# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI生成第三视角视频已经驾轻就熟,但第一视角生成却仍然“不熟”。
为此,新加坡国立大学、南洋理工大学、香港科技大学与上海人工智能实验室联合发布EgoTwin ,首次实现了第一视角视频与人体动作的联合生成。
一举攻克了视角-动作对齐与因果耦合两大瓶颈,为可穿戴计算、AR及具身智能打开落地新入口。

EgoTwin 是一个基于扩散模型的框架,能够以视角一致且因果连贯的方式联合生成第一人称视角视频和人体动作。
生成的视频可以通过从人体动作推导出的相机位姿,借助 3D 高斯点渲染(3D Gaussian Splatting)提升到三维场景中。

下面具体来看。
第一视角视频的本质是人体动作驱动的视觉记录——头部运动决定相机的位置与朝向,全身动作则影响身体姿态与周围场景变化。
二者之间存在内在的耦合关系,无法被单独分离。传统视频生成方法难以适配这一特性,主要面临两大难题:
1.视角对齐难题
生成视频中的相机轨迹,必须与人体动作推导的头部轨迹精准匹配。但现有方法多依赖预设相机参数生成视频,而第一视角的相机轨迹并非外部给定,而是由穿戴者头部动作内生决定,需要二者同步生成以保证对齐。
2.因果交互难题
每一时序的视觉画面为人体动作提供空间上下文(如“看到门把手”引导伸手动作),而新生成的动作又会改变后续视觉帧(如“开门”导致门的状态与相机朝向变化)。这种“观察-动作”的闭环依赖,要求模型捕捉二者随时间的因果关联。

△EgoTwin能同时生成“第一视角的场景视频”和“匹配的人体动作”
为解决上述挑战,EgoTwin基于扩散Transformer架构,构建了“文本-视频-动作”三模态的联合生成框架,通过三大关键设计实现突破两大难题。
三通道架构是指动作分支仅覆盖文本与视频分支下半部分的层数。
每个通道均配备独立的tokenizer与Transformer模块,并以相同颜色标示跨通道共享的权重。
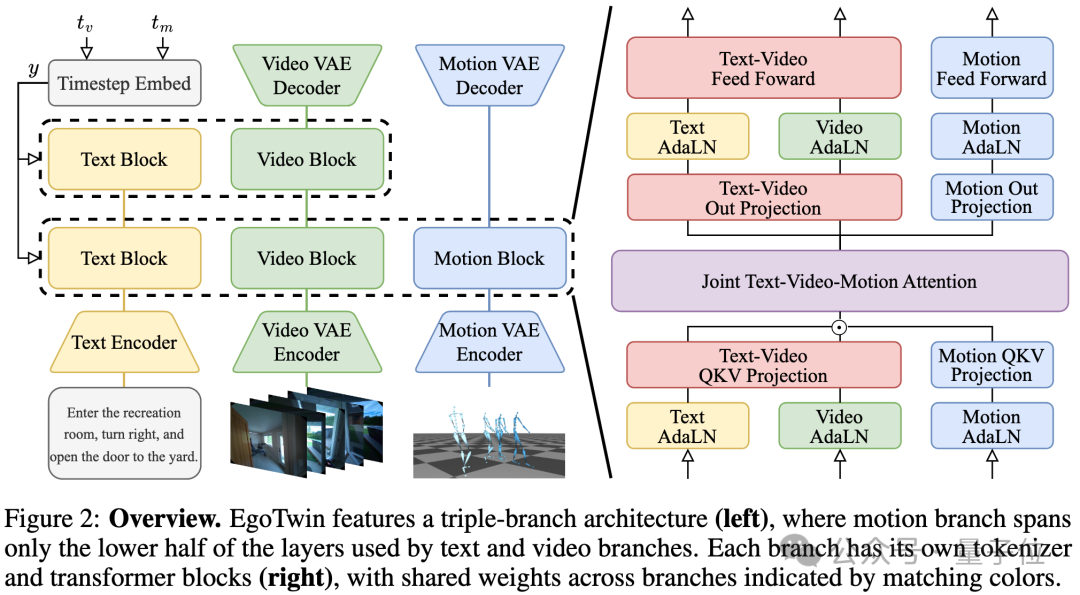
下图展示了“文本-视频-动作”三个模态的双向因果注意力交互机制。

传统人体动作表征以身体根部为中心,头部姿态需通过人体运动学计算推导,容易造成误差累计。
EgoTwin提出以头部为中心的动作表征,直接将动作锚定在头部关节,实现与第一视角观测精准对齐:

借鉴控制论中“观察-动作”反馈循环原理,EgoTwin在注意力机制中加入结构化掩码,实现了视频与动作之间的双向因果交互:
这种设计避免了“全局一致但帧级错位”的问题,实现细粒度时序同步。
考虑到视频与动作的模态差异(如动作采样率通常是视频的2倍),EgoTwin采用异步扩散训练策略:为视频与动作分支分别设置独立采样时间步、添加高斯噪声,再通过统一时间步嵌入融合,适配不同模态的演化节奏。
同时,框架采用三阶段训练范式,兼顾效率与性能:
模型能够根据文字和视频生成动作,或者根据文字和动作生成视频,甚至能把生成的视频和动作变成3D场景(比如还原出房间的 3D 结构,再把人的动作放进去)。
首先看一下可视化结果。

△基于文本联合生成视频和动作
EgoTwin还支持根据动作和文本生成视频(TM2V)、根据文本和视频生成动作(TV2M)额外二种生成模式。

△基于文本和动作联合生成视频

△基于文本和视频联合生成动作
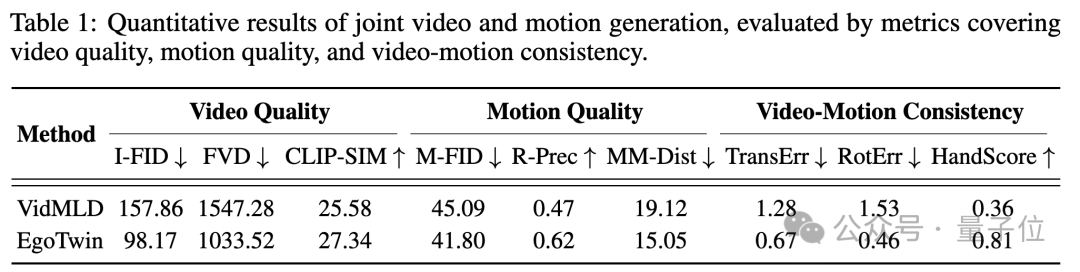
为客观评估,团队还从数据、指标、结果三方面系统展开测试。

实验证明,EgoTwin比之前的基础模型好很多:视频和动作的匹配度更高,比如镜头和头部的位置误差变小了,手的动作在视频里也更容易对应上;
消融实验进一步验证了核心设计的必要性:移除以头部为中心的动作表征、因果交互机制或异步扩散训练策略后,模型性能均出现明显下降,证明三大创新缺一不可。
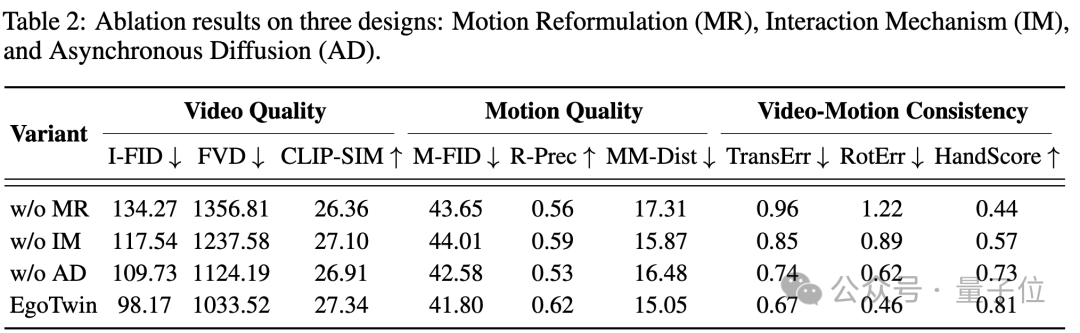
EgoTwin不仅显著缩小了跨模态误差,也为可穿戴交互、AR 内容创作、具身智能体仿真等应用提供了可直接落地的生成基座。
感兴趣的朋友可戳下方链接了解更多具体内容~
论文地址:https://arxiv.org/abs/2508.13013
项目主页与示例:https://egotwin.pages.dev
文章来自于微信公众号 “量子位”,作者 “量子位”


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
