# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
刚发V3.1“最终版”,DeepSeek最新模型又来了!
DeepSeek-V3.2-Exp刚刚官宣上线,不仅引入了新的注意力机制——DeepSeek Sparse Attention。
还开源了更高效的TileLang版本GPU算子!

目前,官方App、网页端、小程序均已同步更新,同时还有API大减价:5折起。

这波DeepSeek国庆大礼包,属实有点惊喜了。
DeepSeek-V3.2-Exp基于上周刚更新的DeepSeek-V3.1-Terminus打造,核心创新是引入了DeepSeek Sparse Attention(DSA)稀疏注意力机制。
DSA首次实现了细粒度注意力机制,能在几乎不影响模型输出效果的前提下,实现长文本和推理效率大幅提升。
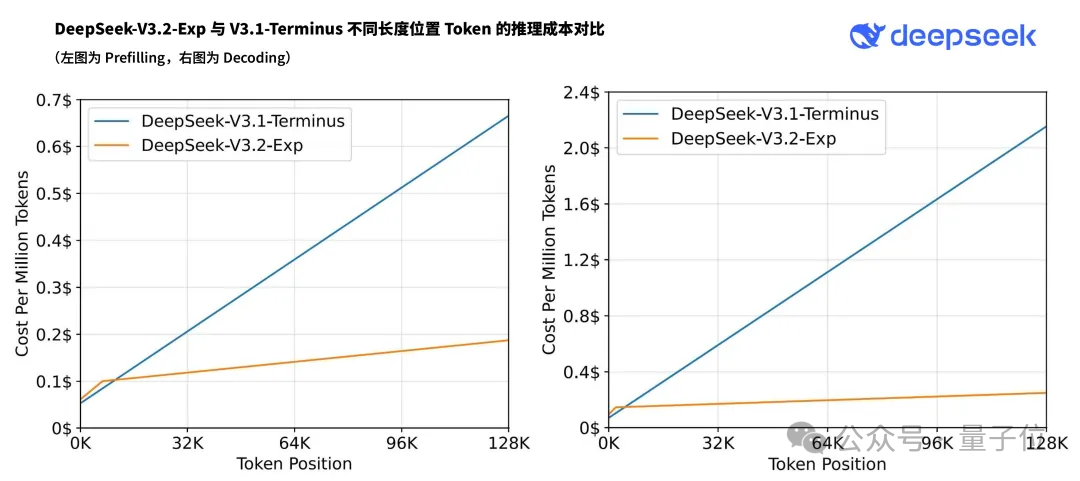
与前不久更新的DeepSeek-V3.1-Terminus对比,在各领域公开测评集上,DeepSeek-V3.2-Exp和V3.1-Terminus基本持平。
V3.1-Terminus是在 DeepSeek-V3.1基础上的一个强化版本,在稳定性、工具调用能力、语言一致性、错误修正等方面进行迭代改进。
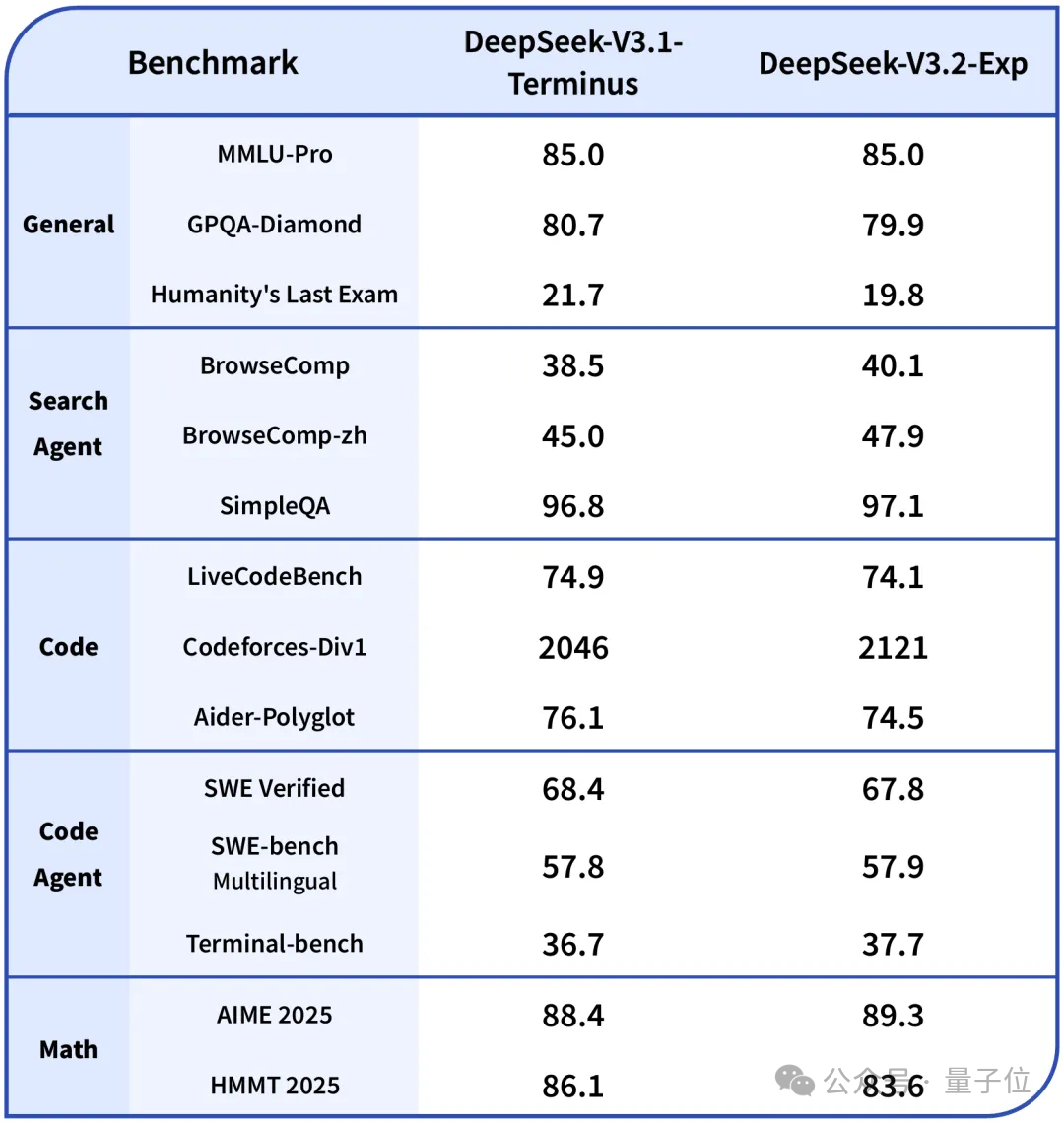
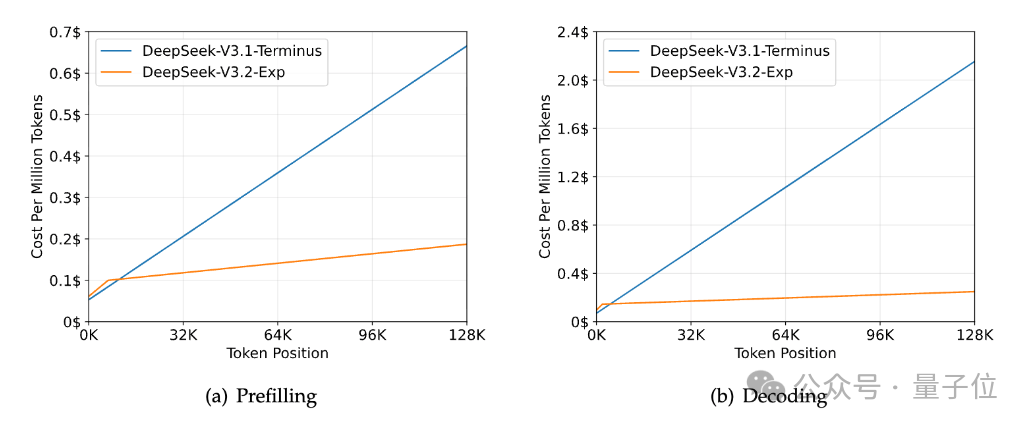
另外,论文提到,使用DSA的模型在处理128K长上下文时,推理成本显著低于DeepSeek-V3.1-Terminus,尤其在解码阶段。
DeepSeek还表示,在新模型研发过程中,需要设计和实现很多新的GPU算子。
他们使用高级语言TileLang进行快速原型开发,并在最后阶段,以TileLang作为精度基线,逐步使用底层语言实现更高效的版本。
因此,V3.2开源的主要算子包括TileLang和CUDA两种版本。

官方还附上一句:
我们建议社区在进行研究性实验时,使用基于TileLang的版本以方便调试和快速迭代。
官方API的价格也顺势来了个5折起,新价格即刻生效。
这还等什么…朋友们国庆整起来吧。
指路↓
HuggingFace:
https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp
ModelScope:
https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2-Exp
论文:
https://github.com/deepseek-ai/DeepSeek-V3.2-Exp/blob/main/DeepSeek_V3_2.pdf
除了DeepSeek-V3.2之外,据说智谱的GLM-4.6也在路上了。
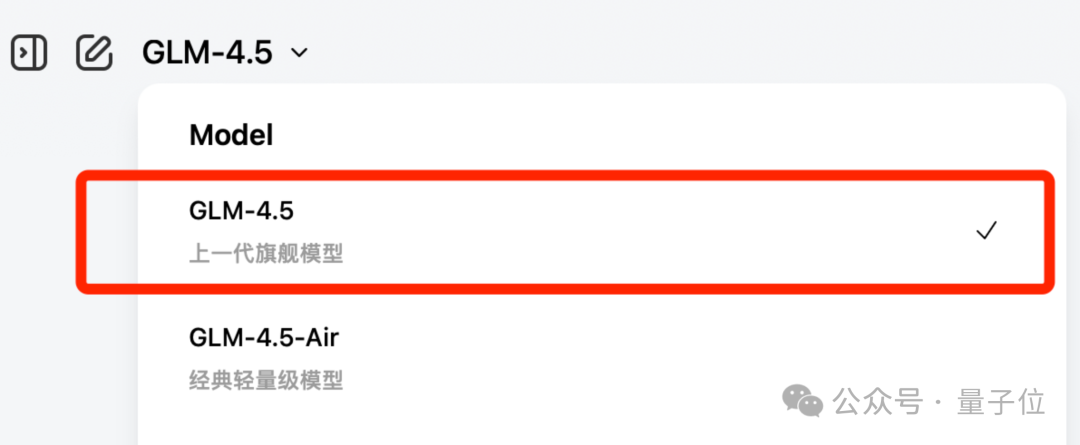
从下拉菜单可以看到,他们已经把GLM-4.5标成了“上一代旗舰模型”。
下午还刚在GitHub上刷到这张“国庆是休息日,请给我们关注的同学一点时间”的图:
好好好,为了放假,都打算在节前卷了是吧(手动狗头)。
文章来自于微信公众号 “量子位”,作者 “量子位”


