# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
就在刚刚,昆仑万维发布了 Mureka V7.5,一个专门为中文升级的音乐大模型。

老实说,这两年 AI 做音乐已经卷出了天际——Suno、Udio、Riffusion,一个比一个能唱,特别是英文歌,人声真假难辨,节奏旋律也都挑不出太大毛病。
所以当我看到 Mureka 这个更新的时候,原本也没太在意。直到我注意到一件事:
和很多模型强调“多语言支持”“风格多样化”不同,Mureka 这次反而把重点放在了「中文音乐表现」这件事上。
这一下我就来了兴趣。这或许是第一次,有人真的把「中文歌」放在了舞台中央,作为一个目标去打磨。
光有情怀可不行,我们上手实测一下看看实力。
老规矩先放网址:
https://www.mureka.ai(需要魔法)
打开「创作音乐」页面,中间栏会看到有三种生成模式:「简单」、「高级」、「音频编辑」
它们的区别大概可以这样理解:
为了给大家做一个完整的演示,我这里选择的是高级模式。
生成流程也很简单,跟官方的三步法基本一致:

来说几个我们实测时印象最深的 case。
比如说,民谣。
我们写了首《凌晨两点的火车站》,送给那些提着行李、还没想好下一站的人。旋律轻快得像夜风掠过站台,歌词一开口就带点温度。我们把它丢进市面上能找到的 AI 唱歌模型里来回试,最后还是这版听着最像深夜有个人在给你清唱。
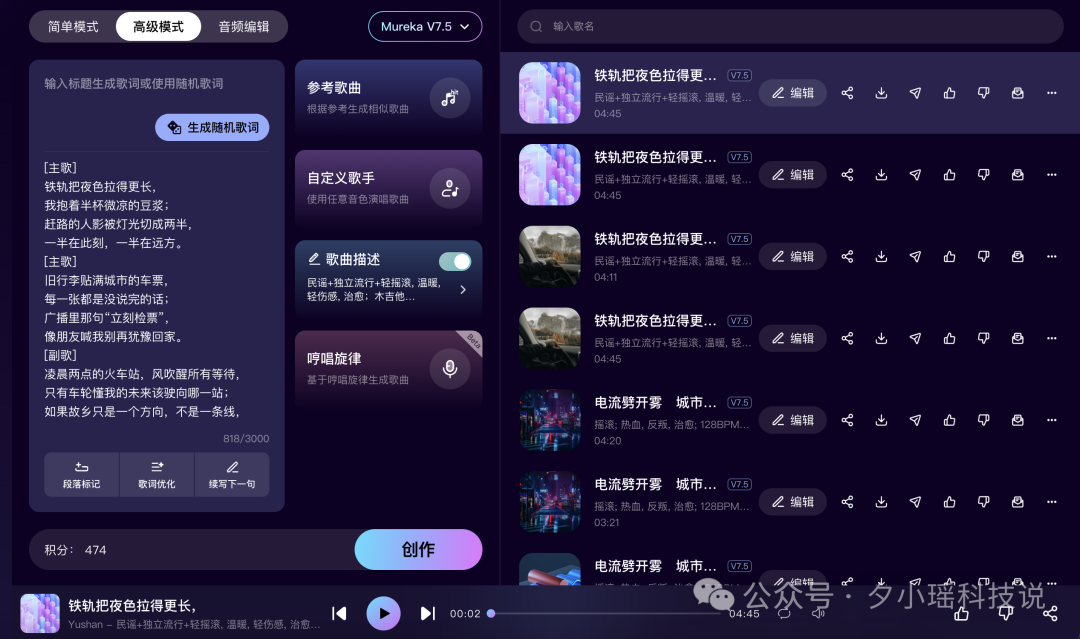

而换成 R&B,整首歌的氛围立马变了。

好甜,听着歌感觉自己已经恋爱了。
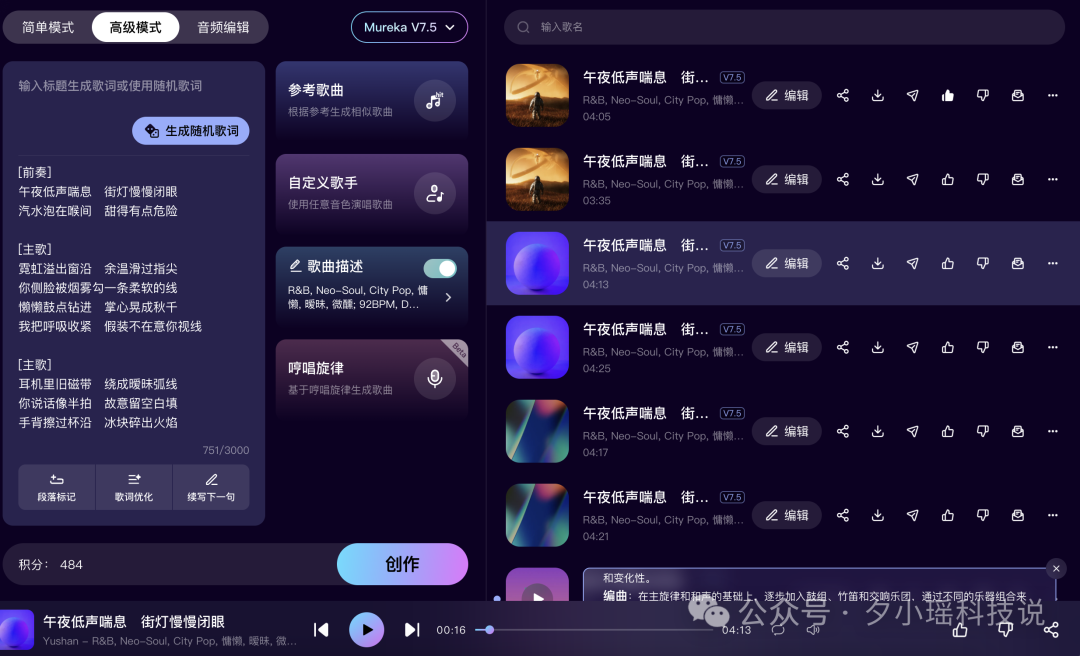
再切到摇滚,前奏电吉他直接炸开,整个编曲冲得很猛,人声情绪也激烈许多。

说真的,整体的输出结果超出我的预期。我专门去翻了下他的技术报告。
这张图,是四个主流模型在「中文歌曲」生成场景下的主观测评分数。统一输入歌词和提示,每个模型各出四首歌,听众盲听投票。
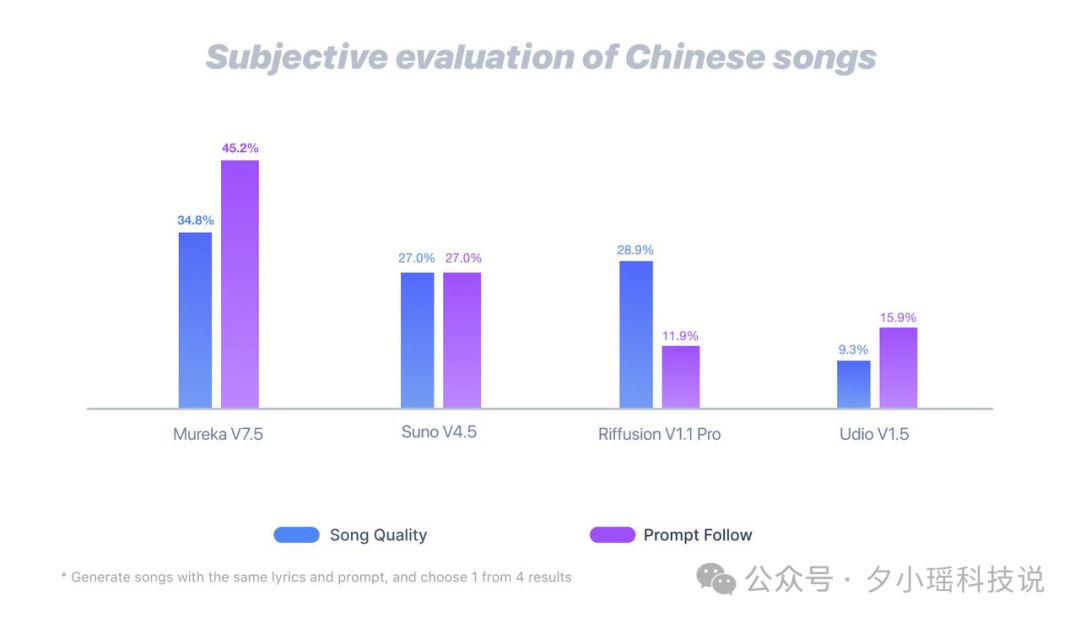
Mureka V7.5 在两个维度都拿下第一:
这是目前唯一一个能在「旋律打动人」和「内容贴合主题」两个方面同时拉开差距的模型。
那它为什么能做到?
因为 Mureka V7.5 在底层做了三件事:
我们拿 Suno V4.5 和 Mureka V7.5 对比一下你就懂了。

你听到的自然,是因为它懂得“适可而止”,知道什么时候要留白,什么时候不用炫技。
在 Mureka V7.5 的发布里,除了音乐模型本身,昆仑万维还同步发布了一个重要的语音合成技术:MoE-TTS(Mixture-of-Experts Text-to-Speech)。
而它非常重要。可以说,MoE-TTS 是支撑 Mureka V7.5 能唱出“更像人”的关键语音底座之一。
MoE-TTS 的最大创新在于,它将语音控制从传统的标签式模板(如情感=高兴、年龄=青年)彻底解放,转向了开放式自然语言建模。用户不再需要在预设参数里选择,而是可以直接用日常语言来描述目标声音,比如“清澈的少年音带磁性尾韵”这类复杂的、多维度的感知描述。
这背后,是一个由大语言模型(LLM)驱动的语义解析系统。它能够将自然语言拆解为一组高维表达向量,交由多个语音专家模块(Speech Expert Modules)分别建模语音风格、节奏、语气、发音等维度,并最终通过模态路由器(Modality Router)动态聚合输出结果,实现了真正意义上的“按语言思维驱动声音表现”。
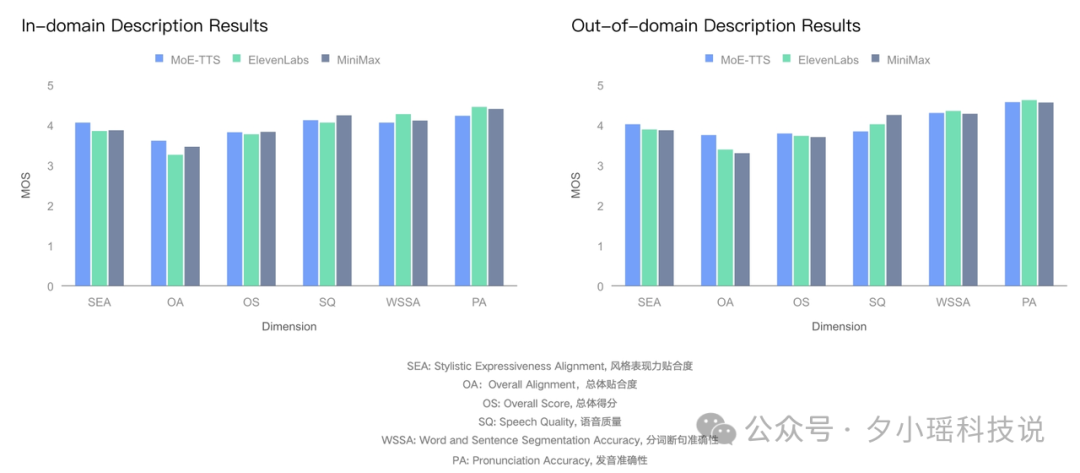
从评测结果来看,MoE-TTS 在两类任务上都表现出显著优势:
我们可以拿一个 demo 更直观地感受一下:
prompt:美国男演员,带有纽约口音,多才多艺,表达能力强,语速富有活力,充满魅力与感染力,吸引着听众的注意。
Mureka V7.5:

不仅实现了美式口音的模拟,语调起伏和节奏变化也精准贴合“吸引听众”这一目标语义。
11labs:

音色平淡,缺乏应有的节奏张力。
MiniMax:

未展现出“个性表达”的能力,缺乏对 prompt 的风格理解。
技术架构上,MoE-TTS 抛弃了传统“一锅炖”式的统一建模逻辑,改为文本与语音解耦 + 多专家并行建模策略。在 Transformer 框架下,各语音专家独立聚焦不同表达维度,参数分别优化,避免模态间互相干扰,显著提升了对模糊、比喻、情绪迁移等复杂语言的理解力。
而且,这种“冻结文本语义 + 多路语音专家”的结构还带来了一个重要收益 —— 语义保持能力更强。模型在微调过程中不会破坏原有的语言表示,从而实现跨模态语义迁移时的“知识零损失”,这是传统 TTS 系统很难做到的。
MoE-TTS 并非孤立成果,而是昆仑万维在「SkyWork AI 技术发布周」上的压轴一作,也是一整套多模态技术体系的收官拼图。
技术之外,MoE-TTS 真正打开的是一片应用空间。它不仅服务于 Mureka 的音乐生成,也天然适配以下这些典型场景:
Mureka O1 模型与 Mureka V6 模型自 3 月底发布以来,收获了全球用户的广泛好评,新增注册用户近 300 万。
自 8 月 11 日起,他们连续五天推出涵盖视频生成(SkyReels-A3)、世界模拟(Matrix-Game 2.0)、统一多模态模型(Skywork UniPic 2.0)、智能体(Deep Research Agent v2)等关键方向的模型成果,持续推进具备生成、理解与交互能力的多模态架构,同时延续了一贯强调研发开放性与协作共享的技术理念。
说到底,MoE-TTS 并不是为了好听而好听。它更像是昆仑万维在做中文音乐这件事上的一个底层工程。
因为你只要认真做一首中文歌就会发现——光有旋律没用,AI 唱得再准、节奏再对,如果咬字不地道、语气不到位、情绪不贴脸,那首歌听起来就是“有点怪”。
而这个“怪”,不是靠调节 EQ 或增加混响能解决的,它是语言与文化之间天然的隔阂。
AI 在大多数赛道卷的是“效率”“准确率”“生成力”。但音乐赛道不一样,它卷的是“谁的文化留下来”。
如果没有人愿意为中文音乐单独修一条路,那么在未来的 AI 世界里,我们可能连一首像样的歌都没有资格被记住。
这一次,Mureka V7.5 是在拉着中文音乐往前站了一步。它没有去迎合所有语言、风格、市场,而是选择把注意力,扎扎实实地放在了中文音乐身上。
你能听见它唱得越来越像我们。那不是因为模型聪明了,而是因为,终于有一群人,在算力之外,愿意花时间、花心思,把中文的旋律、情绪、韵脚和呼吸,一点点教给 AI。
有些旋律,真的只有中文能唱。
也许,有些歌,AI 也该学会,闭上眼睛去唱
文章来自于微信公众号“夕小瑶科技说”,作者是“夕小瑶编辑部”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
