# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
离开 Seed 后,要赋能 AI 情感陪伴产品的记忆系统

Memory 一直是 AI 产品的技术「痛点」和必争之地。因为决定用户留存,很多有野心的创业者在思考如何借助 AI 长期化时,都会聚焦 AI + Memory 领域。
最近,Memory 技术新框架 MemU 在 GitHub 上的开源项目,获得了很多关注,2 周内获得了 1.4K Star。其在 Locomo 数据集所有推理任务中平均准确率达到 92.09%,成本也大幅降低。
今天,「十字路口」与 MemU 的创始人陈宏进行了一场深度访谈,他向我们展示了:一个不擅长做产品的技术客,如何帮其他团队做出真正好的新一代情感陪伴产品。
👦🏻 Koji
年龄?
👦🏻 陈宏
93 年
👦🏻 Koji
毕业院校?
👦🏻 陈宏
本科山东大学,硕士博士东京大学 NLP 方向。
👦🏻 Koji
创业前,做过什么?
👦🏻 陈宏
在 TikTok 客服机器人,以及后来在字节 Seed 训练大模型,曾经也是豆包和猫箱 Memory 的算法负责人。
👦🏻 Koji
一句话介绍公司/产品?
👦🏻 陈宏
MemU 是一个面向长期情感陪伴、对用户的记忆管理系统。与其他 Memory System 的区别是,我们采用了「文件系统」作为 Memory 的载体,然后使用一个记忆管理员 Agent 来管理用户的记忆文件系统,以达到更加准确和高效地召回,并且通过优化手段大量降低使用成本。
MemU 官网:https://memu.pro/
👦🏻 Koji
收入和利润?
👦🏻 陈宏
产品刚发布,现在已经开始在和 B 端接触。
👦🏻 Koji
最新的融资和估值情况?
👦🏻 陈宏
暂不披露。
👦🏻 Koji
团队规模?
👦🏻 陈宏
我们团队现在有 6 个全职同学,分别来自我之前的学校、公司,以及开源社区。另外还有一些兼职朋友在帮忙,以及技术和运营方面的顾问提供支持。
👦🏻 Koji
你如何快速向用户安利 MemU?
👦🏻 陈宏
如果你开发的产品对用户的长期记忆强依赖(助手、角色扮演、OC、教育、陪伴玩偶等等),就可以来找我们。
👦🏻 Koji
为什么选择做 MemU?
👦🏻 陈宏
我在 Seed 和后来在豆包、猫箱做的都是情感陪伴方向的产品。说来也挺神奇的,我们一开始对标 Pi.ai,结果 Pi 倒了;后来对标 Character.AI,Character.AI 也倒了。基本上对标谁,谁就倒闭。
情感陪伴这个方向现在市场上擦边的产品确实越来越多。但我还是很看好长期情感陪伴,觉得一定会有更好的产品出现。
从 Seed 离职后我尝试过自己做产品,后来发现自己并不是做产品的料。于是换了个思路——既然我不擅长做产品,就帮助其他有同样理想的朋友们去做。所以我选择做 Memory Service,这是长期陪伴产品里最重要的一块,希望能帮大家做出真正好的新一代情感陪伴产品。
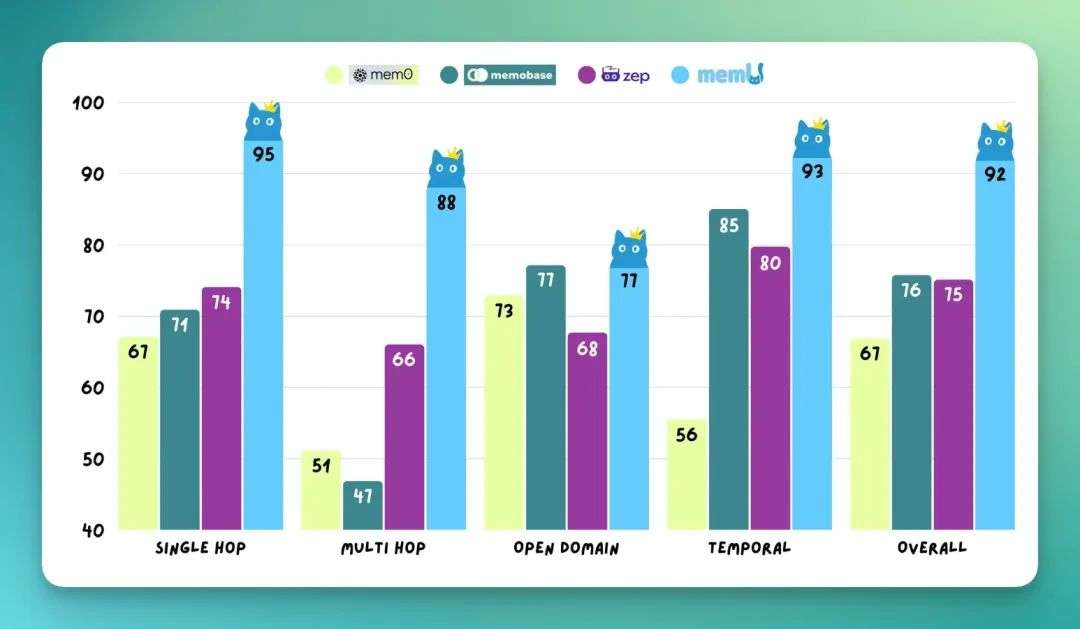
MemU 在 Locomo 数据集的所有推理任务中平均准确率达到 92.09%
👦🏻 Koji
你提到「自己不是做产品的料」,转而做底层 Memory 服务。这种自我认知是怎么形成的?
👦🏻 陈宏
离职后和朋友一起搞独立开发,尝试了不少线上产品。后来发现一个问题——我产品设计能力不行。可能是搞算法久了,总想着怎么把技术怼进产品,做得越炫越好,但反而不知道用户真正需要什么。
折腾一段时间后和一些 PM 朋友交流,才明白自己确实不太擅长做 to C 的东西,产品 Sense 差点意思。
👦🏻 Koji
两年前你在 Seed 服务豆包、猫箱做 Memory System,现在因为模型和技术的进步,和当时相比有什么区别?Memory 是变得更重要,还是被模型能力覆盖了?
👦🏻 陈宏
我从 23 年 7 月开始负责 Seed Memory 算法部分,说实话,从那时到现在市面上的 Memory 方案基本没啥变化。当时就觉得这套方案不太对劲——换 GPT-4、GPT-5,甚至 Claude,对现有的 Memory Solution 提升都不大,因为框架本身就没有 Scale Up 的能力。
最近 Agentic 能力的提升给了我们新的灵感。我们想,为什么不把 Memory 映射成文件系统呢?记忆的记录、修改、删除、读取,不就是文件操作吗?
学术界和工业界有人做过文本记录的 Memory,但把这个概念用在 Agent 对用户的记忆上,还算是新尝试。文件系统特别适合做 Memory 载体,因为它天然支持分类、引用、搜索和遗忘机制。MemU 的记忆 Agent 要做的,就是帮用户自动完成这些操作。
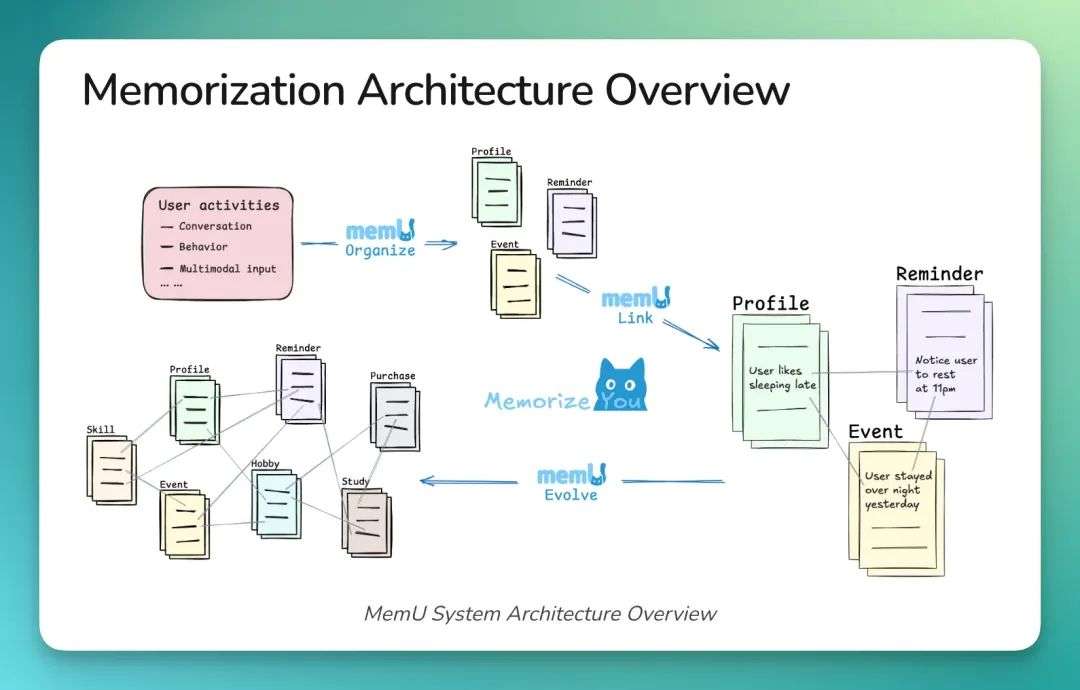
MemU 的系统架构
👦🏻 Koji
AI 长期记忆的市场格局是什么样的?能不能帮我们科普一下?
👦🏻 陈宏
Memory 是个很大的概念。我们专注在情感陪伴,聚焦于 Agent 对用户的 Memory。
其实 Memory 有多个维度:
【1】Agent 自己的 Memory:记录 Workflow、Action 结果、Reflection,加快类似任务的执行,提升任务完成的成功率;
【2】Agent-to-Agent Memory:多 Agent 协作时记录彼此的 Preference,未来 Agent Network 里这会是类似推荐系统的机会。
从技术角度看,Memory 和 Self-Evolving 也是密不可分的——Agent 可以通过 Experience 实现自我学习。
不过市场现状挺尴尬的,像市场上的头部第三方 Memory 服务 Mem0,市场影响力确实不错,但朋友们用下来都说效果一般。问题是,Memory 这种额外 Cost 的服务,效果一般就等于没用——有这钱还不如升级模型或提升 Agent 能力。
还有个问题:长期记忆的验证周期太长。次留、7 日留存这些指标根本体现不出 Memory 的价值——可能连模型的 Context Window 都没超过。要看 30 日留存或更长?现在 AI 产品迭代这么快,根本等不起,Memory 就成了不可控的实验变量。
👦🏻 Koji
既然如此,为什么你现在选择创业做 Memory?
👦🏻 陈宏
因为放眼未来,Memory 是个巨大的市场。Agent 是今年最火的 Topic,Multi-Agent 很可能是年底或明年的热点,然后就是 Agent Network。
有人说每个做 Agent 的公司都会自建 Memory System——Single Agent 时代也许可以,但当市场上有几亿甚至几百亿 Agent,甚至 Agent 开始生产 Agent 时,Memory 就不太可能定制在每个 Agent 里。那时候 Memory 必然作为第三方组件被大量调用,成为 To-Agent 产品。什么是 To-Agent 产品?就是为 Agent 设计的应用——Browser Use、各种 Sandbox、MCP 服务,Memory 也是其中之一。
从流量逻辑看,当 DAU 中的 U(User)不单单是人类用户的时候,Memory 可能会成为比较大的 To-Agent 应用之一。
👦🏻 Koji
为什么你们选择「AI 陪伴」这个细分领域,而不是更通用的记忆框架?
👦🏻 陈宏
提到 AI 陪伴,大家第一反应可能是 Character.AI 或者一些擦边产品,这其实是个误区。陪伴的范围很广——AI 助手、AI 教育、甚至星座占卜,本质上都是陪伴。只要需要更懂你,就是 MemU 的服务对象。
为什么选择垂直场景?
AI 时代大家都想做通用,这很正常。用文件系统管理 Memory 确实通用,理论上能套用在所有 Domain。但套用不等于做好——Memory 对场景依赖性极强。比如,同一个文件在工作电脑和私人电脑里的重要性完全不同。现阶段没有足够数据支撑整个 Memory 系统,所以必须往场景切。
为什么选情感陪伴?
说实话,我就是喜欢这个赛道。现在大家都在做短期情感刺激,这变不成长期陪伴。我身边很多朋友对真正的长期陪伴有美好憧憬。虽然我们没能力做完整产品,但能在技术上帮朋友们实现真正的情感陪伴。
MemU 的独特之处是引入了 「Theory of Mind」——让 Agent 能对已有 Memory 进行 Reasoning,拓展理解。
举个例子:你一直说喜欢喝咖啡,今天给你点咖啡,你突然说不喜欢。
这种深层理解对长期陪伴的成功至关重要。
👦🏻 Koji
MemU 与其他产品(如 Mem0、Zep 等)相比,最大的差异化优势是什么?
👦🏻 陈宏
效果好,成本低,召回速度快,且场景专注。
👦🏻 Koji
你最关注的竞争对手是谁?为什么?
👦🏻 陈宏
Memory 未来一定是一个庞大的市场。现在大家体量都很小,没必要竞争,不如合作起来去抢大厂的 Scope。
👦🏻 Koji
最近大厂也在行动。「十字路口」播客刚访谈了阿里云无影事业部总裁旭卿,他们推出的 AgentBay 产品中也包括了 Memory 服务。你打算如何与大厂抢份额?
👦🏻 陈宏
Agent 平台肯定会有自己的 Memory System,但在他们的服务里,Memory 只是一个很小的组件,大厂在这块的投入肯定不够。
👦🏻 Koji
Manus、Genspark 等头部的 Agent 产品,是你的典型客户吗?
👦🏻 陈宏
不是。我们主打陪伴类场景,而 Manus、Genspark 还是工具效率类为主。
对情感陪伴来说,To-User 的长期记忆是核心,必须记住用户的点点滴滴。但像 Manus 和 Genspark,他们关注的是 Agent 自己的 Memory,用来控制成本。To-User Memory 在他们的 ROI 里只占很小一部分。
说白了,不同场景的 Memory 优先级完全不同。我们选择做最需要 User Memory 的场景。
👦🏻 Koji
你们选择开源关键技术,担心被别人「抄走」吗?
👦🏻 陈宏
开源不等于做公益,也有 License 协议。只有大家遵守协议,生态才能更好发展。
我们的策略和其他开源公司类似,会同时维护开源版和商业版。商业版领先 1-2 个版本,付费用户能拿到更新更好的功能,也帮助我们商业化。
MemU GitHub 项目官网:https://github.com/NevaMind-AI/memU
👦🏻 Koji
速度、成本、效果,什么最重要?你在内部有给出优先级吗?
👦🏻 陈宏
成本一直是我们最关注的。
因为我们是一个 Agent 系统,从 Token 调用量来看远超过普通方案,但效果也显著更好。问题是,大多数客户很难接受,因为 Memory 对收入的提升不明显。所以我们计划在 9 月有一波大的更新,大家可以保持关注。
👦🏻 Koji
LLM 的记忆到底是怎么回事?
👦🏻 陈宏
很多人搞不清 LLM 里的「短期记忆」和「长期记忆」。我打个比方:
场景 1:正在看(短期记忆)。比如你刚看完一篇关于 MemU 的访谈,能一字不差复述。这就像 Context 窗口。
场景 2:过了一天(长期记忆-核心)。你只记得 「MemU 是个做 Memory 服务的公司」这种核心概念。这些精华通常放在 System Prompt 里。
场景 3:需要细节时(长期记忆-检索)。有人问技术细节?那就得去 Retrieval,从「档案室」里翻相关资料。
👦🏻 Koji
那理想的 LLM 系统应该怎么工作?
👦🏻 陈宏
对话开始时,把重要背景知识(场景 2)放进 System Prompt,保持不变。聊着聊着,对话内容累积成短期记忆(场景 1)。用户问到背景知识之外的内容,就去 Memory 库搜索(场景 3),把结果接在用户问题后面。聊完后,把精华总结更新到长期记忆里,为下次准备。
简单来说,场景 1 是短期记忆,场景 2 和 3 是长期记忆。尤其在陪伴类应用上,场景 2 更重要,它决定了 AI 的「人设」和基础认知。
👦🏻 Koji
目前业界在解决 Memory 问题上,大致有哪些主要技术路径?它们各自的优势和局限是什么?
👦🏻 陈宏
从技术角度看,要完美解决 Memory 有两条路径:Context 管理和无限长文本模型。理论上,两条路径如果做到极致,都能完美解决长期记忆的问题。
从实践层面看,Context 更简单,但容易导致开发者「显式建模」。长文本模型的能力还远不足以支撑长期记忆,不管是推理效率还是长文本推理质量都大打折扣。
还有一些参数化的记忆方法,但基本还停留在实验室研究阶段。综合来看,我们还是选择了基于 Context 的长期记忆方向去努力。
👦🏻 Koji
在设计 MemU 时,你们最关注的用户体验细节是什么?
👦🏻 陈宏
我们发现,很多团队在做 AI 产品时不知道怎么正确利用 Context。比如,有些人把 Context 窗口设置得很小,频繁调用 Memory 来省 Token,结果却失去了 Context 的 Cache,导致输入成本更高。
因为我们团队之前做过大型应用(像豆包、星野),所以很清楚 AI 聊天软件的开发逻辑。我们会提供一系列 Tutorial,告诉开发者如何节省成本,如何达到最佳 Memory 效果,如何配合对话模型实现最优体验。
👦🏻 Koji
你为什么要创业?
👦🏻 陈宏
这个问题应该反过来问:为什么不创业?
Agent 出现之后,就是一次新的浪潮,到处都是新的机会。我个人也非常看好长期情感陪伴方向。并且我相信,以 DAU 作为北极星指标的大厂,是做不好长期陪伴产品的。
👦🏻 Koji
最后一个问题:在你看来,现在这个行业里,有哪些团队最有可能真正做出能安慰人、抚慰人、帮助人的 AI 陪伴产品?他们具备哪些特征?
👦🏻 陈宏
情感陪伴类 App 一直被「擦边」这个问题拖累。擦边内容吸引来的用户会让反馈数据完全跑偏,Reward 数据一跑偏,整个产品的模型迭代飞轮就转不动了——这是赛道的死结。
但最近看到一些新气象,比如「 Tolan」,还有国内的「林间聊愈室」,以及其他团队的尝试,都在认真做不一样的东西。
说实话挺讽刺的:有钱有技术的大公司都在搞擦边赚流量和快钱,反而是资源有限的小团队在认真做情感治愈。
在这种环境下,我们能给这些有理想的团队提供技术支持,也算是做点对社会有意义的事情。

文章来自于微信公众号“十字路口Crossing”,作者是“Koji”。


【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】OpenManus 目前支持在你的电脑上完成很多任务,包括网页浏览,文件操作,写代码等。OpenManus 使用了传统的 ReAct 的模式,这样的优势是基于当前的状态进行决策,上下文和记忆方便管理,无需单独处理。需要注意,Manus 有使用 Plan 进行规划。
项目地址:https://github.com/mannaandpoem/OpenManus
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
