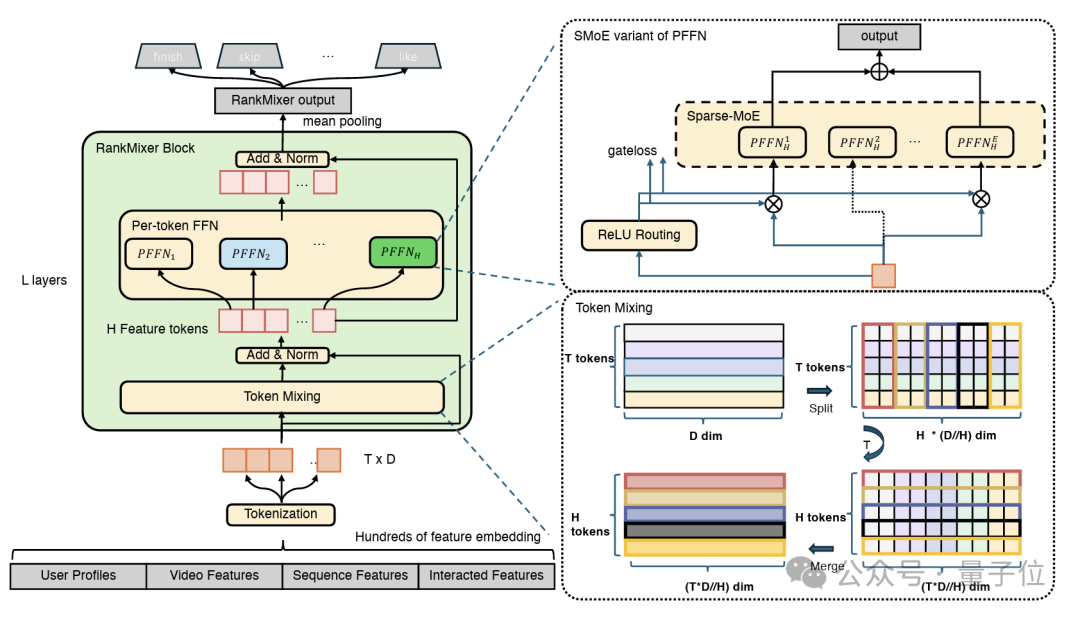
整体采用类似Transformer的层次堆叠结构。同时引入了TokenMixing、Per-Token SparseMoE等创新。
模型的输入首先将各种特征Embedding进行Token化,然后在每个块中先经过TokenMixing模块实现跨特征的信息交互,再经过逐Token的FFN实现特征子空间的独立建模和非线性变换。
最后的输入用于预估用户对视频的各种行为概率。
特征Token化与跨特征交叉:高效无参的跨特征交互
推荐场景的输入特征通常极其丰富,涵盖用户画像、视频内容信息、用户在app的实时行为序列和超长行为序列、交叉信息等。类型多样,维度不一,语义差异巨大。
为了后续计算的可并行性,RankMixer提出Automatic Feature Tokenization机制,将输入Token化为维度对齐的Token序列。
首先基于业务先验知识按语义划分特征组,组内特征拼接后等距切分为固定维度的“Token”,每个Token代表一个语义一致的特征子空间,最后将切分后的向量统一映射到模型隐层维度。
这种做法的好处避免了一个特征一个Token带来的计算碎片化,便于后续模块并行处理和充分利用硬件算力。
如果让每个特征Token各自为战,效果肯定很差,因为特征交叉和全局信息的利用对推荐效果至关重要。
研究团队引入TokenMixing模块,将每个Token的向量分成H个小子空间,通过拼接不同Token在对应head的向量,实现各Token之间的信息交换。
最后通过残差和Layernorm,将TokenMixing的结果加回到切分后的原始Token上。实现了特征Token语义差异性和跨特征全局交叉信息的融合。
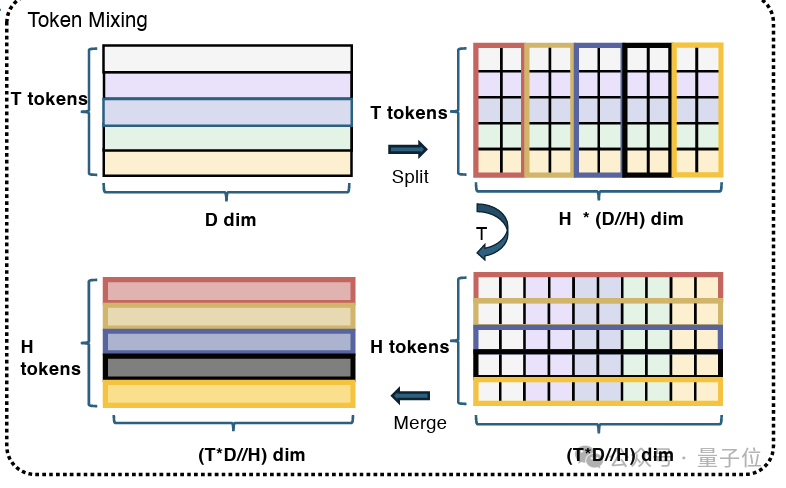
对比Transformer中的Self-Attention做Token间信息交互的方法,TokenMixing有几个优势。
计算高效:首先,由于只是对向量片段做拼接重排,是一个无参的操作,计算上非常简单高效,可视作张量维度的变换,对GPU来说开销极低。
降低了学习难度:实验表明,在推荐数据上这种Parameter-Free的Token混合性能反而优于Self-Attention。
研究团队猜想,相比于LLM所有的Token都来源于同一个语义空间,推荐场景里各Token对应的特征语义差异极大,Attention那套通过点积算相似度的方法会因为组合爆炸问题反而难以学到有效关系。
显存和memory IO更友好:Self-Attention需要产出H个Token平方的attention weights矩阵。会造成明显的Memory Bound和显存占用,会影响模型的MFU和扩展。
Per-Token SparseMoE:语义子空间下的差异化建模
Transformer中的All-shared FFN并不适用于推荐的数据特性,这将会导致模型参数容量增加比例远小于模型的计算量增加比例。
为了建模推荐数据输入的差异性,研究团队进一步引入参数的差异化,并且在相同计算量下,大幅提升模型的参数容量,反过来大幅降低单位参数量所需要的计算量,提高ROI。研究者引入了Per-Token SparseMoE的架构。
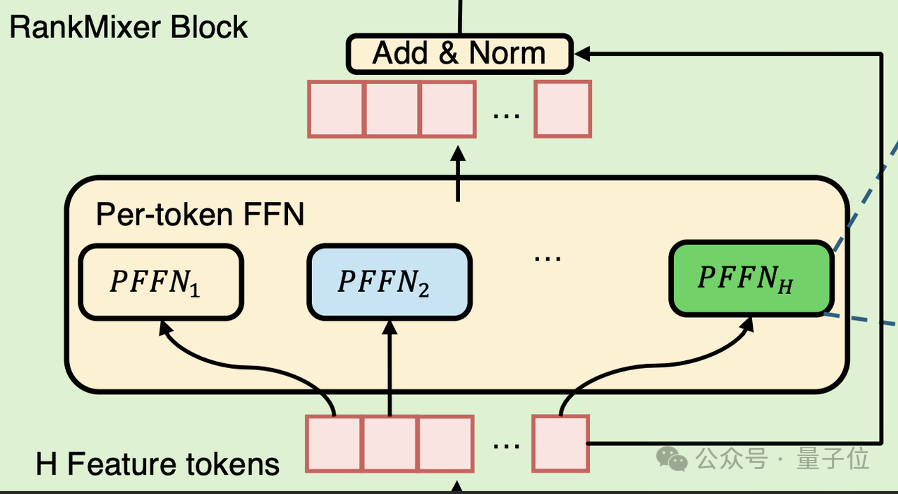
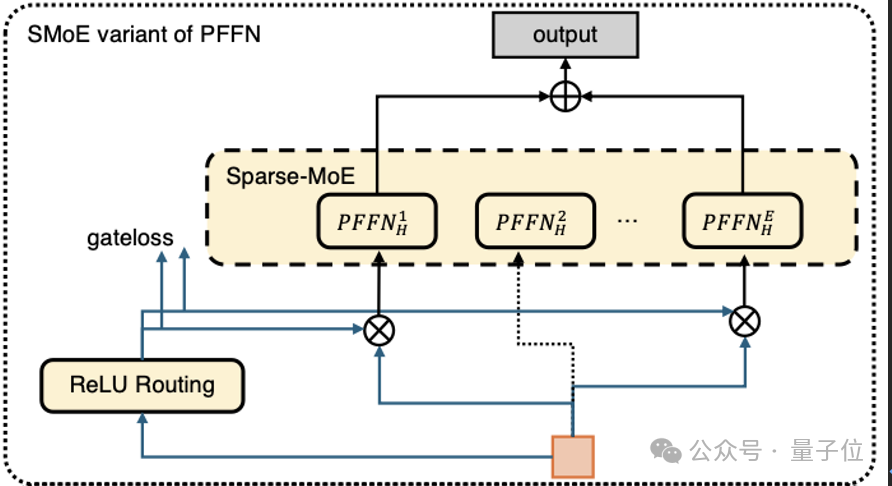
如上图所示研究团队为TokenMixing之后的每个Token配备一个独立的前馈网络(即FFN层),每个FFN可以建模在不同语义视角下的用户推荐兴趣,同时通过参数切分,缓解了传统单一DNN结构中“强特征主导”的问题,让长尾特征信号得到保留和放大。
RankMixer兼顾了Transformer的输入独立(但是参数共享)和MMoE的参数独立(但是输入共享)于一个模型。
此外为了进一步提高模型参数容量和ROI,研究团队将上述逐Token FFN扩展为稀疏专家(Sparse MoE)结构即PerToken SparseMoE,由门控机制动态地为每个Token选择性激活一部分专家,节省了推理的开销。
而针对推荐数据下MoE会遇到的专家训练不均衡问题。RankMixer采用了两项改进:
1、ReLU路由:根据每个Token信息量的不同自适应的学习expert的分配策略。信息量大的Token,动态激活更多专家;
2、DTSI训练:采用“Dense Training, Sparse Inference”(训练时密集、推理时稀疏)的双路由器策略。训练阶段每个专家都能被充分训练,而推理阶段用稀疏路由保证高效。
模型效率提升:参数扩大两个数量级保持推理成本不增加
与线上baseline模型(16M)相比,RankMixer-1B参数规模提高了两个数量级约70倍(从千万级提升到十亿级)。
如何保障推理成本不增加依赖以下几个手段。首先研究团队将推理成本(latency)拆解为以下的公式。

如下表所示,尽管参数量提升了70倍,通过模型设计,一方面大幅降低了3.6倍的FLOPs参数比,使得FLOPs仅增加了20倍。
另一方面提升了10倍的MFU使得推理latency仅增加2倍。最后通过半精度推理和图外优化使得最终推理成本不增加。
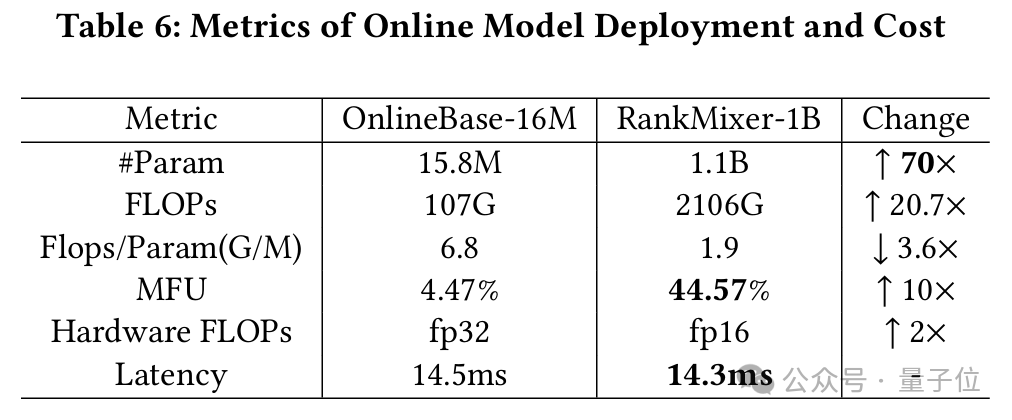
具体优化手段如下表所示
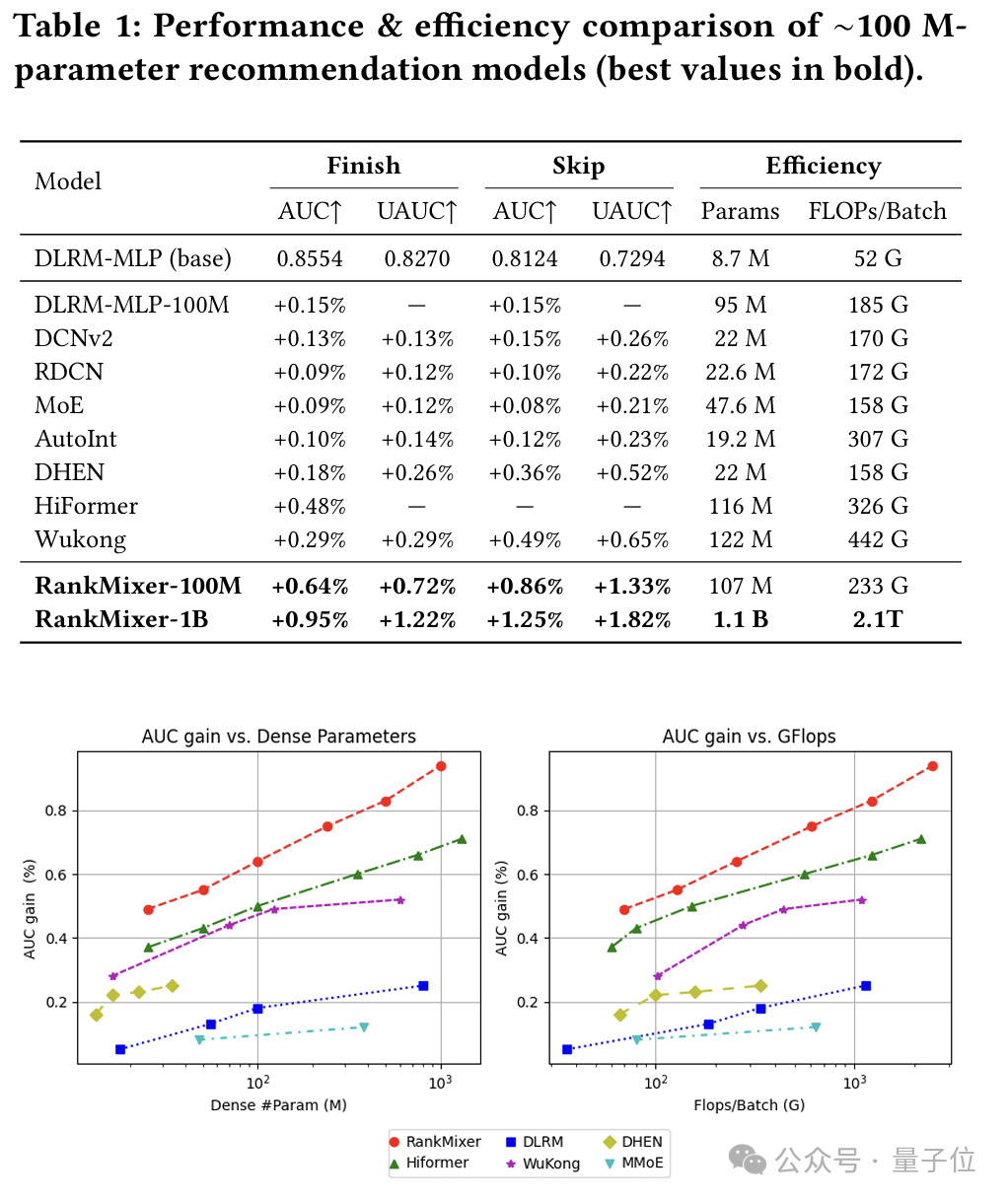
离线指标:在抖音推荐数据集上,RankMixer-1B对比纯DNN累积auc提升超过0.9%,UAUC超过1%。同时对比其他模型结构有更好的scaling law曲线。
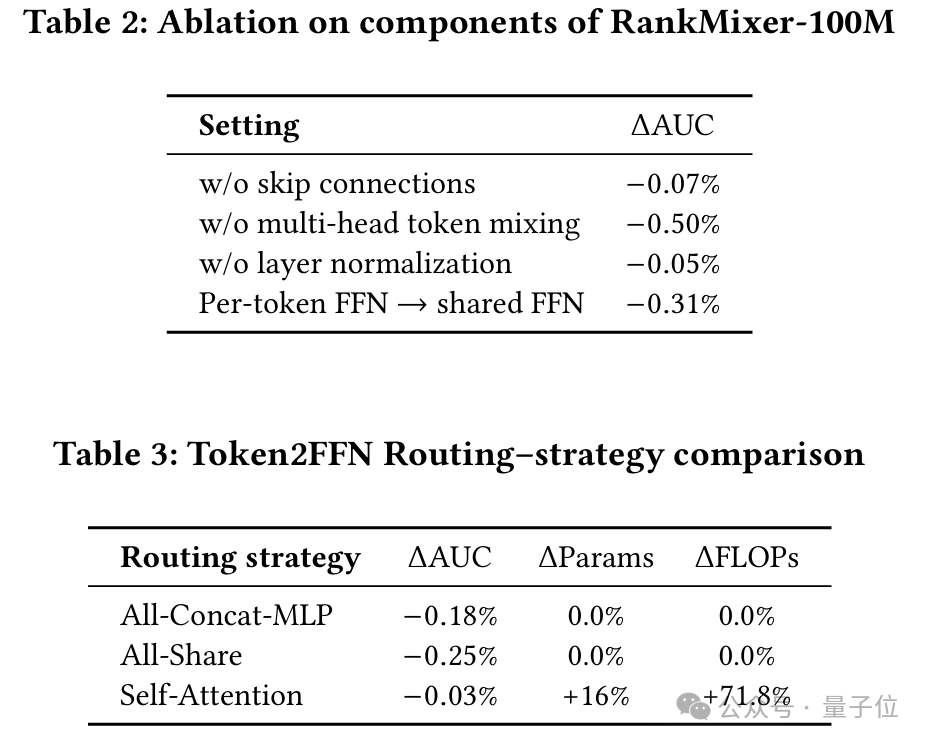
从消融实验来看,模型结构上兼顾输入语义空间的独立性(特征Token化)和参数空间建模独立性(PerToken SparseMoE)是对效果影响最大的。此外对比Self-Attention,TokenMixing的效果和效率也要更优。
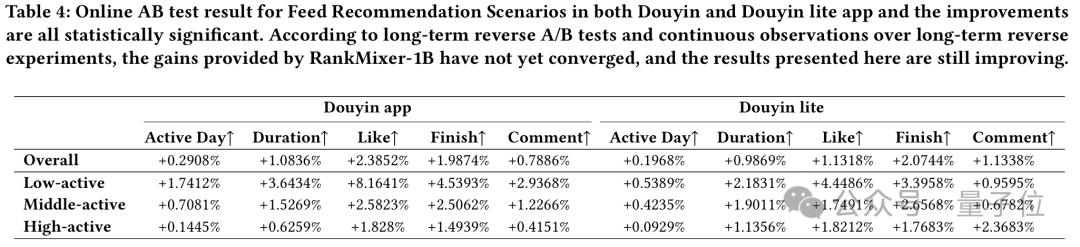
线上效果:研究团队在抖音推荐场景同时进行了长时间的线上A/B测试。结果显示,用RankMixer-1B替换之前全量模型的Dense-16M模型(DNN和Cross结构,auc提升0.7%),业务效果也有明显提升。
在抖音主Feed流中,全面部署1B参数的RankMixer模型并未增加推理开销,却将用户日活跃天数提升了0.3%,人均单日使用时长提升了超过1%。此外在低活用户上提升更加明显反映了模型泛化性的提升。
从研究团队最新的反转继续观察来看,效果收益更大,并且趋势上还远没有收敛。
添加图片注释,不超过 140 字(可选)
此外在广告场景研究团队也进行在线实验验证其效果提升。
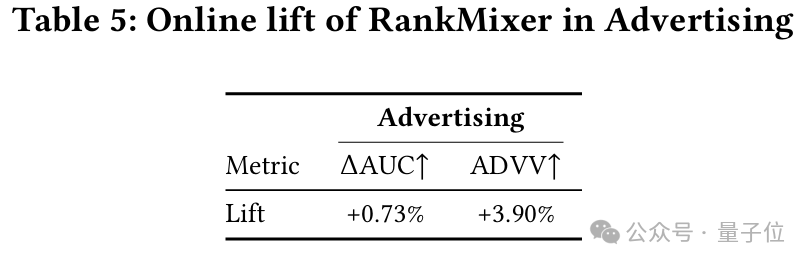
截至论文发表,RankMixer-1B已经全面上线抖音App的首页Feed精排和抖音电商广告精排等几十个字节内部场景,证明了其作为统一通用的精排模型架构的可行性。
RankMixer-1B在实际推荐系统中实践了“大模型”的规模效应。
通过一系列架构创新,研究团队找到了模型效果与计算效率的最佳平衡点:在不牺牲推理效率的前提下,将模型容量提升两个数量级,更好地利用了GPU算力。
这次探索验证了新的技术发展理念越来越重要:
通过对齐硬件特性的模型设计,模型参数规模提升了两个数量级(x70倍)而推理成本几乎不变,这是过去难以想象的效率提升。
算法迭代上不再像以前不断“雕花”堆叠新的低MFU的结构,就像是在马车上加更多的马,速度还是会被最慢的马拖累。因此需要马车换跑车,迁移到一个可扩展的高效大一统的架构。只有发动机的升级换代,才可以让模型和业务跑得更快。
算法工程师也不能只闭门造车,而是算法和infra一起做深度co-design,提升整个机器学习工程基建,“炼丹”也要把炉子烧好,将机器算力充分释放给业务效果。
论文链接:https://arxiv.org/pdf/2507.15551
文章来自于微信公众号“量子位”。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
