# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当AI智能体(Agent)开发的浪潮涌来,很多一线工程师却发现自己站在一个尴尬的十字路口:左边是谷歌、OpenAI等巨头深不可测的“技术黑盒”,右边是看似开放却暗藏“付费墙”的开源社区。大家空有场景和想法,却缺少一把能打开未来的钥匙。而现在,腾讯AI Lab的《Cognitive Kernel-Pro》研究,递上的可能正是这把钥匙。

在GAIA基准测试中,完胜同级开源对手,并且有一套完整的开源免费解决方案,代码、数据、模型全数公布于GitHub。
并且他们现在已有81颗star。https://github.com/Tencent/CognitiveKernel-Pro
当前最顶尖的AI智能体,特别是那些能像人类研究员一样自主上网、处理文档、分析数据的“深度研究智能体”,其背后的技术壁垒非常高。这导致了一个很尴尬的局面:
正是因为看到了这些困境,研究者们才下定决心要打造一个真正开放、普惠的框架,也就是我们今天的主角 Cognitive Kernel-Pro。
一套开源、免费的“乐高”式解决方案
您可以把Cognitive Kernel-Pro想象成一套用来搭建“AI大脑”的乐高积木,它最大的特点就是开源和免费。研究者们的目标很明确:让任何一个开发者都能用上最前沿的智能体技术,而不用担心被技术或费用卡脖子。
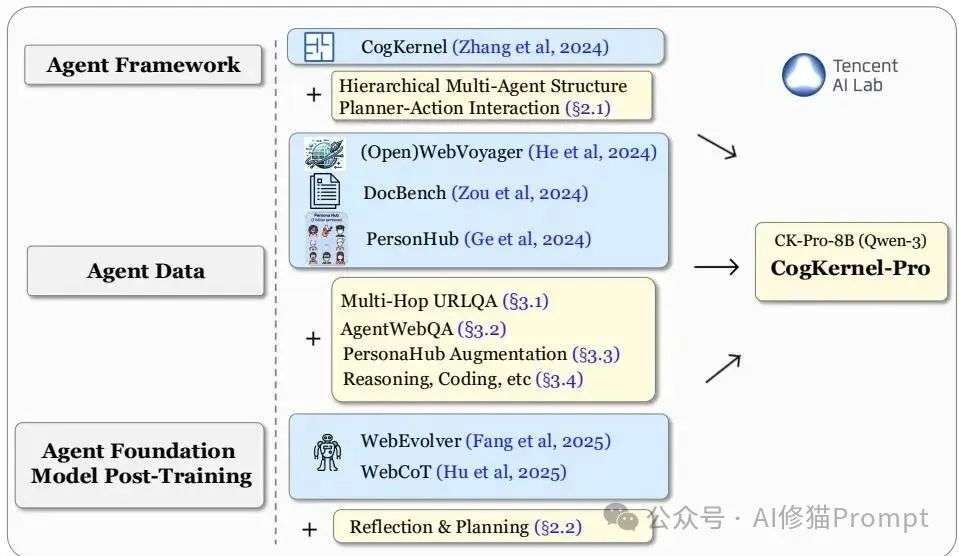
Cognitive Kernel-Pro的技术路线图,它整合了之前多项研究成果,并在黄色部分标示了本次工作的核心创新点。
它的核心设计非常巧妙,采用了一种分层的模块化架构,就像一个高效的项目团队:
这个主智能体是整个系统的大脑,负责接收复杂的任务,然后进行精准地拆解,把一个个子任务分配给最合适的“专家”去处理。它不亲自干活,但对每个专家的能力了如指掌。
这些子智能体是真正干活的。比如:
整个框架的“沟通语言”是Python代码。这意味着,无论是主智能体下达指令,还是子智能体执行任务,都是通过生成和执行Python代码来完成的。它让我们能用最熟悉的方式去理解、控制和扩展AI的行为。
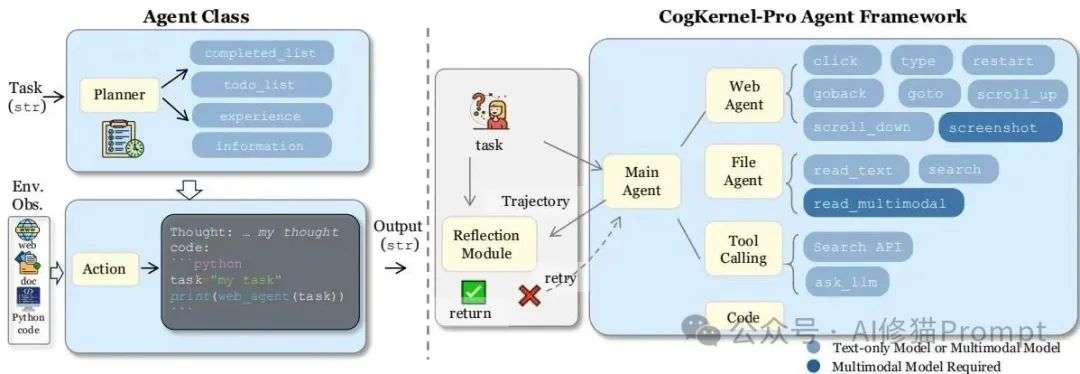
Cognitive Kernel-Pro的框架概览,左侧展示了智能体的核心工作流,右侧则清晰地描绘了主智能体与子智能体之间的层级结构和各自的功能。
一个再好的框架,如果没有高质量的“养料”(训练数据)来喂养,也只是个空架子。我觉得,这篇论文在数据构建上的思路,是其最核心的贡献之一,充满了智慧。
研究者们没有采用传统的“找题给AI做”的模式,而是另辟蹊径,让AI自己给自己出题。这个过程被称为“基于智能体探索的数据构建”,具体操作是这样的:

论文中展示了信息聚合的过程,智能体需要通过计算、排序、分析等操作,才能从多个来源的信息中得到最终答案。
这种方法生成的数据质量非常高,因为它天然地包含了多步推理、信息整合和跨源验证的需求。除了这种核心方法,他们还用到了一个非常聪明的技巧:
在让另一个AI去学习解决这些新生成的问题时,研究者发现,如果直接把正确答案的“中间步骤”或“关键信息”作为提示(Hint)悄悄地塞给它,它的学习成功率会大大提高。当然,这些提示就像是给学生的“小抄”,只在“模拟考试”(即数据收集阶段)时使用,在最终的“正式考试”(即模型训练阶段)前,这些提示会被全部拿掉,以确保模型学到的是真正的解题能力,而不是对提示的依赖。
我们都知道,AI模型在实际运行时,尤其是在面对充满不确定性的真实网络环境时,很容易“犯错”或“走神”。为了让智能体表现得更稳定、更可靠,研究者们设计了两套非常实用的优化流程。
这就像是给AI装上了一个“复盘”模块。每当智能体完成一次任务后,它不会立刻提交答案,而是会先启动“反思”程序,从四个维度对自己刚才的表现进行严格的自我审查:
一旦发现任何一项不达标,智能体就会判定这次任务“不合格”,然后自动重试,直到拿出一个自己满意的结果为止。
如果说“反思”是“吾日三省吾身”,那么“投票”就是“三个臭皮匠,顶个诸葛亮”。这个机制非常简单粗暴但有效:让智能体把同一个任务,用不同的思路尝试好几次(比如3次)。
完成后,它会把这几次的全部过程和结果摆在一起,然后利用上面提到的“反思”标准作为投票依据,选出那个它认为最完美、最可靠的轨迹作为最终答案。论文里举了一个生动的例子:当被问及某位歌手最早的专辑时,一次尝试可能找到了2000年的专辑,另一次尝试找到了1990年的。通过投票对比,智能体就能轻易判断出1990年的答案更准确。
理论说得再好,终究要看实际效果。研究者们选择了业界公认的、难度极高的GAIA基une测试来检验Cognitive Kernel-Pro的实力。这个测试集就像是AI智能体的“高考”,全面考察它们在网页浏览、文件处理、多模态理解等多种复杂任务上的综合能力。
为了证明自己的含金量,Cognitive Kernel-Pro不仅要和同级别的开源项目比,还要敢于和那些含着“金钥匙”出生的闭源商业系统叫板。
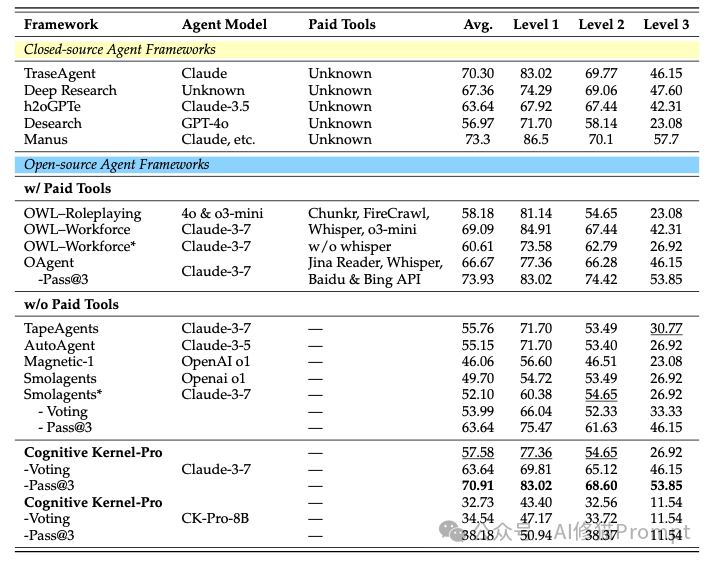
实验结果真的挺给力,可以说是在开源免费这条赛道上取得了压倒性的胜利
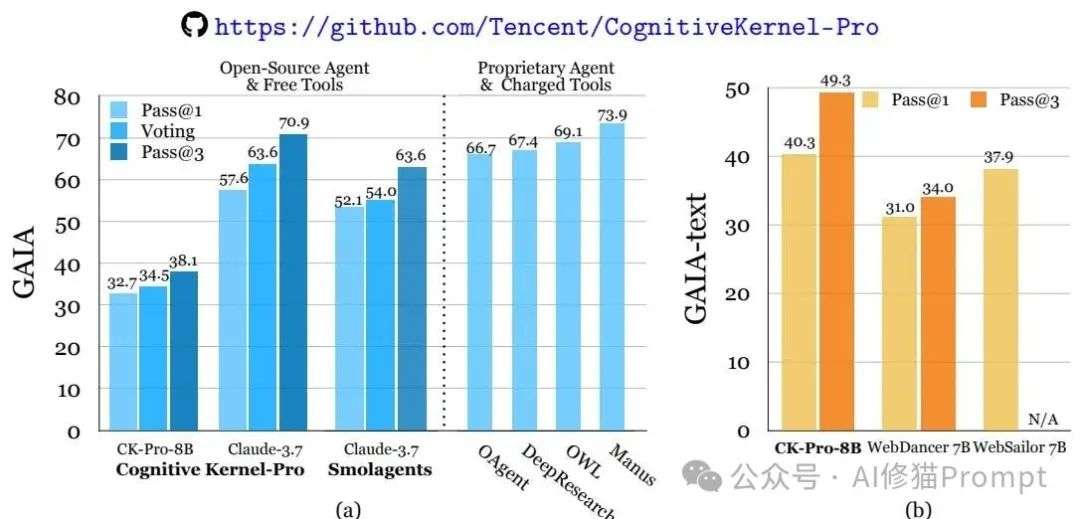
GAIA基准测试性能对比。左图展示了Cognitive Kernel-Pro在使用免费工具的情况下,与使用付费工具的系统的性能对比;右图则显示了其8B模型相较于其他7B模型的优越性。
说了这么多,这项研究对我们的实际工作到底有什么帮助或启发呢?
Cognitive Kernel-Pro不仅仅是一个开源项目,它更像是一本详尽的、开源的“AI智能体开发指南”,它告诉我们,即使不依赖昂贵的闭源API和付费工具,我们同样有机会打造出第一梯队的AI智能体。
文章来自于微信公众号“AI修猫Prompt”。


【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
