# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Agentic AI时代,已经到来!
英伟达GTC大会上,老黄公开表示,当AI具备了感知和推理能力时,智能体AI就诞生了。
「它如同数字世界的「机器人」,本质是理解-思考-行动」。

当前,AI智能体革命已至临界点。国内外科技巨头纷纷加速布局,全力争夺这一赛道主导权。
据Gartner预测,到2028年,AI智能体将参与人类约15%的日常工作决策。
Georgian报告也显示,如今,91%的企业研究主管正计划在内部铺开Agentic AI的落地应用。
然而大规模部署之前,「交互速度」与「成本控制」仍是横亘在许多企业面前的两大关键挑战。
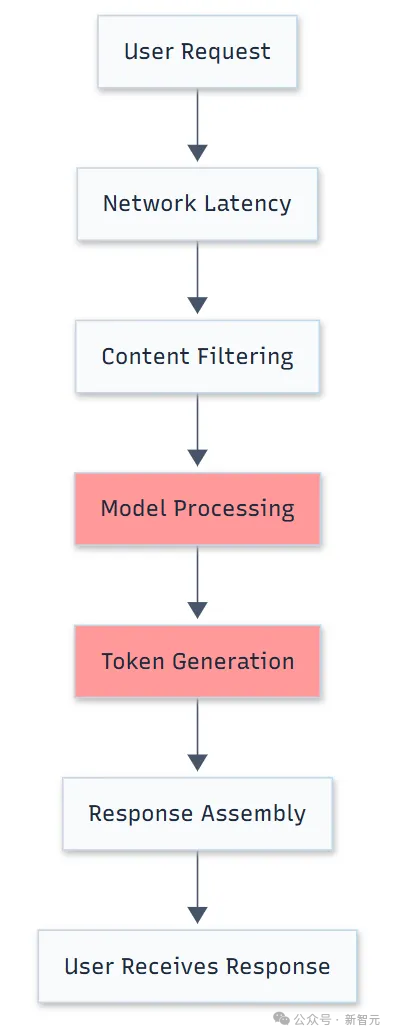
这里有简单的一个案例,就足以说明一些问题。
国外一支开发团队基于Azure的OpenAI服务,构建了一个智能体。然而,随着时间的推移,响应变得越来越慢,一次简单查询耗费10秒以上。
当他们用OpenAI API测试完全相同的提示词后发现:OpenAI响应时间为1-2秒,Azure则需要5-10秒。
同一款模型,同一个提示词,却有五倍差异。
要知道,智能体的交互速度,直接决定了用户体验的质量。如今,人们对AI响应速度的期待,已从「秒级」进化到「毫秒级」。
不仅如此,成本又直接决定了智能体产业化的可行性。多智能体的协作,对低延迟和token消耗又提出了更高的要求。
分毫必争的响应速度,决定了人们是否愿意买单;而真金白银的投入,则决定了企业能否持续推动AI智能体落地。
那么,如何才能既要又要呢?
在2025人工智能计算大会上,浪潮信息重磅发布了两大破局创新系统:元脑SD200超节点AI服务器,以及元脑HC1000超扩展AI服务器。

Scaling Law下一站:AI智能体爆发
2025年,大模型的Scaling并未放缓,而是进入了一个全新的阶段。
Scaling Law的焦点,早已从「预训练」转向了「推理」。
从o3、Gemini 2.5,到Grok 4、GPT-5,全球顶尖AI不断迭代,每一次发布都刷新了以往SOTA。
这一演进的节奏仍在加速。爆料称,谷歌Gemini 3.0、OpenAI Sora 2都将于十月初面世。

反观国内,DeepSeek R1/V3.1-Terminus、Qwen家族等开源模型,月更、周更已成为常态。
在能力边界上,LLM正从纯文本,走向了融合视觉、听觉的多模态模型,并逐步演变为一个底层「操作系统」。
可以预见,AI能力将依旧会指数级增长——
LLM性能越来越强,所处理的任务长度和复杂度,也在不断提升。
我们看到,Scaling Law推动的模型参数量,从百亿千亿向万亿、甚至百万亿迈进。
与此同时,在后训练阶段增加算力投入,可显著提升LLM推理能力。
为何这一转变如此重要?因为「推理」是构建Agentic AI的基础。
众所周知,2025年,是「智能体元年」。作为LLM的核心应用形态,智能体落地进入了爆发期。
在这一赛道上,谷歌、OpenAI、Anthropic等巨头竞相布局。
比如,OpenAI的「编码智能体」GPT-5-Codex深受开发者欢迎;另外,还有正在内测的「GPT-Alpha」,具备高级推理、全模态,可以调用工具。
然而,AI智能体的产业化落地并非易事。
能力、速度和成本,成为了当前AI智能体产业化决胜的「铁三角」。
AI不再局限于技术演示、实验,而要深入场景,成为创造可衡量价值的核心生产力。
这意味着,商业成功的核心已从单纯追求模型能力,转向对能力、速度、成本三者的综合平衡。
交互速度:决定智能体的商业价值
在智能体时代,速度不再是锦上添花,而是生存底线。token的吞吐速度,已成为AI应用构建的「隐形计时器」。
在人机交互时代,我们对AI延迟感知不强,只要响应速度跟上人类阅读思维即可。
一般来说,只要满足20 token/s输出速率,就能实现流畅的阅读体验。
而现在,AI的游戏规则彻底改变。
交互主体不再是「人-机」对话,而是「智能体-智能体」的高频博弈。
延迟哪怕是几毫秒,也可能导致决策失效。而且,在规模化商业部署中,这种差异会被无限放大,形成「以快杀慢」的绝对碾压。
智能体间交互,多为「小数据包」高频通信。这好比修了16条车道高速公路,AI只跑两公里,巨大的带宽对于小包传输如同虚设。
而传统通信协议「上下高速」的过程,反而成了主要耗时。
延迟是会层层累加的。当前智能体仅是初露锋芒,未来互联网将由它们主导协作。
每一个交互环节的微小延迟,都会在复杂的协同网络中呈指数级放大,最终导致整个应用响应慢到无法接受。
如果延迟无法降低,那就失去了商业化的可能性。
举个栗子,在欺诈防控场景中,对智能体响应速率提出了极限要求——约10毫秒。
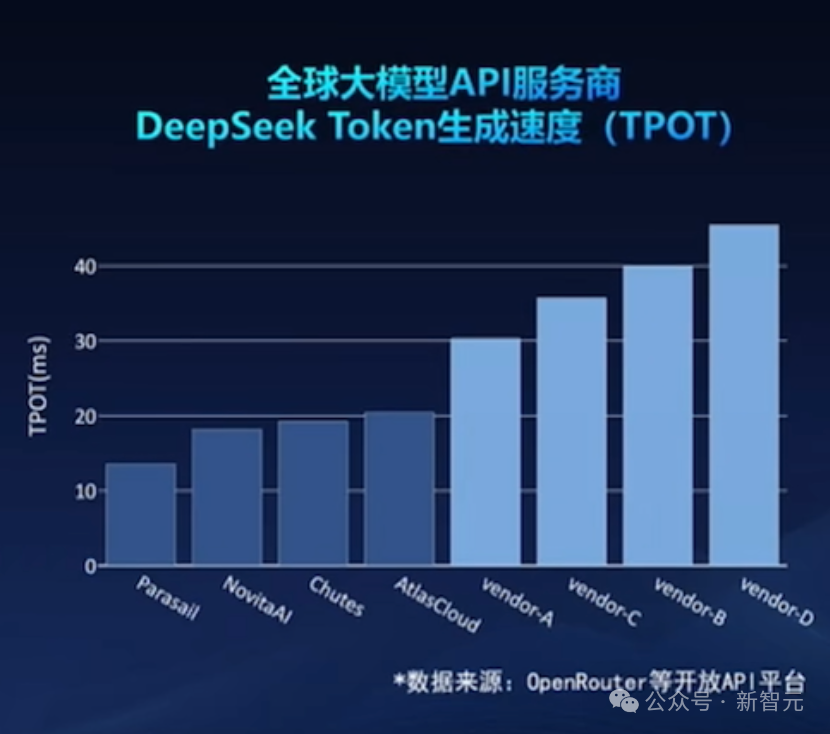
当前,DeepSeek响应速度基本在10-20毫秒左右,其他的普遍高于30毫秒。这远不足以支持AI的高频交互。
token成本:规模化的生死线
此外,token成本,是智能体能否实现规模化扩张,并且盈利的关键。
即便模型能力卓越,若token成本无法控制在合理范围内,高频、并发的实际应用,将难以持续。
一方面,LLM存在着「token膨胀」效应:推理前思考过程已产生上千万token。一个复杂任务,直接让token成本指数级暴涨。
那么,是什么原因导致token思考数暴增?
首先必须承认的是,模型本身算法能力差异是影响因素之一。
不同LLM在设计和训练过程中,算法架构和优化策略各有优劣,而优化程度更高的LLM可通过更高效推理路径,在较少token消耗下完成相同的任务。
其次,底层计算架构选择路径等,也会进而影响token成本。
因为LLM运行有依赖于底层的计算架构,包括硬件加速器、分布式计算框架等等。
若是计算架构无法高效支撑LLM推理需求,比如在分布式系统中存在通信瓶颈或计算资源分配不均,LLM可能需要生成更多token「绕路」完成任务。
当前,在做AI Coding的程序员,每月消耗token数比一年前平均增长约50倍,达到1000万-5亿token。
企业每部署一个智能体,平均token成本大概1000-5000美元。未来五年,token消耗预计增长100万倍。
可见,不论是速度,还是成本,都成为AI智能体商业化落地的最大挑战。
面对这个难题,我们该如何解?
两大核心方案,拿下速度成本难题
浪潮信息,同一时间给出了两大解决方案——
元脑SD200超节点AI服务器
元脑HC1000超扩展AI服务器
元脑SD200
若要实现更低延迟token生成能力,就需要在底层基础设施,比如架构、互联协议、软件框架等关键点上,实现协同创新。
浪潮信息新的突破,在于元脑SD200超节点AI服务器。
如前所述,DeepSeek R1在元脑SD200上token生成速度实现了8.9毫秒。
目前,最接近的竞争对手,最好的数据是15毫秒。这是国内首次将智能体实时交互,带入到10毫秒时代。
为何元脑SD200能够取得如此大的速度突破?
这背后离不开团队,融合了智能体应用和超节点开发的技术成果。
· 首创多主机3D Mesh系统架构
它可以实现单机64路本土AI芯片纵向扩展(Scale Up),提供4TB显存和6TB内存,构建超大KV Cache分级存储空间。
而且,单节点即可跑4万亿参数LLM,或同时部署多个协作的智能体。
此外,在硬件设计上还支持了「开放加速模组」(OAM),兼容多款本土AI芯片。
· 跨主机域全局统一物理地址空间
团队还通过远端GPU虚拟映射技术,突破了跨主机域统一编址的难题,让显存统一地址空间扩展8倍。
它还支持拓扑动态伸缩,可按需扩展128、256、512、1024卡的规模。
通过Smart Fabric Manager,元脑SD200实现了单节点64卡全局最优路由,保障了芯片间通信路径最短,进一步缩短了通信延迟。

最重要的是,互连协议的设计,是元脑SD200实现极低延迟的关键。
首先,团队采用了基建的协议栈,只有物理层、数据链路层、事务层三层协议,原生支持Load/Store等「内存语义」,GPU可直接访问远端节点的显存或主存。
并且,基础通信延迟达到了「百纳秒级」。
其次,浪潮信息Open Fabric原生支持由硬件逻辑实现的链路层重传,延迟低至微秒级。
不依赖OS、软件栈,它就能匹配更低延迟、更高吞吐的AI推理场景。
元脑SD200还采用了,分布式、预防式流控机制,无需丢包或ECN来感知拥塞。
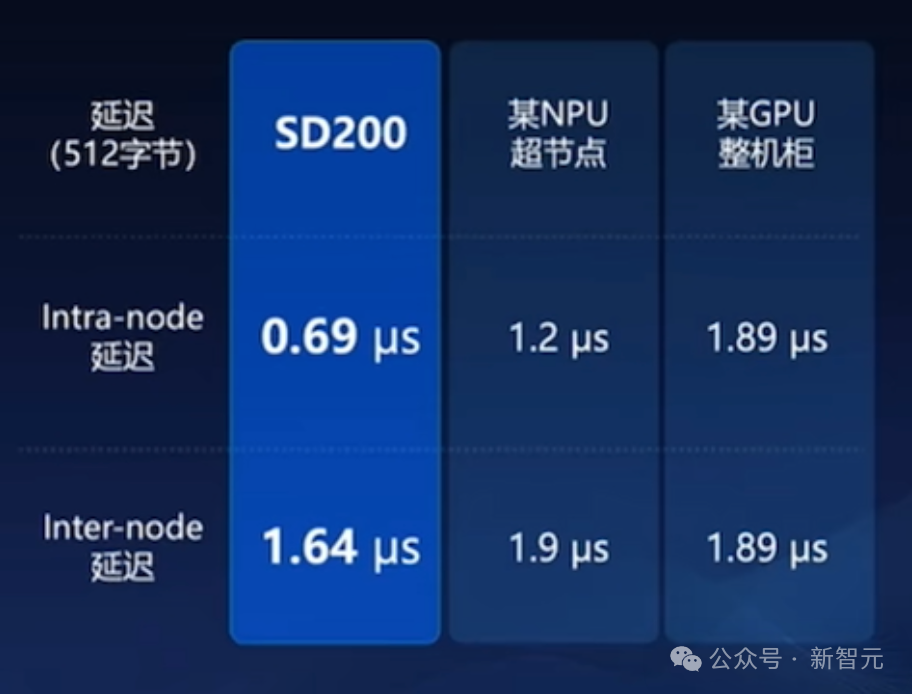
得益于以上高效、可靠的协议设计,元脑SD200实现了业界最低0.69微秒通信延迟。
当然了,超节点的大规模商业化应用,还必须依靠整机的高可靠的设计。
为此,浪潮信息从系统硬件层、基础软件层、业务软件层,构建了多层次、可靠的保障机制。

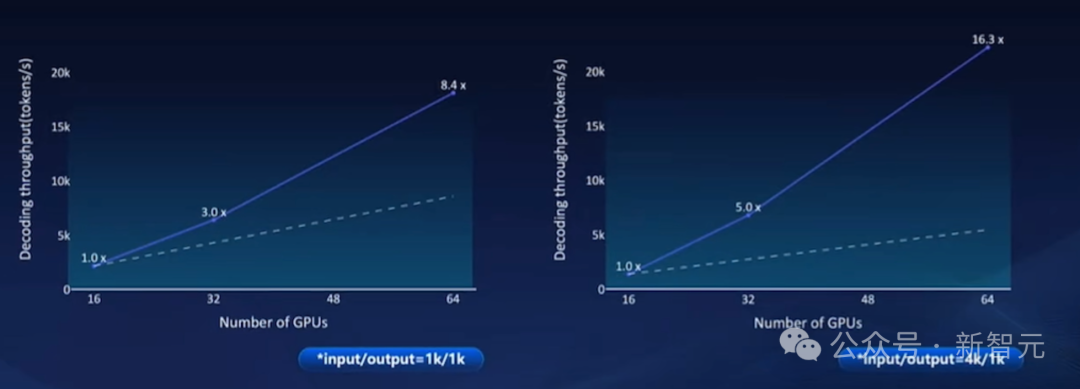
在元脑SD200上,团队还非常强悍地实现了推理性能超线性扩展。这意味着,性能的提升幅度超过了资源投入的增加幅度。
以DeepSeek R1-671B为例,从16卡扩展到64卡,实现了16.3倍超线性的扩展率!
具体来看,元脑SD200将这件事做到了极致的完美:
通过PD分离策略、动态负载均衡等技术,充分发挥出了超节点的架构优势,让系统内部的处理流程变得极其高效,资源竞争和拥堵被降到最低。
最终,将通信耗时控制在了10%以内。
可以设想,在实际高并发场景下,当请求量急剧攀升时,系统能够高效地将负载均匀分布至各个计算单元,避免了个别节点的「拥堵」拖累整个系统的响应时间。
这意味着,无论是第1个请求,还是第100万个请求,都能获得同样稳定且低水平的延迟。
既能「跑得快」又能「跑得多」,保证绝对极致的低时延,这就是实现规模化的生命线!
基于软件生态FlagOS,元脑SD200还能继续兼容更大的生态,主流代码即可直接编译运行。
当前,元脑SD200已实现对Pytorch算子的全覆盖,AI4S的典型应用可以一键迁移。
如下所示,64个AlphaFold 3蛋白质结构预测,即可在一台元脑SD200超节点AI服务器同时运行。

速度挑战解决之后,token成本又该怎么打下来?
元脑HC1000
为此,浪潮信息给出的答案是——元脑HC1000超扩展AI服务器。
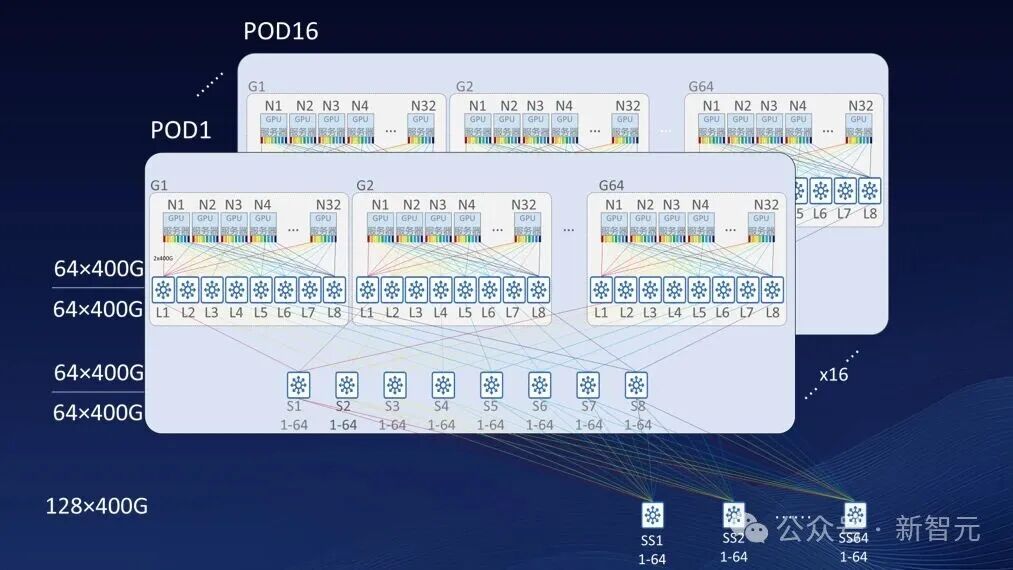
它基于全对称DirectCom极速架构打造,能够聚合海量的本土AI芯片,支持极大的推理吞吐。
对于一个企业来说,在起步探索、POC阶段,平台通用性更加重要,可以快速验证想法,抢占市场先机。
这对其创新、迭代的速度,至关重要。
但当它进入大规模部署阶段,即应用被市场验证,token调用数呈指数级增长是时,核心目标又转变为——高效、低成本运营。
而元脑HC1000,就能把推理成本打到最低1元/百万token。
· 全对称DirectCom极速架构
DirectCom极速架构,每计算模组配置16颗AIPU,采用了直达通信的设计,解决了传统的服务器架构下,协议转换和带宽增强问题,实现了超低延迟。
计算通信1:1均衡配比,实现了全局的无阻塞的通信。
传统意义上,计算与通信是互斥关系,计算时不会传输,计算完成后再传。
当前,有很多将计算和通信结合的策略,主要是把原来在传过程,针对GPU等待时间做优化。
除此之外,还包含了许多细粒度的任务,比如不同模型架构,不同并发情况,通信数据块大小和通信策略都要优化,才能提升效率。
HC1000还采用全对称的系统拓扑设计,可支持灵活PD分离、AF分离,按需配置算力,最大化资源利用率。
它还支持多元算力,让不同的芯片协同工作。
· 超大规模无损扩展
同时,HC1000支持超大规模无损扩展,实现从1024卡到52万卡不同规模的系统构建。
计算侧支持DirectCom和智能保序机制,网络侧支持包喷洒动态路由,实现了深度算网协同,相较传统RoCE方法提升1.75倍。
它还支持自适应路由和智能拥塞控制算法,将KV Cache传输对Prefill、Decode计算实例影响降低5-10倍。
总结来看,元脑HC1000是通过「全面优化降本」和「软硬协同增效」,实现了高效token生产力。
它不仅创新了16卡计算模组,单卡成本暴降60%+,每卡分摊系统均摊成本降低50%。
而且,它采用了大规模工业标准设计,降低了系统复杂度的同时,还提高了系统可靠性,无故障运行时间大幅延长。
系统采用的DirectCom架构保障了计算和通信的均衡,让算网协同、全域无损技术,实现了推理性能1.75倍飙升。
通过对LLM的计算流程的细分和模型结构的解耦,实现了计算负载的灵活的按需配比。
单卡MFU计算效率,最高可以提升5.7倍。
元脑SD200+元脑HC1000,成为浪潮信息两大「杀手锏」,分别攻克了AI智能体应用速度和成本难题。
那么,下一步又该走向何方?
「专用计算架构」是未来
近期,OpenAI在算力布局上,动作频频:
先是和甲骨文签下3000亿美元大单,随后又获得英伟达100亿美元的投资。
紧接着,他们又官宣了「星际之门」五大超算全新选址计划。
这一系列举措,无不指向一个核心事实——对于LLM训练和部署而言,算力需求始终是一个「无底洞」。
当前,AI算力的可持续发展正面临三大关键挑战:
目前,市面上的「AI芯片」仍以通用芯片为主。
GPU,是增加了CUDA核心和矩阵运算Tensor核心的传统图形计算芯片;ASIC,则是优化了矩阵计算和张量处理的通用矩阵计算芯片。
但正如前文所述,这些基于通用计算架构的方案,正逐渐在能效比和成本效益上触及瓶颈。
仅是单纯依靠堆叠更多计算单元,或是提升制程工艺的传统路径,难以沿着scaling Law在算力规模、能耗、成本之间取得平衡。
其原因在于,通用架构虽然适用性强、易于产业化推广,但效率低下。
相比而言,应用面较窄的专用架构,则有着更高的效率。
对此,浪潮信息AI首席战略官刘军认为,未来的关键便是在于「发展AI专用计算架构」:
我们必须推动发展路径的转变,要从一味地追求规模扩展,转向注重提升计算效率。
并以此为基础,重新构思和设计AI计算系统,大力发展真正面向AI应用的「专用计算架构」。
具体而言,就是从硬件层面来优化算子与算法,定制出大模型专用芯片,进而实现软硬件层面的深度协同优化,即「算法硬件化」。
只有这样才能让性能的Scaling,追上token的高速增长。
这不仅是突破算力瓶颈的必经之路,更是推动AI产业迈向下一阶段的基石。
面对大模型时代,浪潮信息的前瞻性思考为业界指明了一条方向:通过创新计算架构,让AI更好地走向落地。
文章来自于微信公众号 “新智元”,作者 “新智元”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
