# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
英伟达发布全新架构9B模型,以Mamba-Transformer混合架构实现推理吞吐量最高提升6倍,对标Qwen3-8B并在数学、代码、推理与长上下文任务中表现持平或更优。
万万没想到,现在还紧跟我们的开源模型竟然是英伟达。
刚刚,英伟达发布了一个只有9B大小的NVIDIA Nemotron Nano 2模型。
对标的是业界标杆,千问的Qwen3-8B,但这个模型是一个完全不同的混合架构。
用英伟达的说法,这是一款革命性的Mamba-Transformer混合架构语言模型。
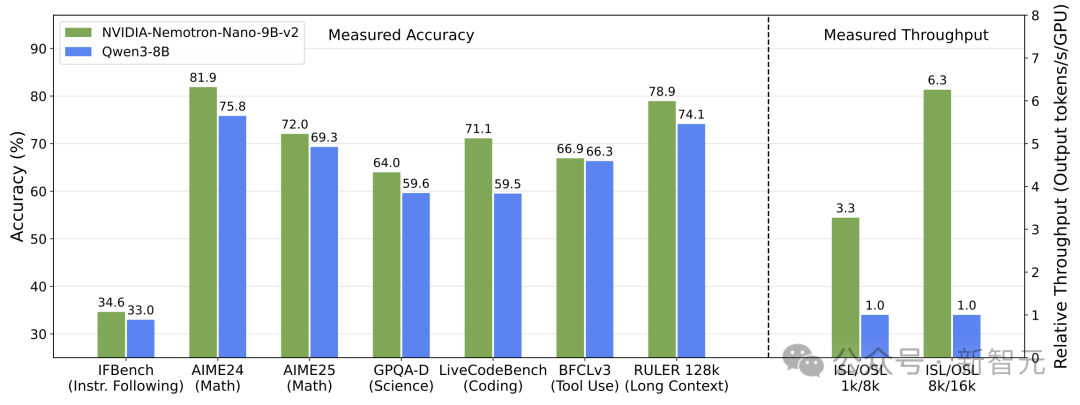
在复杂推理基准测试中实现了和Qwen3-8B相当或更优的准确率,并且吞吐量最高可达其6倍。
它的诞生只有一个目标:在复杂的推理任务中,实现无与伦比的吞吐量,同时保持同级别模型中顶尖的精度!
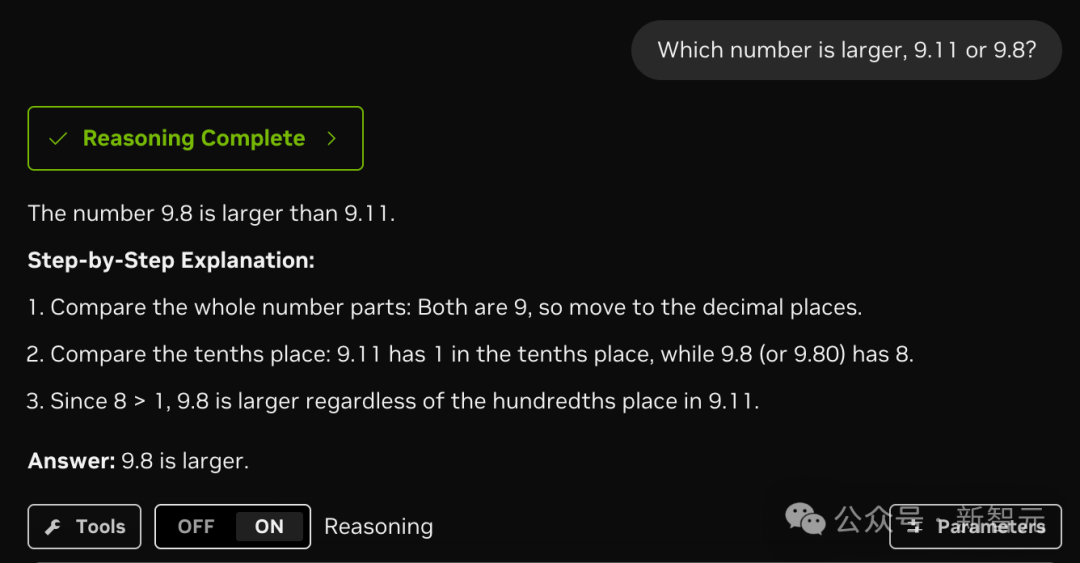
在官网简单测试一下,一些经典问题,都能答对。
英伟达还做了3个小工具,可以实时查天气、描述哈利波特里的角色和帮你想颜色。
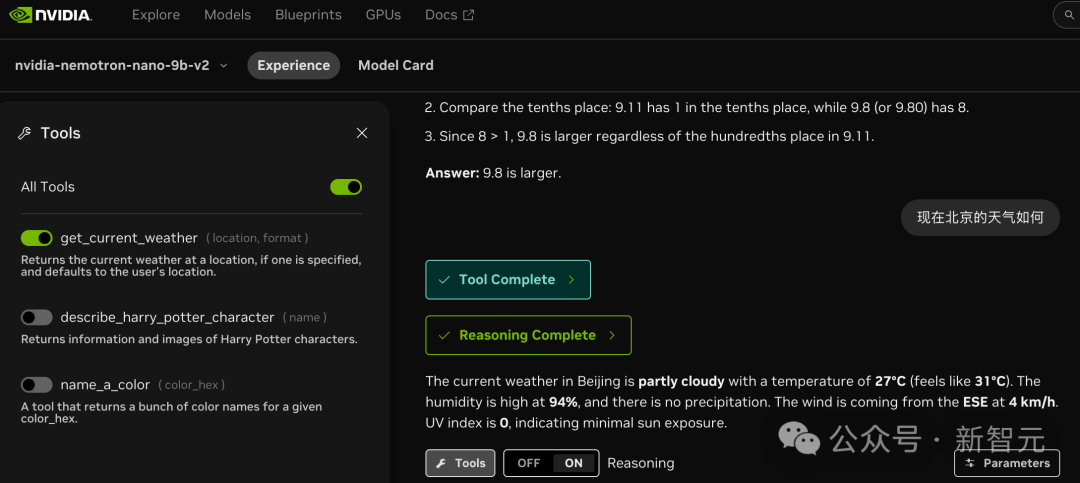
不过9B模型还是小了点,当你问「SamAltman、马斯克和黄仁勋谁更值得信任」时,模型会犯蠢把马斯克翻译成麻克,哈哈哈。
而且,也不愧是亲儿子,模型认为黄仁勋最值得信任。


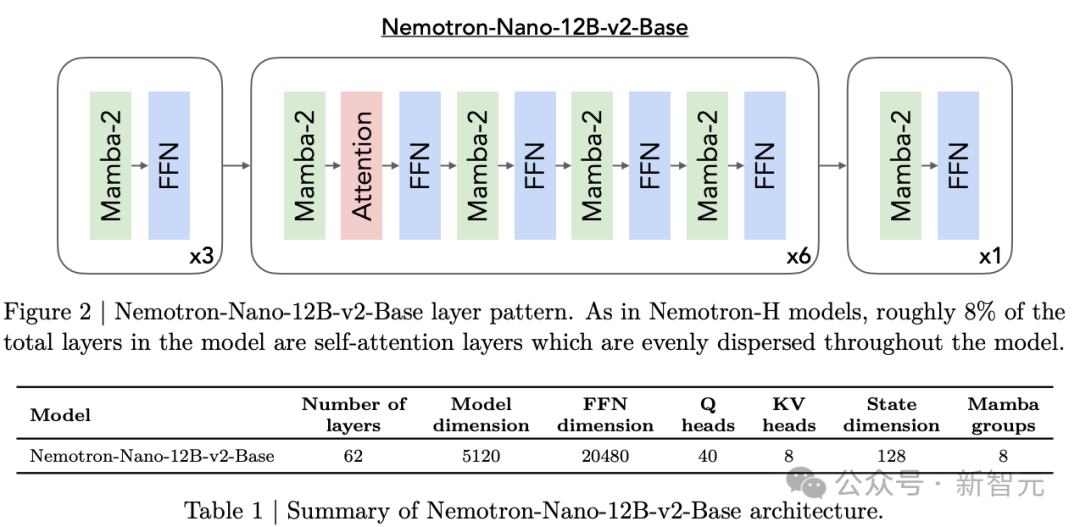
Nemotron-Nano-9B-v2的强大,源于其创新的Nemotron-H架构。
用闪电般快速的Mamba-2层,替换了传统Transformer架构中绝大多数的自注意力层。
当模型需要进行长篇大论的思考、生成复杂的长思维链时,它的推理速度得到了史诗级的提升!
我们都知道Transformer架构,但是这么年过去,有没有新架构出现?
有的。
比如Meta公开推进JEPA(联合嵌入预测架构)和大概念模型(LCMs)、状态空间模型(就是Mamba)、记忆模型或扩散语言模型等。

谷歌DeepMind在Titans、Atlas、Genie3以及diffusion-based模型等方向投入了约50%研究力量。
OpenAI虽然嘴上说着有信心训练到GPT-8,但很可能也在储备新架构。
而根据Reddit社区的讨论,Ilya的SSI最可能就是用全新的架构,但是什么,还没人知道。
Mamba是一种完全无注意力机制的序列建模架构,基于结构化状态空间模型(SSMs)。
通过「选择性机制」根据当前输入动态调整参数,从而专注于保留相关信息并忽略无关信息。
在处理超长序列时,Mamba的推理速度据称可比Transformer快3–5倍,且其复杂度为线性级别,支持极长的上下文(甚至达到百万级token)。
Transformer虽然效果出众,但在处理长序列时存在显著的计算和内存瓶颈(自注意力机制导致的O(n^2)规模)。
而Mamba擅长在长上下文中高效建模,但在「记忆复制(copying)」或「上下文学习(in‑contextlearning)」等任务上可能稍显不足。
NemotronNanov2的训练按照下面几个步骤:
· 「暴力」预训练
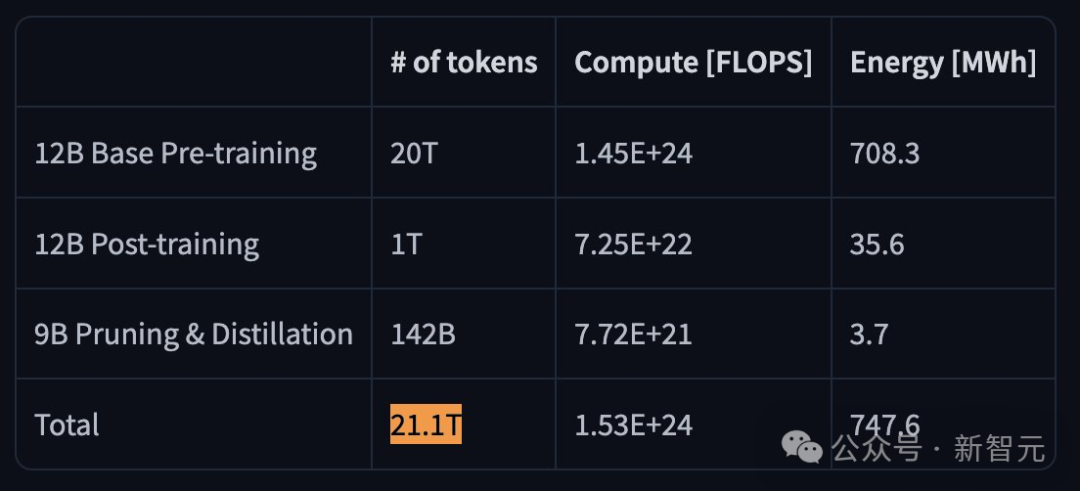
首先在一个拥有20万亿Token的海量数据集上,利用先进的FP8训练方案,锻造出一个120亿参数基础模型——Nemotron-Nano-12B-v2-Base。
这听着就非常像DeepSeek-R1:DeepSeek‑R1-Zero是直接基于DeepSeek‑V3-Base进行纯强化学习训练的初始模型。
而DeepSeek‑R1则在此基础上加入了监督微调作为冷启动,再用强化学习精炼,从而获得更好的可读性与性能。
Nemotron-Nano-12B-v2-Base的预训练,涵盖高质量网页、多语言、数学、代码、学术等数据,重点构建了高保真的数学和代码数据集。
· 极限压缩与蒸馏
结合SFT、DPO、GRPO、RLHF等多阶段对齐方法,提升了推理、对话、工具调用与安全性。
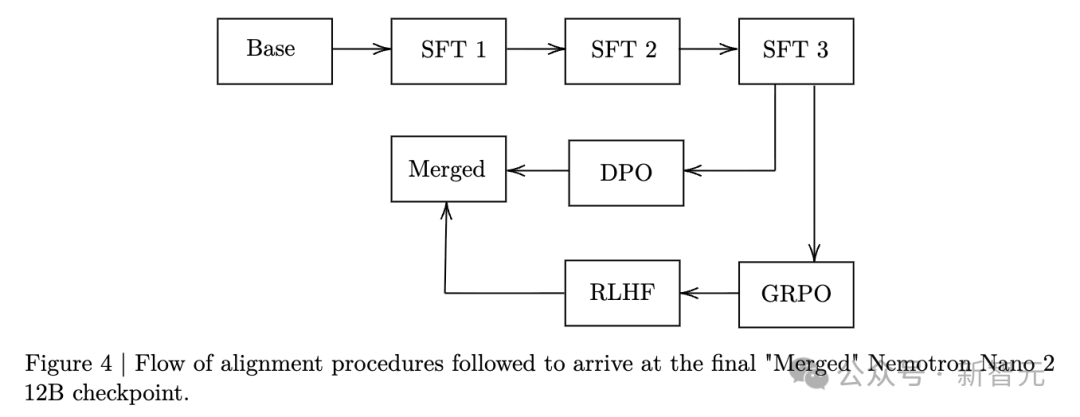
完成对齐后,祭出Minitron策略,对这个120B参数的模型进行极限压缩与蒸馏。
Minitron策略是一种由NVIDIA提出的模型压缩方法,主要通过结构化剪枝(pruning)与知识蒸馏(distillation)来实现对大型语言模型的高效压缩与性能保持。
· 最终目标
通过Minitron剪枝与蒸馏,将12B基础模型压缩为9B参数,确保单张A10GGPU(22GiB)即可支持128k上下文。
是骡子是马,拉出来遛遛!
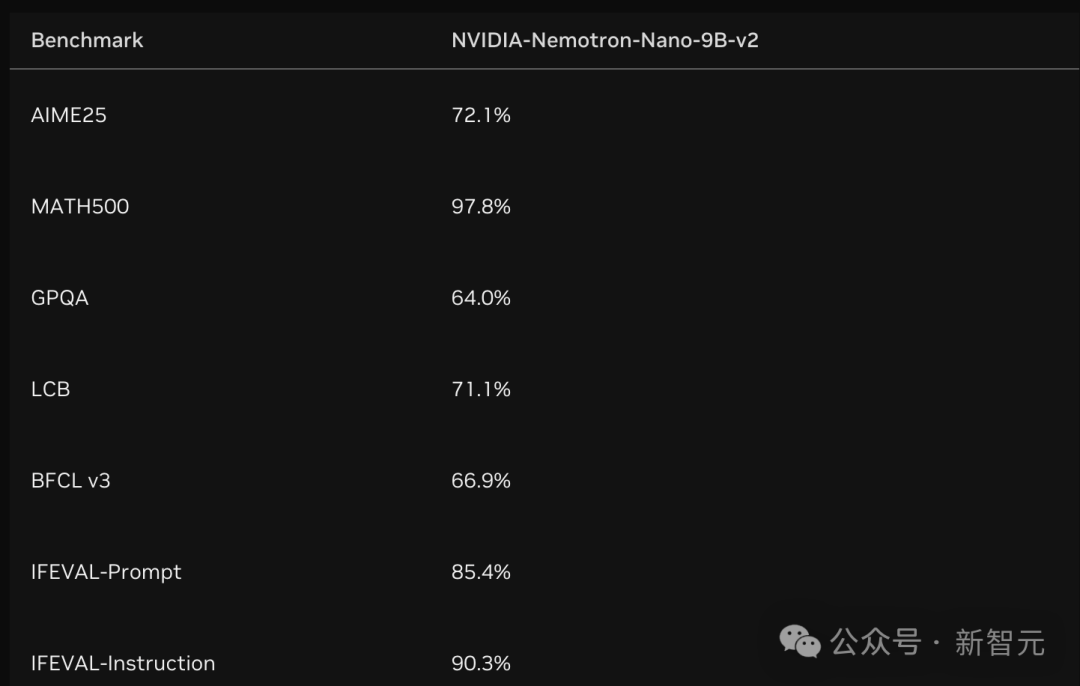
与Qwen3-8B等同级别强手相比,Nemotron-Nano-9B-v2在各大推理基准测试中,精度平起平坐,甚至更胜一筹!
在数学(GSM8K、MATH)、代码(HumanEval+、MBPP+)、通用推理(MMLU-Pro)、长上下文(RULER128k)等基准测试中表现优于或持平同类开源模型(如Qwen3-8B、Gemma3-12B).
并在8k输入/16k输出场景下实现6.3×吞吐量提升。
英伟达宣布在HuggingFace平台上,全面开放以下资源:
正在HuggingFace上发布以下三个模型,它们均支持128K的上下文长度:
除了模型,英伟达表示我们的数据集也很强,并开源了用于预训练的大部分数据。
Nemotron-Pre-Training-Dataset-v1数据集集合包含6.6万亿个高质量网页爬取、数学、代码、SFT和多语言问答数据的token,该数据集被组织为四个类别:
最后是感慨下,Meta作为一开始的开源旗帜,现在也逐渐开始转向闭源,或者起码是在Llama上的策略已经被调整。
目前真正在开源领域努力还是以国内的模型为主,虽然OpenAI前不久也开源了两个,不过雷声大雨点小。
英伟达虽然一直卖铲子,但也静悄悄的发布了不少开源。
感兴趣可以在如下网址体验,除了英伟达自家的,很多开源模型都能找到。
模型体验网址:
https://build.nvidia.com/nvidia/nvidia-nemotron-nano-9b-v2
参考资料:
https://research.nvidia.com/labs/adlr/NVIDIA-Nemotron-Nano-2/
文章来自于微信公众号“新智元”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
