# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
如何让AI更聪明地操作手机、电脑界面?
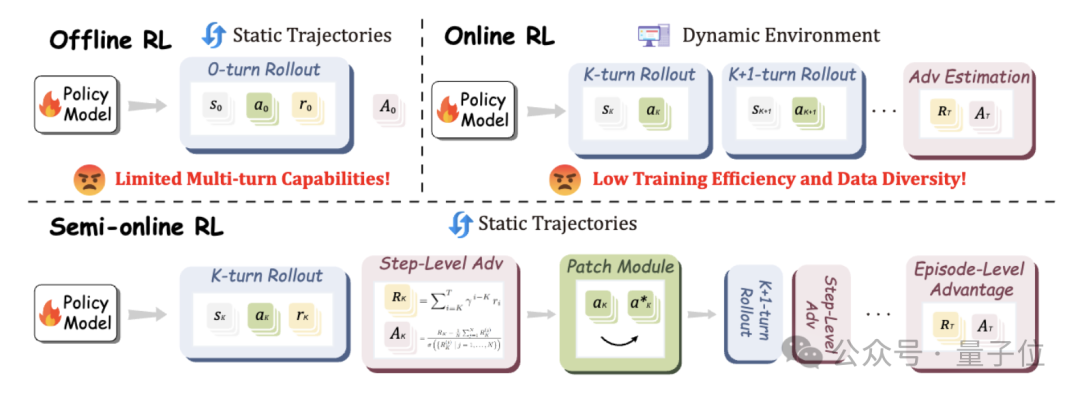
浙江大学与通义实验室Mobile-Agent团队在UI-R1的基础上,推出全新研究成果——UI-S1,提出了一种名为半在线强化学习(Semi-online Reinforcement Learning)的创新训练范式。
该工作融合了离线训练的稳定性与在线学习的长程优化能力,在不依赖真实环境交互的前提下,显著提升了模型在动态多轮任务中的表现。

也就是说,这种方法用的还是离线学习的现成操作数据,但会模拟在线学习的过程。
下面来看看是怎么做到的。
现有的GUI Agent训练主要依赖两类强化学习范式:
因此,如何在无需频繁真实交互的前提下,赋予模型类似在线学习的上下文连贯性和长程推理能力,成为突破瓶颈的关键。
为解决上述矛盾,研究团队提出了三项关键技术,共同构成UI-S1的核心架构:
离线学习的轨迹是固定的,只能将专家轨迹的动作(*表示)作为历史:
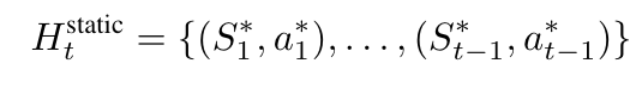
而在线学习的轨迹是可以动态变化的,将模型自己的原始输出(π表示)作为历史:
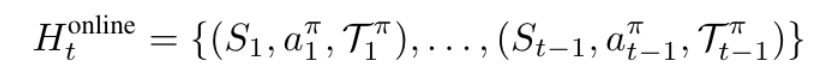
UI-S1首次提出半在线强化学习范式,其核心思想是在固定离线轨迹的基础上,在每次rollout过程中保留模型自身的原始输出(包括动作选择与思维链),而非仅使用专家动作作为历史输入。
这一设计使得模型能够在训练中体验“自我行为带来的上下文变化”,从而增强策略的一致性和多轮连贯性。
换言之,即使没有真实环境反馈,模型也能“感知”自己过去的行为,并据此调整后续决策,实现了对在线学习过程的有效模拟。
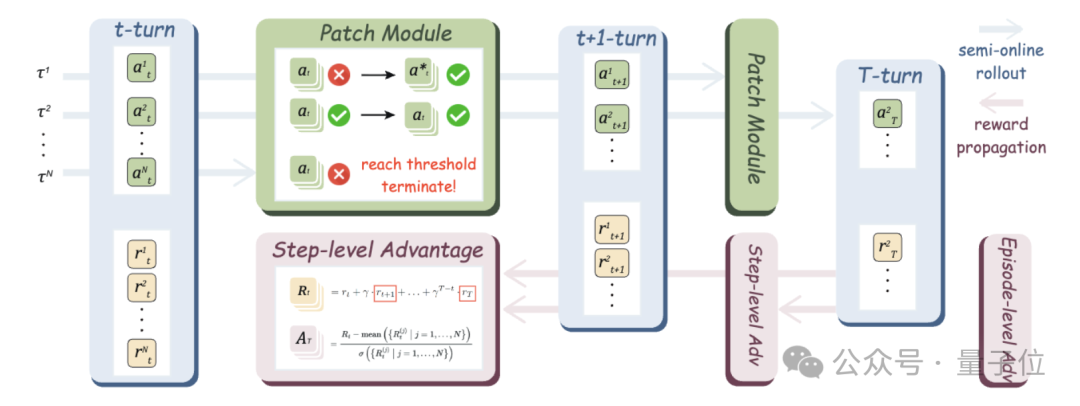
由于模型在rollout中可能偏离专家路径,导致后续状态无法匹配原始轨迹,研究者引入了可配置的补丁机制,以恢复被中断的操作流。具体包含三种策略:
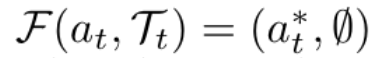
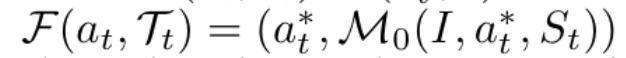
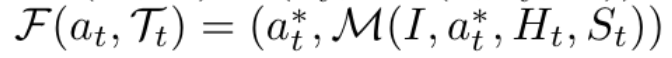
此外,提高补丁次数上限可显著提升模型访问完整轨迹的能力,进而增强对后期步骤的学习效果。
分析显示,更高的补丁阈值有助于维持策略熵,防止过早收敛,促进探索多样性。
为了弥补传统离线RL无法捕获未来收益的缺陷,UI-S1引入了带折扣因子的未来奖励传播机制。对于每个中间步骤,系统不仅计算其即时规则奖励
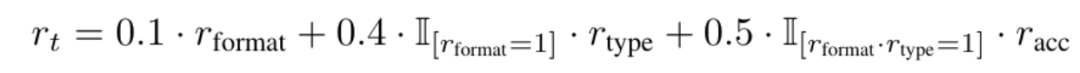
还结合未来步骤的潜在价值(按衰减因子γ加权)形成综合奖励:
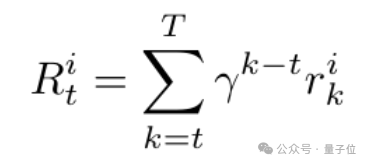
有了这个步骤级别奖励,研究者们用其估计同一个步骤组内的步骤级别优势,
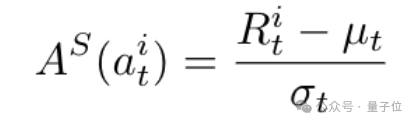
最后一步的优势被当作轨迹级别优势,用于评估轨迹是否完成:
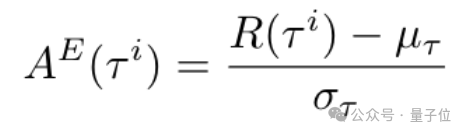
研究者将两个级别的优势加权后(
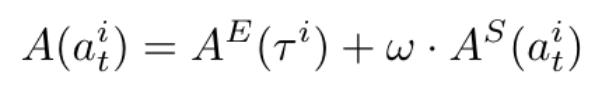
),采用动态采样的方式优化策略模型:
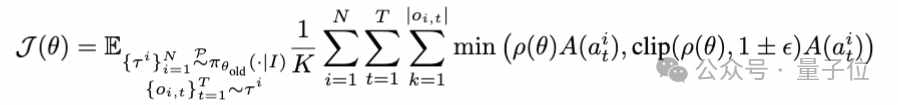
针对传统静态评测(如AC-High)无法反映多轮容错能力的问题,研究团队提出了新的评测——SOP(Semi-online Performance)。
该协议保留模型每一轮的真实输出,一旦出现错误即终止任务,全面模拟真实使用场景下的连续交互过程。结果表明,SOP与真实在线性能高度对齐,且支持更高任务多样性和更快评估速度,填补了现有评测体系在动态性与实用性之间的空白。
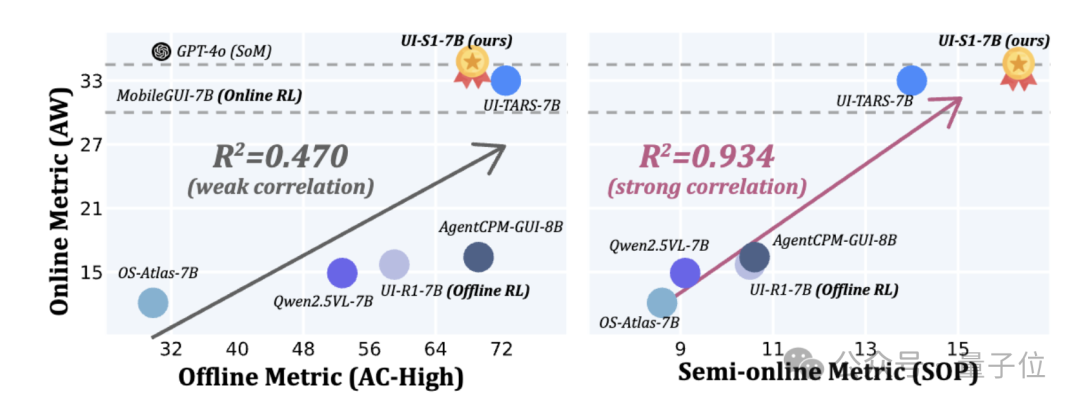
在多个主流GUI自动化基准上的测试中,UI-S1-7B展现出卓越性能:
特别是在AndroidWorld任务中,UI-S1-7B取得了34.0%的任务成功率,接近GPT-4o(34.5%)与UI-TARS-7B(33.0%),显著优于纯SFT或离线RL方法。
值得注意的是,部分基线方法在动态评测中甚至不如基础模型,反映出其在多轮泛化方面的根本缺陷。
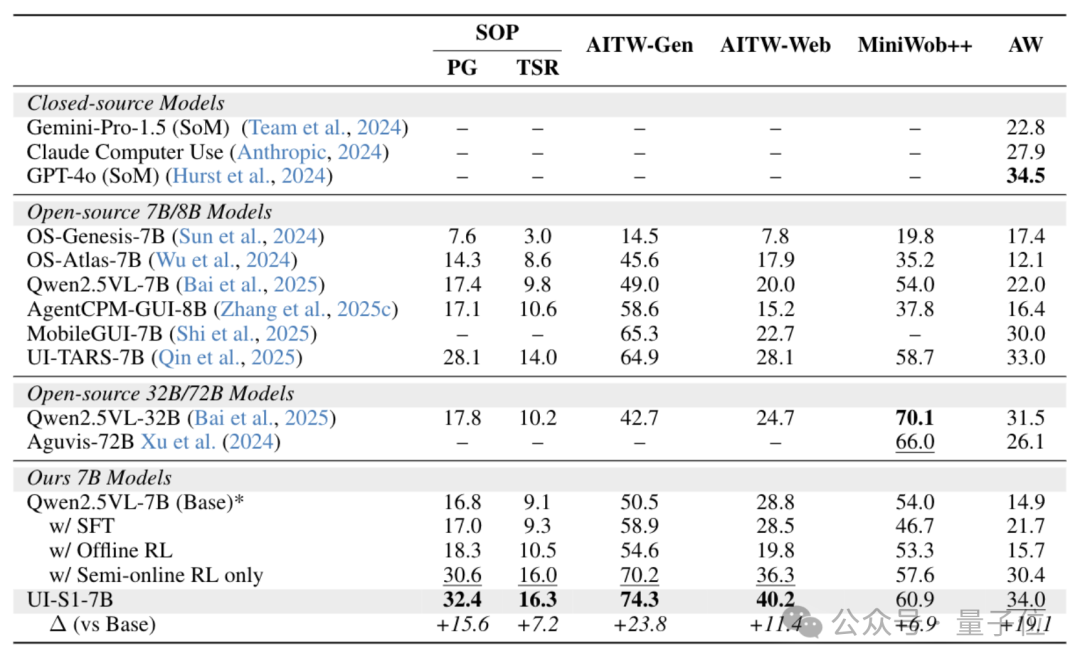
同时,在单轮任务(如GUI Odyssey)上,UI-S1-7B仍保持+7.1%的增益,说明半在线训练并未牺牲局部精度,实现了“长短兼顾”的双重优化。
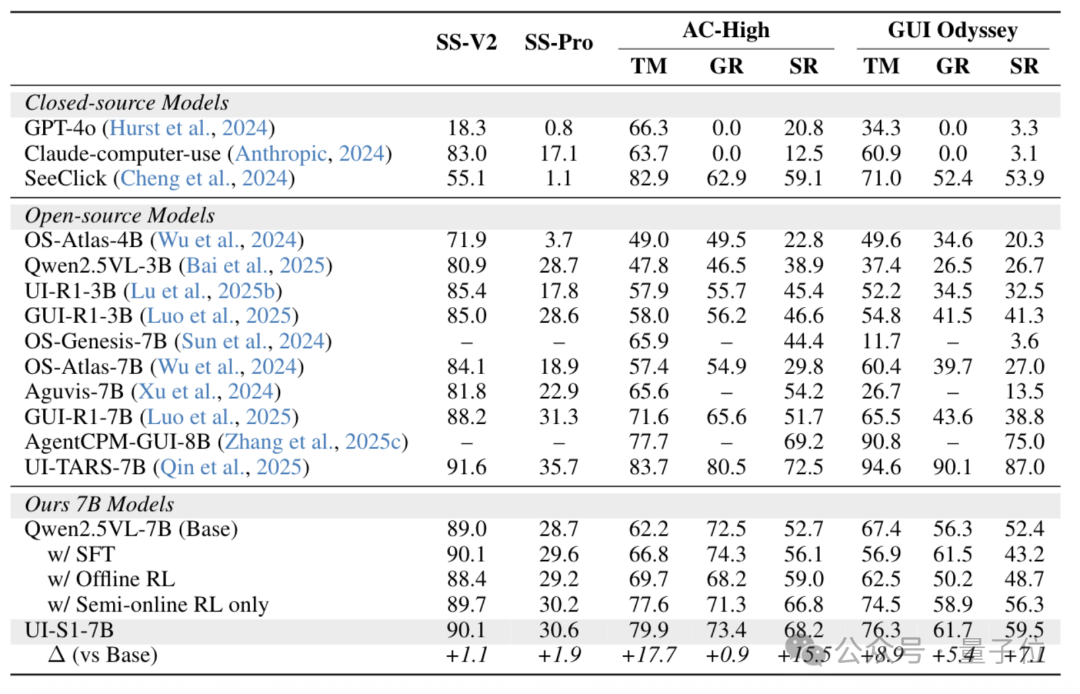
在常规的GUI单轮评测上,UI-S1-7B相比于base模型也有一定程度的提升(比如GUI Odyssey +7.1),证明了半在线方法并没有牺牲单轮预测能力。
作为UI-S1框架的核心组件之一,补丁模块(Patch Module)在维持训练稳定性与提升策略泛化能力方面发挥了不可替代的作用。
其设计初衷在于解决半在线强化学习中一个根本性矛盾:模型在rollout过程中不可避免地会偏离原始专家轨迹,导致后续状态无法对齐真实数据,从而中断整个轨迹的学习进程。
为缓解这一问题,研究团队引入了可调节的补丁机制,允许系统在检测到操作偏差时,以有限次数对历史动作或思维链进行修正。通过设置超参数阈值控制每条轨迹最多可修补的次数,研究人员系统评估了不同配置下的性能变化。
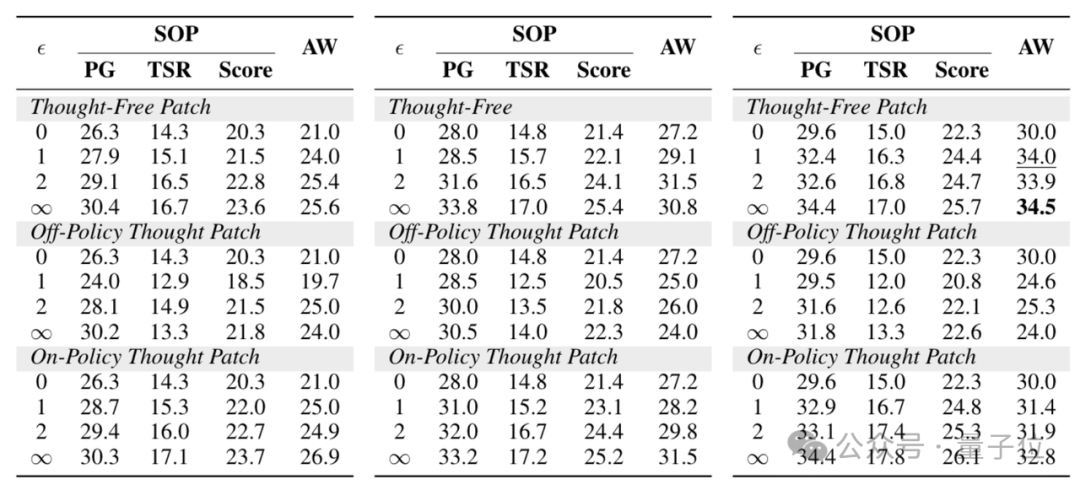
实验结果表明,提高补丁阈值显著提升了模型在SOP和AndroidWorld两个动态评测基准上的表现。
在具体修补策略的选择上,研究对比了三种典型方案,揭示了性能与效率之间的深层权衡:
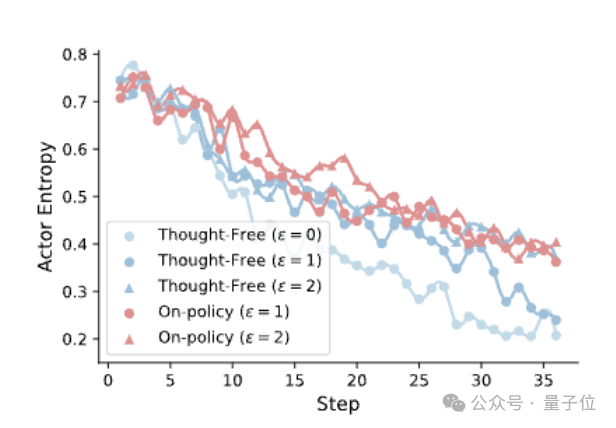
更进一步分析发现,较大的补丁阈值有助于在训练过程中维持较高的策略熵(policy entropy),即模型在动作选择上的不确定性水平。
较高的熵值反映了更丰富的探索行为,避免策略过早收敛于少数高频路径。
这说明补丁机制不仅是误差纠正工具,更是促进策略多样性和防止模式坍缩的重要手段。
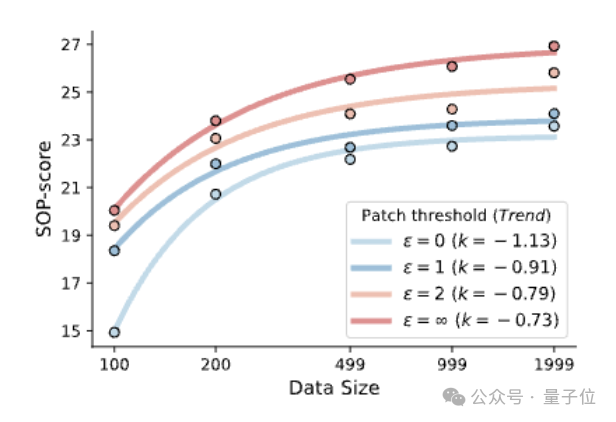
研究表明,UI-S1的性能增长符合指数型数据规模律。
随着补丁阈值从0增至无穷,指数系数k从−1.13提升至−0.73,表明单位数据带来的边际收益明显改善。
这意味着即使在有限数据条件下,该方法也能更充分挖掘非完美轨迹中的监督信号,具备良好的小样本适应能力。
消融实验进一步验证了多个核心组件的技术贡献。
首先,在未来奖励建模方面,折扣因子γ的设置对多轮任务表现具有决定性影响:当γ=0(完全忽略未来奖励)时,模型性能最低;而在 γ=0.5时达到峰值,说明适度纳入长程优化信号可显著提升策略的全局一致性与任务完成率,凸显了半在线范式在捕获跨步依赖关系上的优势。
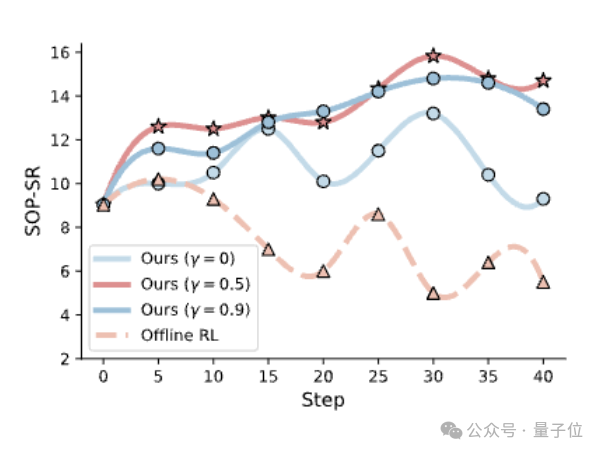
其次,在训练范式组合上,联合使用监督微调(SFT)与半在线强化学习(Semi-online RL)的效果明显优于任一单独方法——在AndroidWorld基准上,组合方案取得34.0%的任务成功率,分别高出仅用Semi-online RL(30.4%)和仅用SFT(21.7%)的配置,且平均任务完成步数更少,表明其具备更强的路径规划与执行效率。
最后,同时引入轨迹级与步骤级优势函数计算,并保留多帧历史观测信息(包括动作、思考链与界面状态),均被证实对最终性能有正向增益,去除任一组件均会导致性能下降,说明这些设计共同支撑了模型在复杂GUI交互中的稳健决策能力。

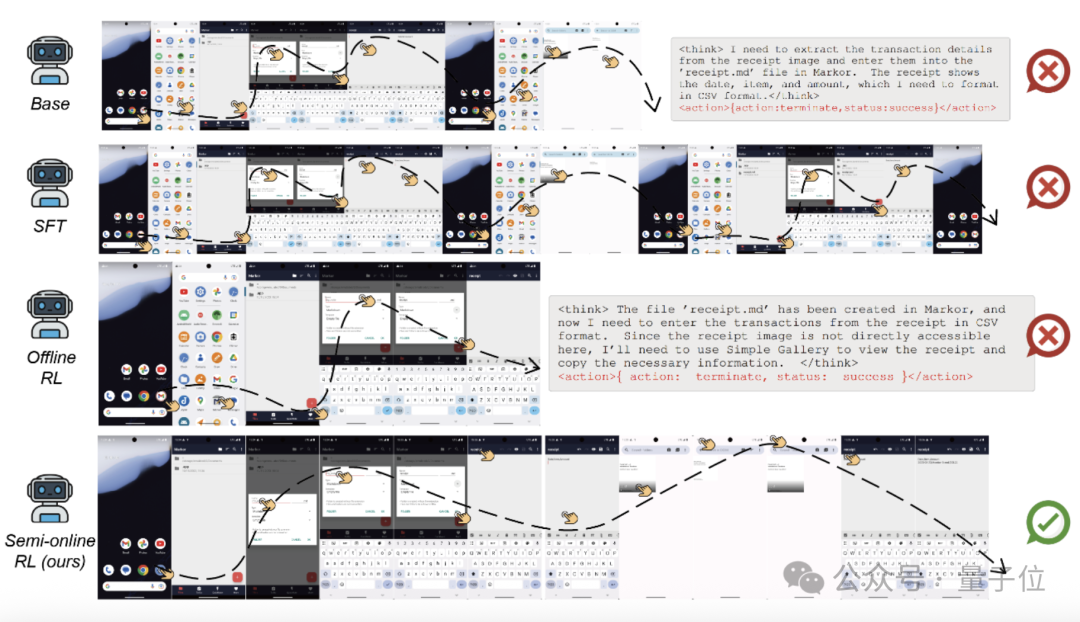
研究者们展示了一项复杂的跨应用任务,该任务要求在多个操作步骤中持续保留关键信息:从Simple Gallery中查看一张包含交易信息的图片,并在Markor应用中创建文件记录该信息。
实验表明,基础模型和离线强化学习(Offline RL)模型在执行过程中出现了思维与动作不一致的问题。
例如,Offline RL模型在规划完切换至下一应用后便提前终止操作,可能因其过度拟合局部奖励,未能统筹后续任务目标。而经过监督微调(SFT)的模型则在流程中遗失了关键信息,导致执行冗余操作,如尝试创建一个已存在的文件。
相比之下,基于半在线强化学习(Semi-Online RL)框架的UI-S1模型在整个12步操作序列中保持了稳定的上下文连贯性,成功将交易信息“2023-03-23, Monitor Stand, $33.22”准确以CSV格式写入文件。
这一表现验证了该方法在学习多轮复杂行为方面的优势,实现了推理过程与动作执行的高度对齐。
研究者认为,该成果体现了半在线范式在提升GUI智能体长程规划能力与任务鲁棒性方面的关键作用。
感兴趣的朋友可戳下方点链接获取更多内容~
论文地址:https://arxiv.org/abs/2509.11543
项目代码:https://github.com/X-PLUG/MobileAgent/tree/main/UI-S1
模型地址:https://huggingface.co/mPLUG/UI-S1-7B
文章来自于微信公众号 “量子位”,作者 “量子位”


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
