# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
gpt5来临前夕,oai疑似发布的小模型gpt-oss 120B的架构图已经满天飞了。
难得openai要open一次,自然调动了我的全部注意力机制。本来以为oai还要掏出gpt2意思意思,结果看到了一个120B moe。欸?!
其中部分模型参数设置,乍一看确实诡异,一沉吟,一细想,和好朋友罗神 @resnet-65536 一讨论,疑惑之处豁然洞开,还是十分舒服的。
想来倒也合理,这样看gpt-oss的真实性还蛮高的。故而今天来简单写一下对模型参数的几个妙妙小观察。
傍晚正打算吃饭,一打开飞来阁fla群《线性注意力恩仇录》[1],就看到了无所不知的群友们发了下图:

还是有些诸如 FP4, sink_kv, swiglu clip之类新鲜小玩意,还挺好玩的
但是让我和罗神最感到奇怪的,还是几个奇怪小参数:
上次看到attention head dim设成64还是前bert时代 , 印象里各位都是128/256很久了。
Attention head dim大小应该如何设置呢?
其实,此事在科学空间亦有记载 关于维度公式“n > 8.33 log N”的可用性分析 - 科学空间|Scientific Spaces[2]
世间万物,不是在kexue.fm记载,就是在fla群亦有记载
@resnet-65536 很快甩给我了这个link。
苏神基于最小熵思想推导出了一个词向量维度公式, ,其中 是词表大小, 就是词向量维度, 大概给出词向量维度的一个下界。
而对于attention机制,其数学上和词向量skip-gram是等价的,故而这个公式同样可以用于注意力机制的head_size选择问题。对于attention, N 就是处理的序列长度, 为了从整个序列中精确定位某个token,从熵视角出发,head dim的下界必须大于某个数。
问题来了,正常LLM预训练seq长度一般设成4096,那么head size起码应该大于 8.33*12 = 99.96才是,实际上大家都取128。
Deepseek MLA更是取了256,这某种意义上, 也是MLA比常规GQA好的一个原因.。越大的head dim确实表达能力越强。
(此事在kexue.fm亦亦有记载 Transformer升级之路:20、MLA好在哪里?(上) - 科学空间|Scientific Spaces[3])
那问题来了,openai为什么取64呢???
如果再看一眼,就会发现openai用了window_size为128的SWA(hh, oai果然还是忘不了他的swa)。
这样每个局部的滑窗序列长度 只有128, 而套用维度公式, , 往上最近的数一恰恰好就是64!
看来openai选64还是有道理的。虽然有点反直觉,但是理论上起码靠谱,dim下去后head num就可以搞得多多的了,利好并行。
乍一看,这两玩意相等是十分荒谬的,一般来说 intermediate 比 hidden的dim肯定都是某个大于1的数,必须要升维,正常取4, 其实可以infra上跑个测速,把这个数调整至2.7左右 (在我模糊的印象里,ds之前某个模型大概mlp ratio就在这里左右)
这个mlp ratio的比值,理论上的理解可以参考为什么transformer的FFN需要先升维再降维?[4]
升到高intermediate 维度主要是为了更好的参数知识表达性,可以拿诸如sae的小玩具去解剖看看(此事在 anthropic经典blog里被反反复复记载,Toy Models of Superposition[5], A Mathematical Framework for Transformer Circuits[6] )
mlp ratio大于1是因为,使用像ReLU这样的激活函数时,如果出现 0值可能会使矩阵降秩(矩阵的秩低于token维度时被低秩压缩,其他激活函数可能有差异)
而降秩到低于 m 的概率是一个组合概率问题(假设输入token的维度为 ,变换矩阵 ):
所以为了使矩阵降秩低于 的概率小,就要求 ,即:必须升维。复用一下原作者程序
# 链接:https://www.zhihu.com/question/665731716/answer/1888209852712600269
import math
def C(n,m):
return math.factorial(n)/(math.factorial(m)*math.factorial(n-m))
def rank_dec_ratio(n,m):
sum = 0
for i in range(m,n,1):
sum += C(n,i)
return 1 - sum/(2**n)
for m in range(1,300,1):
print(m,rank_dec_ratio(2*m,m),rank_dec_ratio(3*m,m),rank_dec_ratio(4*m,m))
#结果如下
#1 0.5 0.25 0.125
#2 0.375 0.125 0.0390625
#3 0.359375 0.091796875 0.01953125
#4 0.3671875 0.0732421875 0.010650634765625
#5 0.3779296875 0.05926513671875 0.005909919738769531
#6 0.387451171875 0.048130035400390625 0.0033054351806640625
升维为原token维度m的3倍及以上时,随着m增大矩阵降秩低于m的概率接近0,而4倍是一个适用范围广且参数量较小的值
当然,如前所述,还有另一种从hardware角度考虑的方式:The Case for Co-Designing Model Architectures with Hardware | Abstract[7]
写个脚本,暴力在经验值区间内搜索最高TFLOPS数的mlp ratio (这里在8/3,也就是llama惯用数值附近暴力网格搜索[bs, h]×[h, 8/3h])
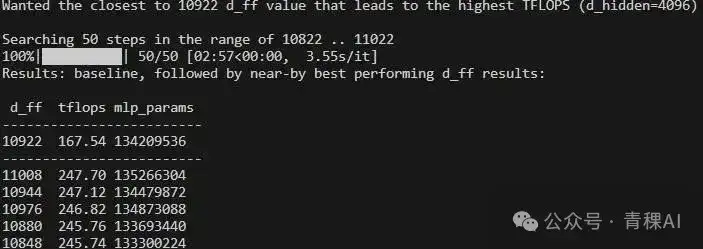
A100上跑的
import torch
from tqdm import trange
### Modify the Search Parameters Begin ###
# this is the hidden_size of the model
d_hidden = 4096
# Now either let the 8/3 ratio give the starting dimension size or choose you own - the 8/3 is
# only a suggestion to compensate for the 3rd additional matrix
d_ff_base = int(8/3*d_hidden)
#d_ff_base = 11008
# batch size - make it larger for small matrices
batch_size = 2**2
# add more profiler iterations for small matrices
num_iterations = 100
# searching range: d_ff_base-distance < d_ff_base < d_ff_base+distance
distance = 100
### Modify the Search Parameters End ###
def benchmark_bmm(b, m, n, k, num_iterations=100, num_matmuls=1):
A = torch.randn((b, m, n)).half().to("cuda:0")
B = torch.randn((b, n, k)).half().to("cuda:0")
C = torch.empty((b, m, k)).half().to("cuda:0")
num_warmup_iterations = 50
start_event = torch.cuda.Event(enable_timing=True)
end_event = torch.cuda.Event(enable_timing=True)
for i in range(num_warmup_iterations + num_iterations):
if i == num_warmup_iterations:
start_event.record()
with torch.no_grad():
for i in range(num_matmuls):
torch.bmm(A, B, out=C)
end_event.record()
torch.cuda.synchronize()
elapsed_time = start_event.elapsed_time(end_event) / (1000 * num_iterations)
flops_per_sec = (2 * b * m * n * k * num_matmuls) / (elapsed_time * 10**12)
#print(f"Elapsed time for {num_matmuls} times {b}x{m}x{n}x{k} : {elapsed_time:.3f}")
#print(f"Throughput (in TFLOP/s) for {b}x{m}x{n}x{k}: {flops_per_sec:.3f}")
#print("-" * 80)
return flops_per_sec
print(f"Wanted the closest to {d_ff_base} d_ff value that leads to the highest TFLOPS (d_hidden={d_hidden})\n")
print(f"Searching {int(distance/2)} steps in the range of {d_ff_base-distance} .. {d_ff_base+distance}")
results = {}
for d in trange(-distance, distance, 4):
d_ff = d_ff_base + d
# find closest div 4 number, pointless to search odd numbers
d_ff -= d_ff % 4
#print(d_ff)
results[d_ff] = benchmark_bmm(batch_size, m=d_hidden, n=d_ff, k=d_hidden, num_iterations=num_iterations, num_matmuls=1)
starting_tflops_per_sec = benchmark_bmm(batch_size, m=d_hidden, n=d_ff_base, k=d_hidden, num_iterations=num_iterations, num_matmuls=1)
print("Results: baseline, followed by near-by best performing d_ff results:\n")
print(" d_ff tflops mlp_params")
print("-" * 25)
print(f"{d_ff_base} {starting_tflops_per_sec:7.2f} {3*d_ff_base*d_hidden}")
print("-" * 25)
cut_off = 5 # how many results do you want to see
for d_ff in list(reversed(sorted(results, key=lambda x: results[x])))[:cut_off]:
print(f"{d_ff} {results[d_ff]:7.2f} {3*d_ff*d_hidden}")
如果hidden size是常见的4096,那intermidiate搜出来最好就是10922, mlp ratio是2.67左右,很合理的
那你openai为什么写1呢?
其实我漏看了一个参数,就是gpt-oss是128expert选4的。每次选中4expert, 4个expert组合拼接成一个大FFN,intermidate应该是4*2088其实,那刚好就是最常见的mlp ratio = 4!
不过根据上面分析可见,这个数字应该还是能进一步优化的(其实也没啥必要...
(这小节,其实算是我们两反应有点迟钝了
游少((21) You Jiacheng (@YouJiacheng) / X[8]指出, openai mlp还是用了bias的,如今确实少见...
看来oai基建不错,大概也没上muon优化器 (上了muon还用mlp bias就有点说不过去了)
让我想起了baichuan的kv shifting 哈哈 KV Shifting Attention Enhances Language Modeling | Abstract[9]
虽然搞了个可学习的kv ,不过两者还是两码事
用了window_size=128的swa, 乘上层数num_layers=36,感受野4608还是大于初始4096 seq len。至于后面用ntk搞到更长的部分,肯定得搞一个桶把窗口外的东西都全局扫一遍,这里就看到了concat了一个额外的kv(sink token=4), 还是比较make sense的
这里理解比较粗浅...128window确实有点小的...
麦子熟了五千次,fp4第一次
nb就完了
(不过ue8是啥?)
想清楚了后面再更新这一块儿
俺是学了不少。再次感谢 @resnet-65536 的快乐讨论。
如果gpt-oss是真的话,只能说,oai技术力没有想象的那么浮夸,一切都在飞来阁的掌握之中!
我时常觉得,FLA群若全员组建公司,可以一夜跃为全球top的大模型公司,sonta.ai!
最后插播一个更好玩的事情:就在我写这篇文章的同时,发现罗神也在同步写几乎一样的文章hh (link指路:OpenAI开源模型gpt-oss-120b架构中大砍维度的两个模块[10])。这样我们一前一后同时发布了,这是本文最妙妙的小观察!
[1] 飞来阁fla群《线性注意力恩仇录》:https://zhuanlan.zhihu.com/p/1915601328211759191
[2]关于维度公式“n > 8.33 log N”的可用性分析 - 科学空间|Scientific Spaces:https://kexue.fm/archives/8711
[3]Transformer升级之路:20、MLA好在哪里?(上) - 科学空间|Scientific Spaces:https://kexue.fm/archives/10907
[4]为什么transformer的FFN需要先升维再降维?:https://www.zhihu.com/question/665731716/answer/1888209852712600269
[5]Toy Models of Superposition:https://transformer-circuits.pub/2022/toy_model/index.html
[6]A Mathematical Framework for Transformer Circuits:https://transformer-circuits.pub/2021/framework/index.html
[7]The Case for Co-Designing Model Architectures with Hardware | Abstract:https://arxiv.org/abs/2401.14489
[8]游少((21) You Jiacheng (@YouJiacheng) / X:https://x.com/YouJiacheng
[9]KV Shifting Attention Enhances Language Modeling | Abstract:https://arxiv.org/abs/2411.19574
[10]OpenAI开源模型gpt-oss-120b架构中大砍维度的两个模块:https://zhuanlan.zhihu.com/p/1934745342089335268
文章来自微信公众号 “ 青稞AI “,作者 涮月亮的谪仙人


【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
