# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Nature封面认证!DeepSeek R1成果,又拿下了最新殊荣。
就在最新的Nature新刊中,DeepSeek一举成为首家登上《Nature》封面的中国大模型公司,创始人梁文锋担任通讯作者。
纵观全球,之前也只有极少数如DeepMind者,凭借AlphaGo、AlphaFold有过类似荣誉。

Nature版本的R1论文不仅首次披露了R1的训练成本——仅约29.4万美元(折合人民币约 208 万),还进一步补充了包括模型训练所使用的数据类型及安全性的技术细节。
评审该论文的Hugging Face机器学习工程师Lewis Tunstall表示,R1是首个经历同行评审的大型语言模型,这是一个非常值得欢迎的先例。
而俄亥俄州立大学人工智能研究员Huan Sun更是盛赞R1 ,称其自发布以来,几乎影响了所有在大语言模型中使用强化学习的研究。
截至发文前,其数据如下:
不过也是因为DeepSeek,中国AI公司的下一篇工作,恐怕已经不再满足于 CVPR、ICLR、ICML这些AI顶会了,
是不是得对齐Nature、Science的封面了?

在这次的Nature版本中,DeepSeek在其最新的补充材料中对训练成本、数据及安全性进行了进一步的澄清。
在训练花费方面, R1-Zero和R1都使用了512张H800GPU,分别训练了198个小时和80个小时,以H800每GPU小时2美元的租赁价格换算的话,R1的总训练成本为29.4万美元。
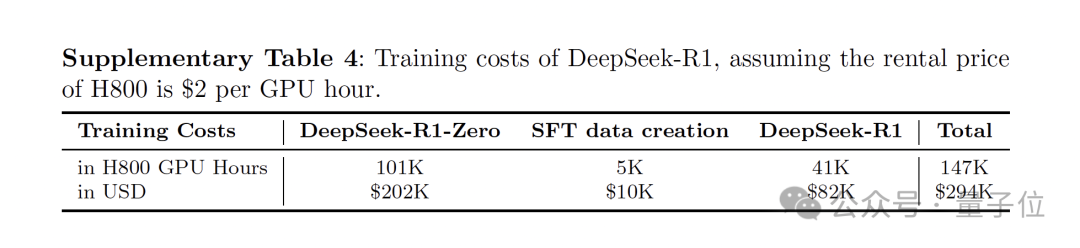
要知道,R1可是实打实的660B参数的大模型。
相比之下,它不到30万美元的训练成本,直接让那些动辄烧掉上千万美元的同行们“抬不起头”。
也难怪它在年初发布时,会在美股掀起一场海啸,让那些关于“巨额投入才能打造顶级AI模型”的传言不再那么漂亮。
(奥特曼:干脆报我身份证号得了)
此外,在数据来源方面,DeepSeek也是一举打破了拿彼模型之输出当R1之输入的传闻。
根据补充材料,DeepSeek-R1的数据集包含数学、编程、stem、逻辑、通用等5个类型的数据。
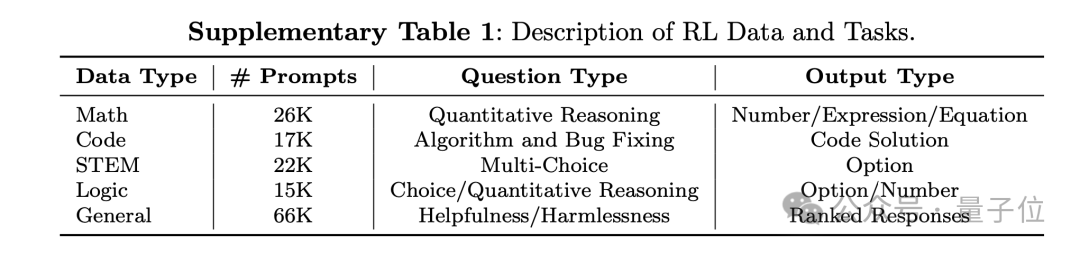
具体来说,数学数据集包含2.6万道定量推理题,包括数学考试题和竞赛题;
代码数据集包含1.7万道算法竞赛题和8千道代码修复问题;
STEM数据集包含2.2万道选择题,涵盖物理、化学和生物等学科;
逻辑数据集包含真实问题和合成问题等共1.5万道题;
通用数据集包含6.6万道题,用于评估模型的有用性,涵盖创意写作、文本编辑、事实问答、角色扮演以及评估无害性等多种类别。
在安全性方面,虽然开源共享有助于技术在社区中的传播,但同时也可能带来被滥用的潜在风险。因此DeepSeek又一进步发布了详细的安全评估,涵盖以下几个方面;
评估表明,DeepSeek-R1 模型的固有安全水平总体处于中等水平,与 GPT-4o相当,通过结合风险控制系统可进一步提高模型的安全水平。
接下来,我们来一起回顾一下这篇经典论文
总的来说,DeepSeek-R1(zero)旨在解决大型语言模型在处理复杂问题和对人工数据的依赖,提出了一种纯强化学习(RL)框架来提升大语言模型的推理能力。
这一方法不依赖人工标注的推理轨迹,而是通过自我演化发展推理能力,核心在于奖励信号仅基于最终答案的正确性,而不对推理过程本身施加限制。
具体来说,他们使用DeepSeek-V3-Base作为基础模型,并采用GRPO(Group Relative Policy Optimization)作为强化学习框架来提高模型在推理任务上的表现。
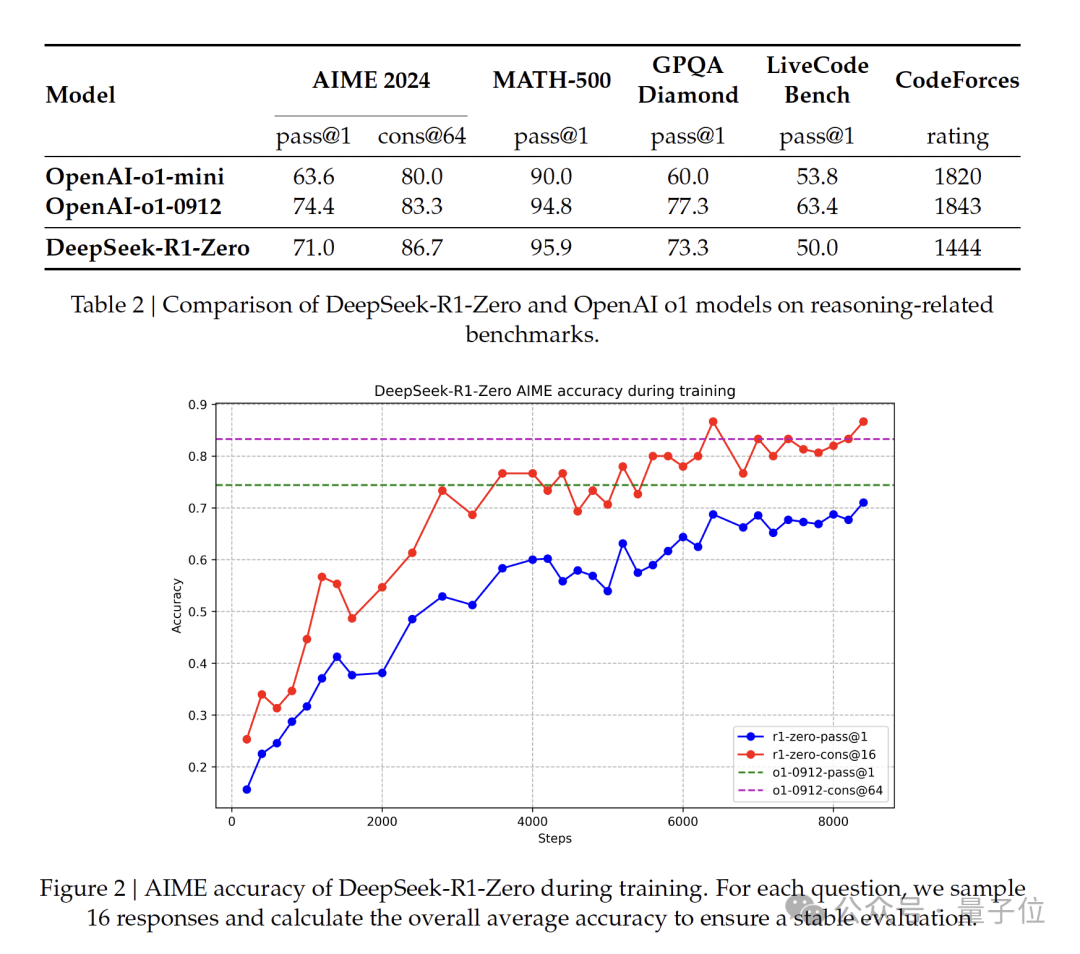
经过数千步强化学习训练后,DeepSeek-R1-Zero 在推理基准测试上表现出卓越性能。
例如,在AIME 2024上,pass@1分数从15.6%提升至71.0%,通过多数表决进一步提高至86.7%,与o1的表现相当。
更进一步,为了解决DeepSeek-R1-Zero 在可读性和语言混合上的问题,研究又引入DeepSeek-R1,采用少量冷启动数据和拒绝采样、强化学习和监督微调相结合的多阶段训练框架。
具体而言,团队首先收集数千条冷启动数据,对 DeepSeek-V3-Base 模型进行微调。随后,模型进行了类似 DeepSeek-R1-Zero 的面向推理的强化学习训练。
在强化学习接近收敛时,团队通过在强化学习检查点上进行拒绝采样,结合来自DeepSeek-V3在写作、事实问答、自我认知等领域的监督数据,生成新的SFT数据,并重新训练DeepSeek-V3-Base模型。
经过新数据微调后,模型还经历了覆盖各种提示场景的额外的强化学习过程,DeepSeek-R1就由此而来。
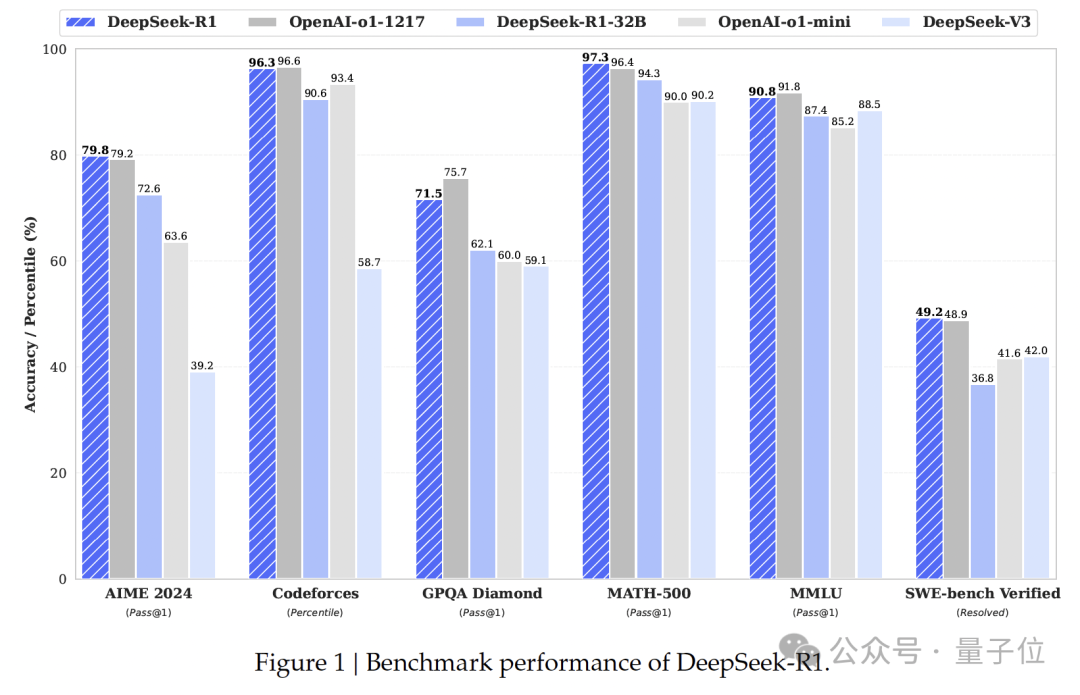
实验表明,DeepSeek-R1与当时的顶尖模型OpenAI-o1-1217不相上下。
此外,将大模型涌现出的推理模式用于指导并提升小模型的推理能力也成为了一种经典方法。
论文中使用Qwen2.5-32B作为基础模型,结果显示,从DeepSeek-R1蒸馏出的性能,优于直接在该基础模型上应用强化学习。
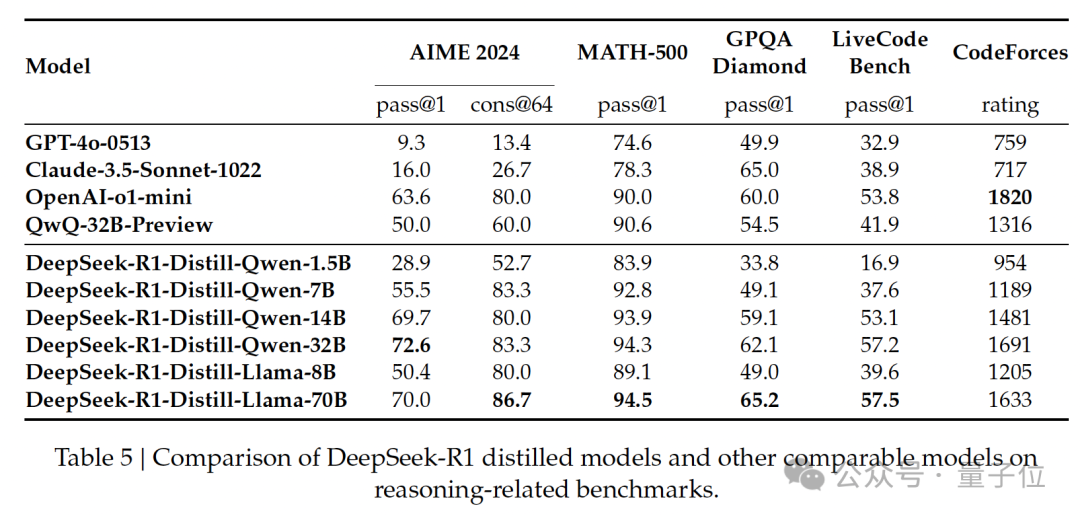
当然,在开拓性论文的基础上,更让人津津乐道、也赢得Nature盛赞的,是DeepSeek的透明性与开源精神:
DeepSeek已在HuggingFace上公开了DeepSeek-R1和DeepSeek-R1-Zero的模型权重,同时将基于Qwen2.5 和 Llama3 系列的蒸馏模型一并开源,供社区自由使用。
回想年初DeepSeek在海外爆火时,梁文锋一句“中国AI不可能永远跟随”的豪言壮志令人振奋。
如今,DeepSeek影响力获得Nature封面认可,如果AI研究机构有S级认可,那DeepSeek毫无疑问已经拿到了S级认证。
下一个,阿里通义、字节Seed、腾讯混元、百度文心、华为、智谱、Kimi、阶跃……
Who?
参考链接
[1]https://www.nature.com/articles/d41586-025-03015-6
[2]https://www.nature.com/articles/s41586-025-09422-z#Sec4
文章来自于微信公众号 “量子位”,作者 “量子位”


【开源免费】kimi-free-api是一个提供长文本大模型逆向API的开渔免费技术。它支持高速流式输出、智能体对话、联网搜索、长文档解读、图像OCR、多轮对话,零配置部署,多路token支持,自动清理会话痕迹等原大模型支持的相关功能。
项目地址:https://github.com/LLM-Red-Team/kimi-free-api?tab=readme-ov-file
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
