# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在HLE(“人类最后考试”)的专家校验子集上,首次有系统突破60分大关!
就在最近,由耶鲁大学唐相儒、王昱婕,上海交通大学徐望瀚,UCLA万冠呈,牛津大学尹榛菲,Eigen AI金帝、王瀚锐等团队联合开发的Eigen-1多智能体系统实现了历史性突破——
在HLE Bio/Chem Gold测试集上,Pass@1准确率达到48.3%,Pass@5准确率更是飙升至61.74%,首次跨越60分大关。这一成绩远超谷歌Gemini 2.5 Pro(26.9%)、OpenAI GPT-5(22.82%)和Grok 4(30.2%)。
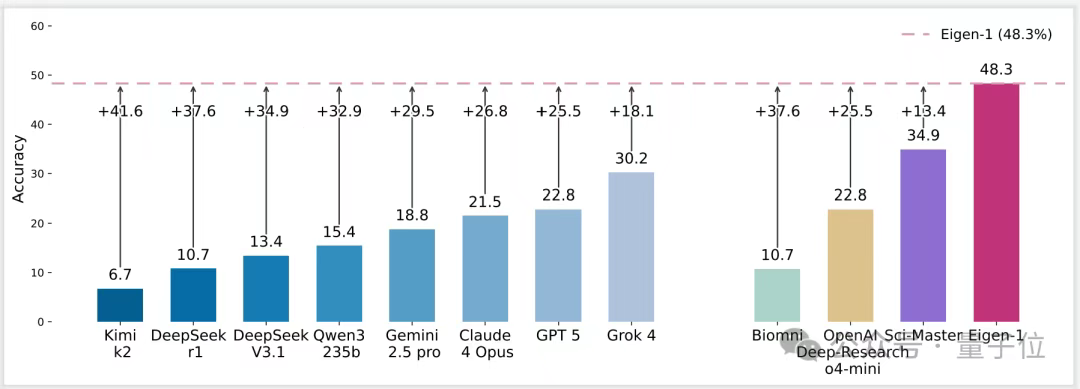
最令人振奋的是,这一成就并非依赖闭源超大模型,而是完全基于开源的DeepSeek V3.1搭建。
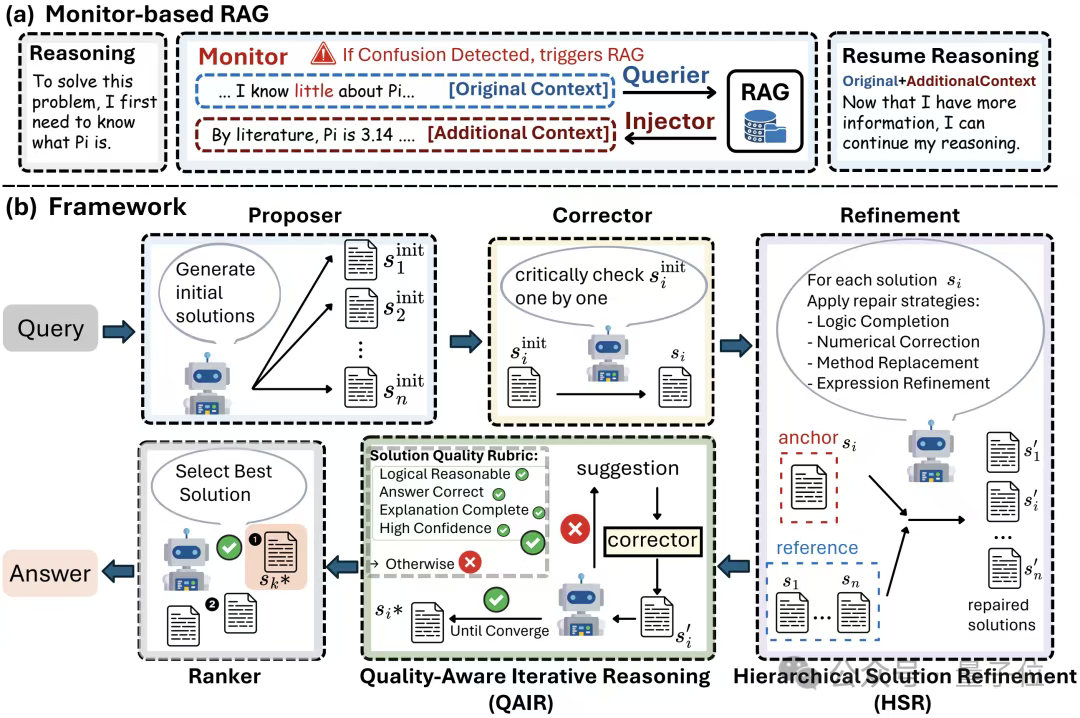
在这个开源底座上,研究团队通过叠加Monitor-based RAG(隐式知识增强)、HSR(分层解法修复)、QAIR(质量感知迭代推理)三大创新机制,实现了质的飞跃。
下面详细展开——
当AI开始挑战人类知识的终极边界,一场前所未有的较量正在上演。
当大模型在MMLU、GPQA等传统基准上纷纷“卷到90分”时,这些测试逐渐失去了区分力。为了追踪AI在科学推理前沿的真实进展,Center for AI Safety与Scale AI联合推出了“人类最后的考试”(Humanity’s Last Exam,HLE)——
涵盖数学、自然科学、工程学、人文社科等百余领域共3000道博士级难题,被视为AI知识推理的终极试炼。
而HLE Bio/Chem Gold则是HLE的黄金标准子集,包含149道经过领域专家人工审核和纠正的题目。
相比原始HLE数据集,这个子集排除了可能存在歧义或错误答案的问题,确保了标签的准确性和可靠性,因此成为评估AI科学推理能力最可信的基准。
正是在HLE Bio/Chem Gold子集上,Eigen-1系统首次跨越60分大关,而这背后离不开其三大创新机制。
1. Monitor-based RAG:告别“工具税”的隐式检索增强
传统的检索增强生成(RAG)系统就像一个频繁暂停的视频播放器——每次需要外部知识时,都必须中断推理流程、构建查询、处理结果,再重新整合上下文。
研究团队将这种开销形象地称为“工具税”(Tool Tax)——每次工具调用都会打断思考流程,导致上下文丢失。
传统RAG系统的“工具税”问题在下图的人口遗传学案例中展现得淋漓尽致。左侧显示模型过度自信地使用错误公式,右侧则展示了即使通过显式RAG获得正确公式,推理流程的中断导致模型无法将知识重新整合到原始问题中。

Eigen-1的Monitor-based RAG彻底改变了这一范式:
实验数据显示,与显式RAG相比,Monitor-based RAG将token消耗减少53.5%,将工作流迭代次数减少43.7%,同时保持了更高的准确率。
见下图单倍型计数案例,Monitor检测到重组约束的不确定性,Querier生成针对性查询,Injector注入两个关键事实,使模型能够排除无效案例并得出正确的30个单倍型答案。

2. Hierarchical Solution Refinement (HSR):从“民主投票”到“层级精炼”
除了隐式知识增强,Eigen-1还革新了多智能体的协作模式。
传统的多智能体系统采用“民主投票”机制,所有候选方案被平等对待,容易“稀释”最优解。
而Eigen-1引入的分层解决方案精炼(HSR)打破了这种假设。HSR采用“锚点—修复”结构:一个候选作为 anchor,其余作为参考依次修正,形成层次化协作。
在HSR框架下,每个候选解决方案轮流充当“锚点”,其他方案则作为“参考”提供针对性修正。这种设计让强方案能够吸收弱方案的有价值见解,而不是简单地进行平均。
具体包括四种修复维度:逻辑补全(填补缺失的推理步骤)、数值修正(纠正计算错误)、方法替换(用更优策略替代较弱方法)、表达优化(提升清晰度而不改变实质)。
这种设计让优质方案能吸收其他方案的有价值见解,而非简单平均。
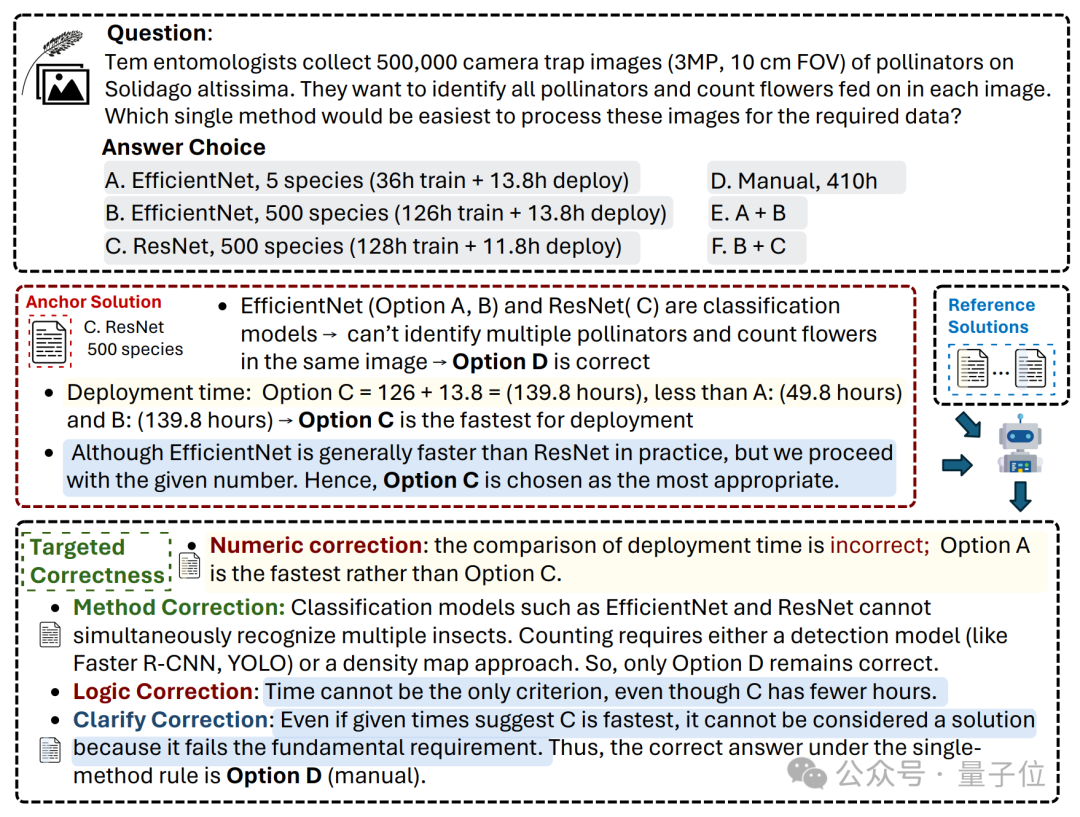
下图通过一个图像识别任务生动展示了HSR的工作原理。
面对昆虫识别和花朵计数的复合任务,锚点解决方案最初选择了ResNet(选项C),但存在部署时间计算错误。通过引入其他解决方案作为参考,系统进行了四类针对性修正。
3. Quality-Aware Iterative Reasoning (QAIR):质量驱动的迭代优化
质量感知迭代推理(QAIR)能根据解答质量自适应地调整迭代深度:高质量解答可提前收敛,低质量解答则触发更多探索,从而在效率与准确率之间取得平衡。
该机制为每个方案评估三个维度:逻辑性、答案正确性、解释完整性。只有未达标的方案才会进入下一轮修正,避免在低质量候选上浪费计算资源。
Eigen-1的优势不限于HLE:
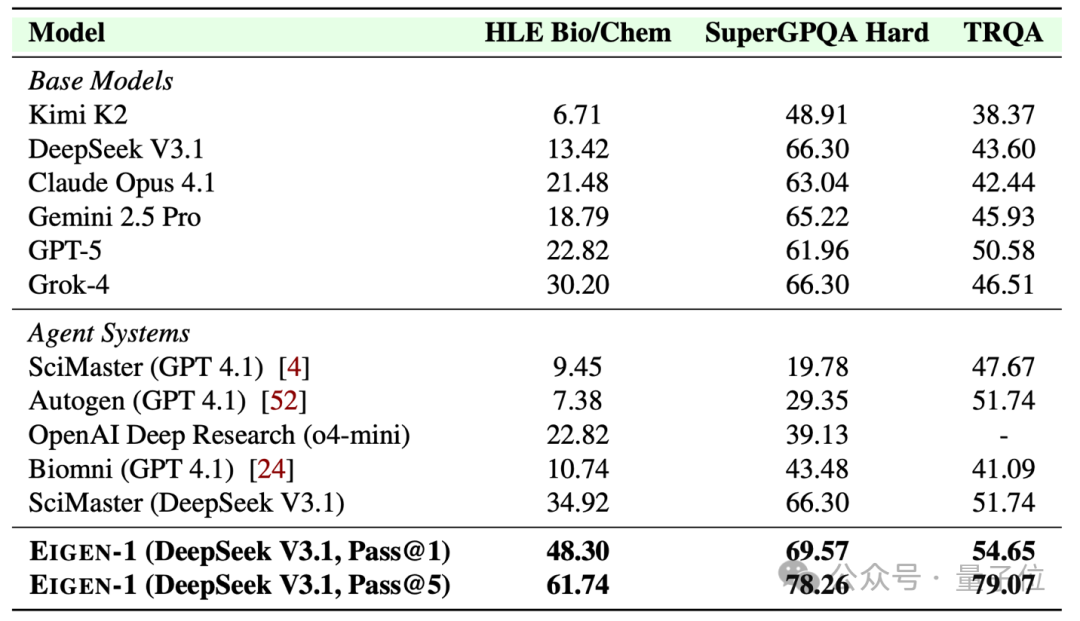
1、HLE Bio/Chem Gold(149题)
2、SuperGPQA生物学(Hard版)
3、TRQA文献理解
错误模式分析
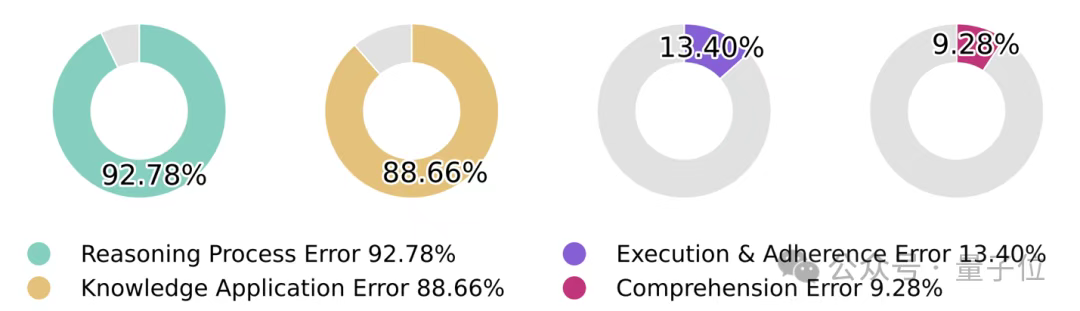
Figure 7的饼图揭示了一个关键洞察:92.78%的错误涉及推理过程问题,88.66%涉及知识应用问题,且两者存在大量重叠。
这表明科学推理的核心挑战不在于单纯的知识检索或逻辑推理,而在于如何将知识与推理无缝整合。
相比之下,执行遵循错误(13.40%)和理解错误(9.28%)占比较小,说明模型在指令理解和执行层面已经相对成熟。
组件贡献的精确量化
团队通过增量构建和消融实验精确量化了每个组件的贡献。
基线系统在没有任何外部知识的情况下只能达到25.3%的准确率,消耗483.6K tokens。加入显式RAG后,准确率提升到41.4%,但代价是工作流步骤从43.4激增到94.8,这正是“工具税”的直观体现。
当引入Monitor组件后,虽然准确率略降至34.5%,但token消耗骤降至218.4K,工作流步骤也降至51.3。
随着Querier和Injector的加入,准确率恢复到40.3%。HSR的引入将准确率提升至43.7%,最后QAIR将完整系统的准确率推至48.3%,同时保持了高效的资源利用(218.9K tokens,53.4步骤)。
消融实验从另一个角度验证了各组件的必要性。移除Monitor导致token消耗激增至461.3K,工作流步骤增至95.3,显示了隐式增强的巨大价值。
移除HSR或QAIR分别导致准确率降至44.8%和43.7%,证明了层级精炼和质量感知迭代的重要作用。

多样性与共识的微妙平衡
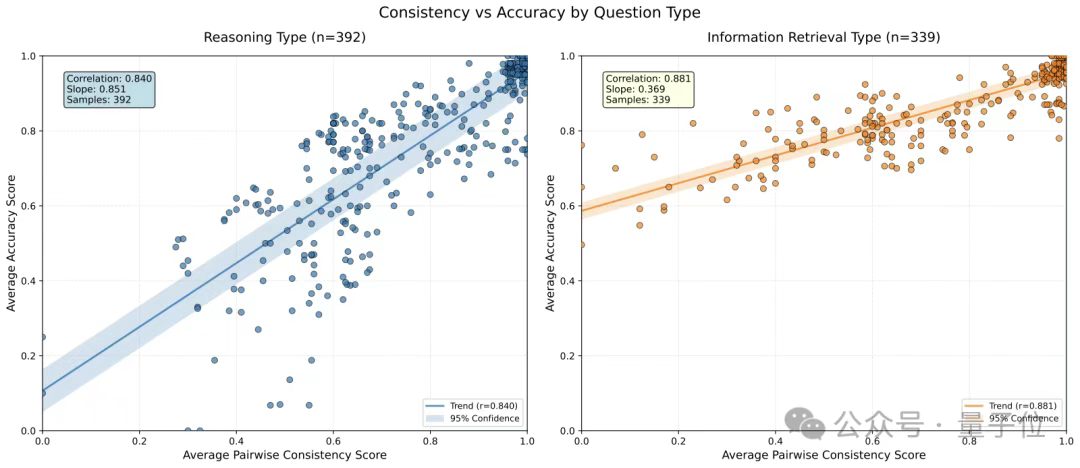
作者通过散点图和回归分析揭示了一个违反直觉但极具启发性的发现。
在信息检索任务(339个样本)中,解决方案之间的一致性与准确率呈现较弱的正相关(斜率0.369),意味着不同的检索路径和视角能带来互补信息,多样性是有益的。
而在推理任务(392个样本)中,情况完全相反——一致性与准确率呈现强正相关(斜率0.851),表明当多个推理路径得出相同结论时,这个结论很可能是正确的。
因此,检索型任务应鼓励解法多样性与并行路线;纯推理型任务应倾向早期共识与收敛。
这一发现为未来智能体系统的任务自适应设计提供了重要指导。
工具税的精确量化
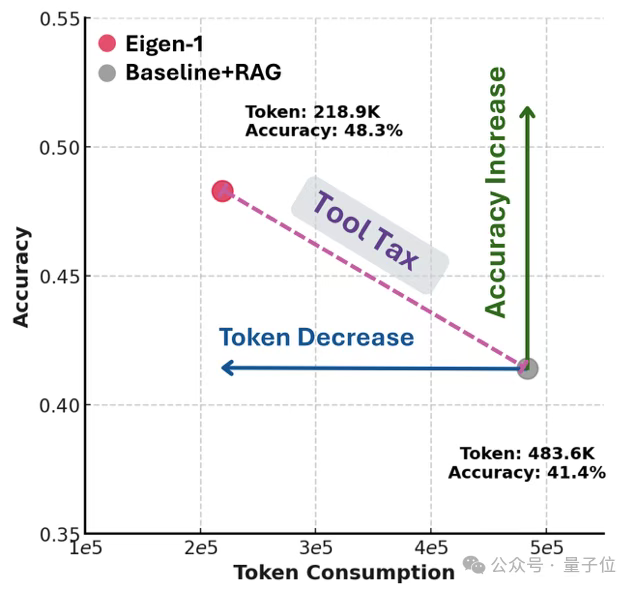
最后,作者通过对比准确率提升与token减少的关系,直观展示了隐式增强相对于显式RAG的巨大优势。
传统的基线+RAG方案虽然能提升准确率,但以巨大的计算开销为代价,在图中表现为向右上方延伸(准确率提升但token增加)。
而Eigen-1则位于左上象限,在大幅提升准确率的同时减少了53.5%的token消耗,工作流迭代次数也从94.8步降至53.4步,减少了43.7%。这种“既要又要”的成果,正是架构创新的价值所在。
Eigen-1首次突破60分的意义远超一个基准测试:Eigen-1更预示着AI辅助科学研究的新范式。
当AI能够真正理解和推理人类知识前沿的复杂问题时,它将成为科学家的强大助手,加速从基础研究到应用转化的全过程。
研究团队表示,未来将继续优化架构设计,探索向其他科学领域的扩展,并研究如何将这些技术整合到更广泛的科学工作流中。随着更多研究者加入这一开源生态,我们有理由期待科学AI将迎来更快速的发展。
正如团队所言:“HLE可能是我们需要对模型进行的一次重要的考试,但它远非AI的最后一个基准。”当开源社区携手推进,人类与AI协作探索未知的新时代正在加速到来。
论文链接:https://arxiv.org/pdf/2509.21193v1
项目地址:https://github.com/tangxiangru/Eigen-1
文章来自于微信公众号“量子位”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
