# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
智东西9月23日消息,深夜,阿里通义大模型团队连放三个大招:开源原生全模态大模型Qwen3-Omni、语音生成模型Qwen3-TTS、图像编辑模型Qwen-Image-Edit-2509更新。
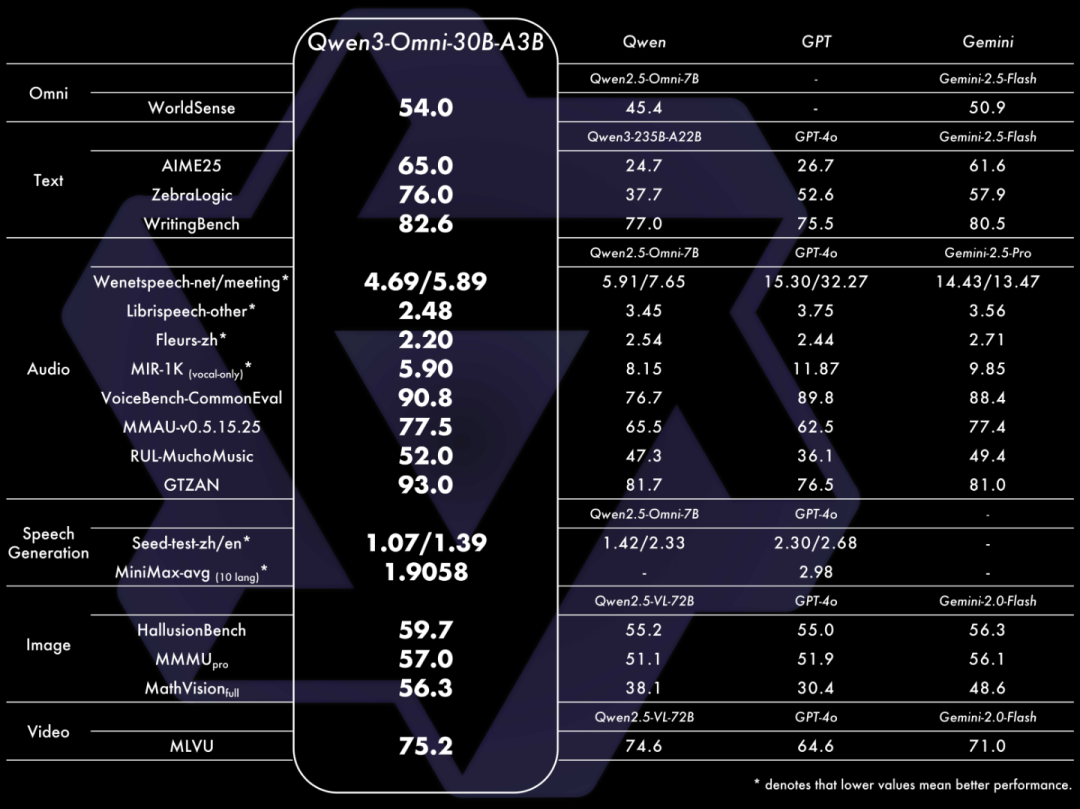
Qwen3-Omni能无缝处理文本、图像、音频和视频等多种输入形式,并通过实时流式响应同时生成文本与自然语音输出。其在36项音频及音视频基准测试中斩获32项开源SOTA与22项总体SOTA,超越Gemini-2.5-Pro、Seed-ASR、GPT-4o-Transcribe等闭源强模型,同时其图像和文本性能也在同尺寸模型中达到SOTA水平。
Qwen3-TTS支持17种音色与10种语言,在语音稳定性与音色相似度评估中超越SeedTTS、GPT-4o-Audio-Preview等主流产品。
Qwen-Image-Edit-2509的首要更新是支持多图编辑,可以拼接不同图片中的人物+人物、人物+物体等。
▲阿里开源主页
阿里开源了Qwen3-Omni-30B-A3B-Instruct(指令跟随)、Qwen3-Omni-30B-A3B-Thinking(推理)和通用音频字幕器Qwen3-Omni-30B-A3B-Captioner。
Hugging Face开源地址:
https://huggingface.co/Qwen
GitHub开源地址:
https://github.com/QwenLM/Qwen3-Omni
01
支持119种语言交互
能随意定制、修改人设
在通义千问国际版网站上,只需点击输入框右下角,即可唤起视频通话功能。目前该功能仍处于Beta测试阶段。
我们在实际测试中发现,网页端的视频交互体验尚不稳定,因此转而使用通义千问国际版App进行进一步体验。在App中,Qwen-Omni-Flash的视频响应延迟较低,几乎达到无感水平,接近真人面对面交流的流畅度。
Qwen-Omni-Flash具备良好的世界知识储备,我们通过识别啤酒品牌、植物等画面进行测试,模型均能给出准确回答。
官方博客提到,Qwen3-Omni支持119种文本语言交互、19种语音理解语言与10种语音生成语言,延迟方面纯模型端到端音频对话延迟低至211ms,视频对话延迟低至507ms,还能支持30分钟音频理解。但在实际使用中,当模型输出英语、西班牙语等外语时,仍可察觉其发音带有明显的普通话语调特征,不够自然地道。
而在粤语交互场景下,Qwen-Omni-Flash仍会不时夹杂普通话词汇,一定程度上影响了对话的沉浸感。
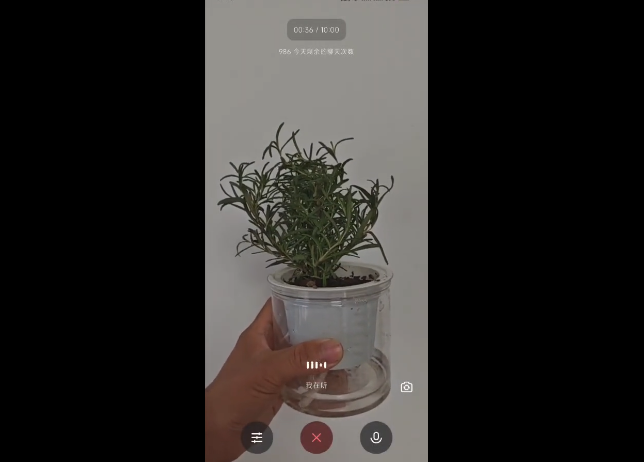
官方演示的几个Demo中,展示了西班牙语、法语、日语的交互效果。
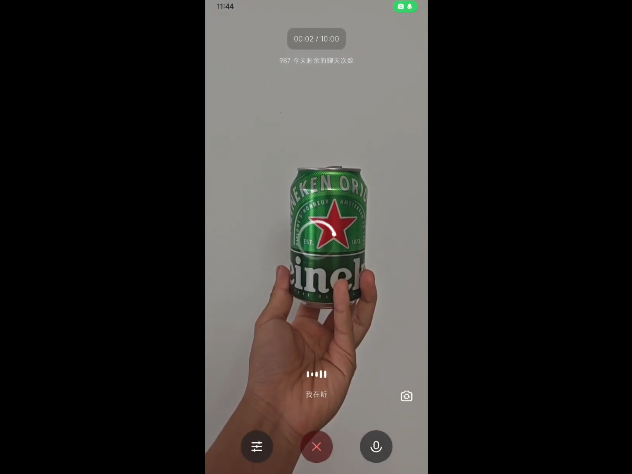
日语交流场景中,模型可以分析视频中人物所处的环境,以及他们交流的内容是什么。
Qwen3-Omni支持system prompt随意定制,可以修改回复风格、人设等。
演示中,模型扮演的角色是广东幼儿园老师,通过模型的特点总结图为小朋友讲解Qwen3-Omni,其涵盖了图片中模型的四个特点,还用了小朋友更容易理解的比喻。

多人交互场景中,Qwen3-Omni也能分析人物的性别、说话的语气、内容等。
例如下面这段谈话中,既有说四川话的女生邀请朋友来玩,还有说普通话的男生失恋了,以及另外的男生被偷狗等不同事件,Qwen3-Omni被问到那个女生说的什么方言、说了什么,其问答分析出了是四川话,进行了自我介绍、发出邀请、赞美家乡。
让模型分析视频中哪个人最开心,Qwen3-Omni认为是最后一个说话的小王,重点分析了他的语气和竖大拇指的动作。

此外,Qwen3-Omni还支持分析音乐风格、元素,以及对视频中画面进行推理,如当其分析出视频中的用户是在解数学题,还会对这道题进行解答。

02
22项测试达SOTA
预训练不降智
Qwen3-Omni在全方位性能评估中,单模态任务表现与参数规模相当的Qwen系列单模态模型持平,在音频任务中表现更好。
该模型在36项音视频基准测试中,32项取得开源领域最佳性能,22项达到SOTA水平,性能超越Gemini-2.5-Pro、Seed-ASR、GPT-4o-Transcribe等闭源模型,在语音识别与指令跟随任务中达到Gemini-2.5-Pro相同水平。
其博客提到,Qwen3-Omni采用Thinker-Talker架构,Thinker负责文本生成、Talker专注于流式语音Token生成,直接接收来自Thinker的高层语义表征。
为实现超低延迟流式生成,Talker通过自回归方式预测多码本序列:在每一步解码中,MTP模块输出当前帧的残差码本,随后Code2Wav合成对应波形,实现逐帧流式生成。
其创新架构设计的要点包括,音频编码器采用了基于2000万小时音频数据训练的AuT模型,具备通用音频表征能力;Thinker与Talker均采用MoE架构,支持高并发与快速推理。
同时,研究人员在文本预训练早期混合单模态与跨模态数据,可实现各模态混训性能相比纯单模态训练性能不下降,同时显著增强跨模态能力。
AuT、Thinker、Talker+Code2wav采用全流程全流式,支持首帧Token直接流式解码为音频输出。
此外,Qwen3-Omni支持function call,实现与外部工具/服务的高效集成。
03
发布文本转语音模型
多项基准测试达SOTA
阿里通义还发布了文本转语音模型Qwen3-TTS-Flash。
其主要特点包括:
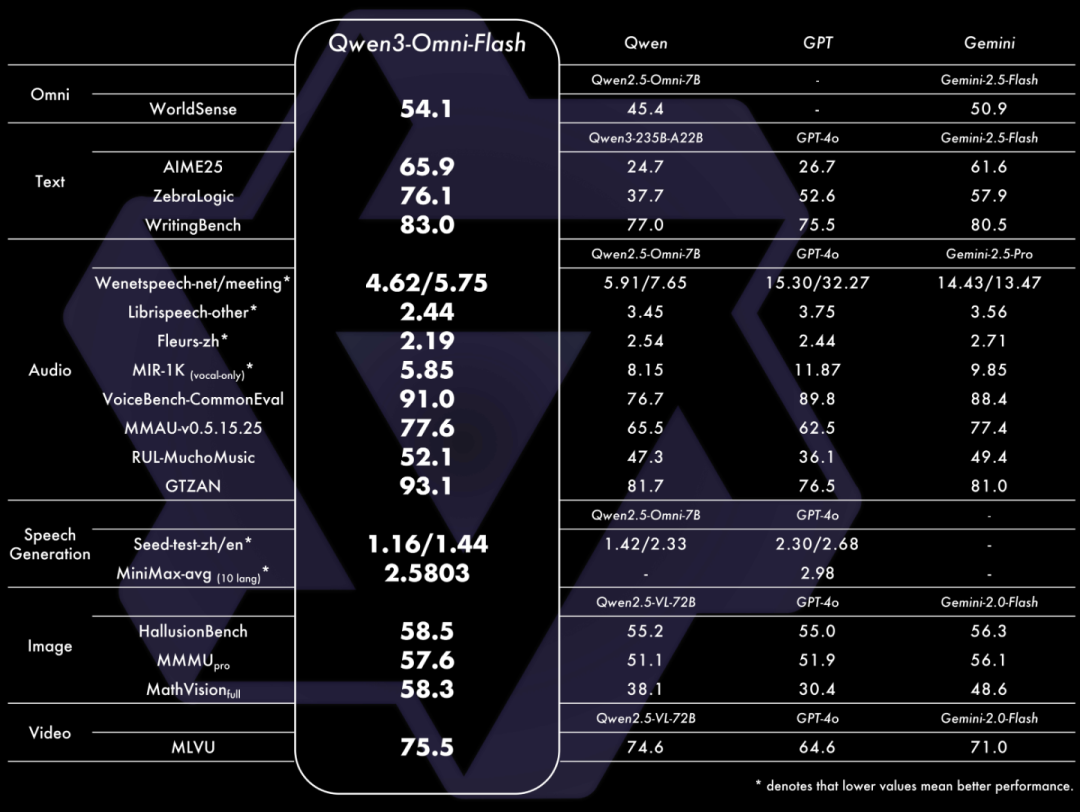
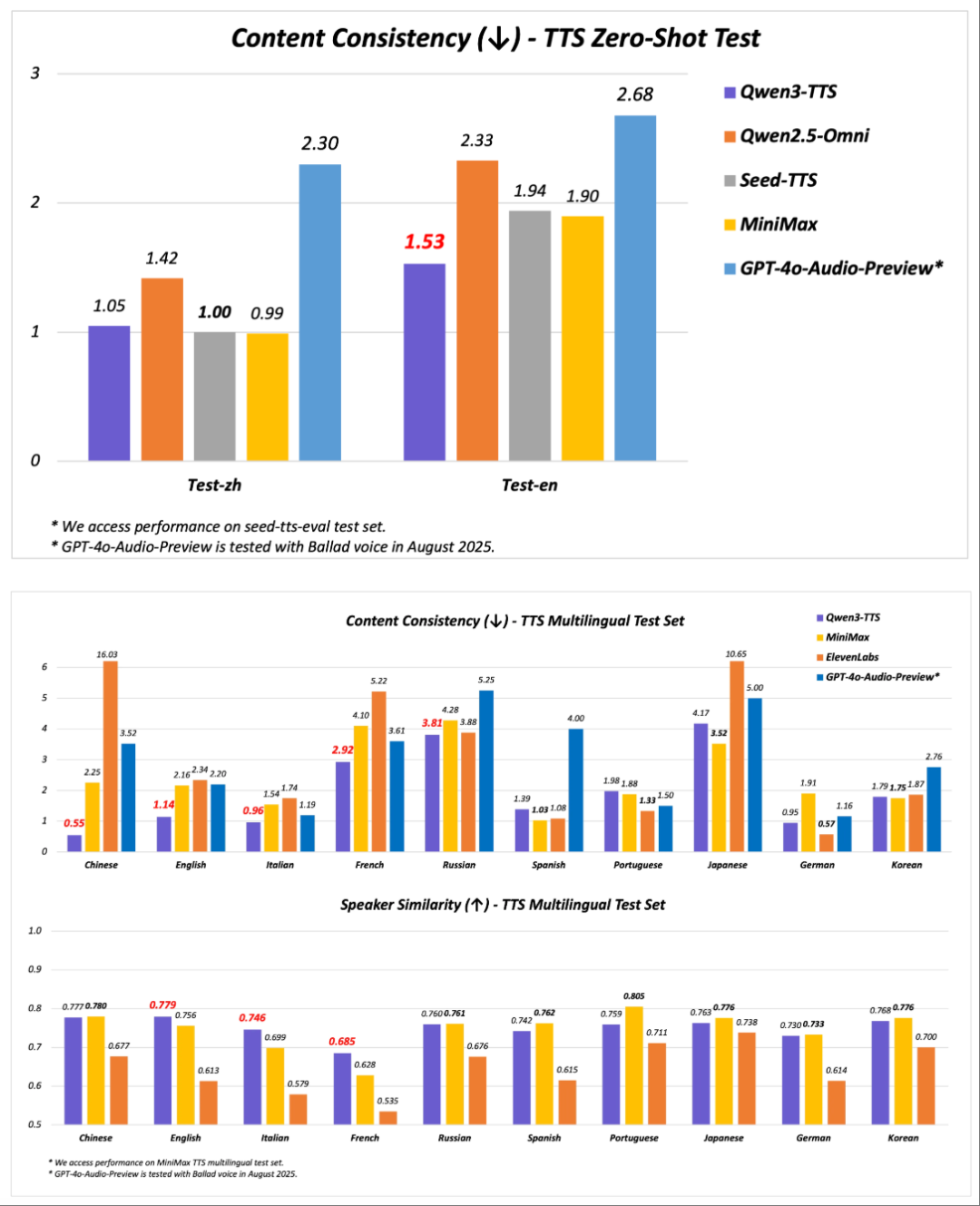
中英稳定性:Qwen3-TTS-Flash的中英稳定性在seed-tts-eval test set上,取得了SOTA的表现,超越SeedTTS、MiniMax、GPT-4o-Audio-Preview;
多语言稳定性和音色相似度上,Qwen3-TTS-Flash在MiniMax TTS multilingual test set上,WER在中文、英文、意大利语、法语达到SOTA,显著低于MiniMax、ElevenLabs、GPT-4o-Audio-Preview,英文、意大利语、法语的说话人相似度显著超越MiniMax、ElevenLabs、GPT-4o-Audio-Preview。
高表现力:Qwen3-TTS-Flash具备高表现力的拟人音色,能够稳定、可靠地输出高度遵循输入文本的音频。
丰富的音色和语种:Qwen3-TTS-Flash提供17种音色选择,每一种音色均支持10种语言。
多方言支持:Qwen3-TTS-Flash支持方言生成,包括普通话、闽南语、吴语、粤语、四川话、北京话、南京话、天津话和陕西话。
语气适应:经过海量数据训练,Qwen3-TTS-Flash能够根据输入文本自动调节语气。
高鲁棒性:Qwen3-TTS-Flash能够自动处理复杂文本,抽取关键信息,对复杂和多样化的文本格式具有很强的鲁棒性。
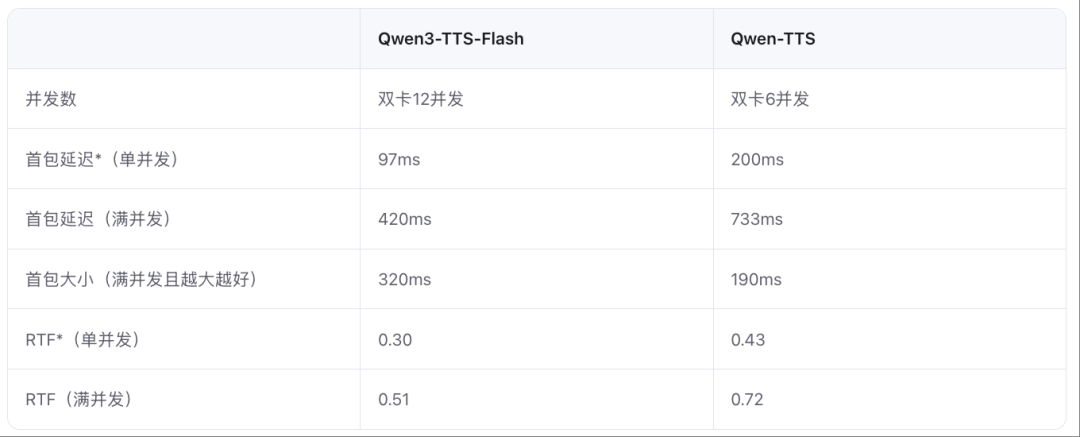
快速生成:Qwen3-TTS-Flash具有极低首包延迟,单并发首包模型延迟低至97ms。

在具体性能方面,在MiniMax TTS multilingual test set上,Qwen3-TTS-Flash在中文、英文、意大利语和法语的WER均达到了SOTA,显著低于MiniMax、ElevenLabs和GPT-4o-Audio-Preview。在说话人相似度方面,Qwen3-TTS-Flash在英文、意大利语和法语均超过了上述模型,在多语言的语音稳定性和音色相似度上展现出了卓越的表现。
研究人员引入了多项架构升级和加速策略,使得模型实现更低的首包延迟和更快的生成速度。
04
图像编辑模型更新
支持多图编辑
阿里此次还推出了图像编辑模型Qwen-Image-Edit-2509的月度迭代版本。
相比于8月发布的Qwen-Image-Edit,Qwen-Image-Edit-2509的主要特性包括:
对于多图输入,Qwen-Image-Edit-2509基于Qwen-Image-Edit结构,通过拼接方式进一步训练,从而提供“人物+人物”、“人物+商品”,“人物+场景”等多种玩法。

单图一致性增强:对于单图输入,Qwen-Image-Edit-2509提高了一致性,主要体现在以下方面:人物编辑一致性增强,包括增强人脸ID保持,支持各种形象照片、姿势变换;商品编辑一致性增强,包括增强商品ID保持,支持商品海报编辑;文字编辑一致性增强,除了支持文字内容修改外,还支持多种文字的字体、色彩、材质编辑。
原生支持ControlNet,包括深度图、边缘图、关键点图等。

05
结语:多模态赛道发力!
阿里通义家族模型加速扩员
此次三大模型的新进展进一步强化了通义在多模态生成领域的竞争力,其中Qwen3-TTS-Flash在多说话人能力、多语言支持、多方言适配以及文本处理鲁棒性等方面实现了性能突破,且与Qwen3-Omni结合实现了大模型语音表现的更新。
文章来自于微信公众号 “智东西”,作者 “智东西”



【开源免费】kimi-free-api是一个提供长文本大模型逆向API的开渔免费技术。它支持高速流式输出、智能体对话、联网搜索、长文档解读、图像OCR、多轮对话,零配置部署,多路token支持,自动清理会话痕迹等原大模型支持的相关功能。
项目地址:https://github.com/LLM-Red-Team/kimi-free-api?tab=readme-ov-file
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
