# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
家人们,就在国庆放假前的今天凌晨,那个总在节前“搞事”的 DeepSeek,又双叒叕深夜悄然上线了!
讲真,DeepSeek 是真的不考虑我们媒体人的死活啊哈哈!每次都卡着放假前更新,之前大家都转发的吐槽截图,本人又翻出来了:

DeepSeek 最新的实验性模型 DeepSeek-V3.2-Exp 的更新精简成一句话来说就是:
在模型性能几乎不变的前提下,它处理长文本的成本,被打了个“严重骨折”!
(这对需要和海量文档、超长代码、复杂业务需求死磕的架构师和开发者来说,意味着很多因为 Token 成本和速度而“想都不敢想”的长文本 AI 应用,现在,可以放手去干了!)
要理解这次 DeepSeek 为什么这次更新能把成本“打骨折”,根本在于—让大模型又爱又恨的“自注意力机制” (Self-Attention)。
家人们可能都知道,自注意力机制是 Transformer 架构的核心,但也最烧钱、最吃性能。
首先,咱们来讲一下它的花钱原因:
自注意力机制,为了理解一篇文章里的某个词,它会把这个词跟文章里所有的其他词挨个比对一遍,计算关联度。文章短还行,一旦长到几十万字(比如 128K 上下文),这种“暴力”比对的计算量就成了天文数字。
专业点说,就是 O(L^2) 的复杂度,L 是文本长度。
而这也正是,为什么那么多听起来很炫酷的长文本应用,最后都因为高昂的成本,让无数开发者“从入门到放弃”
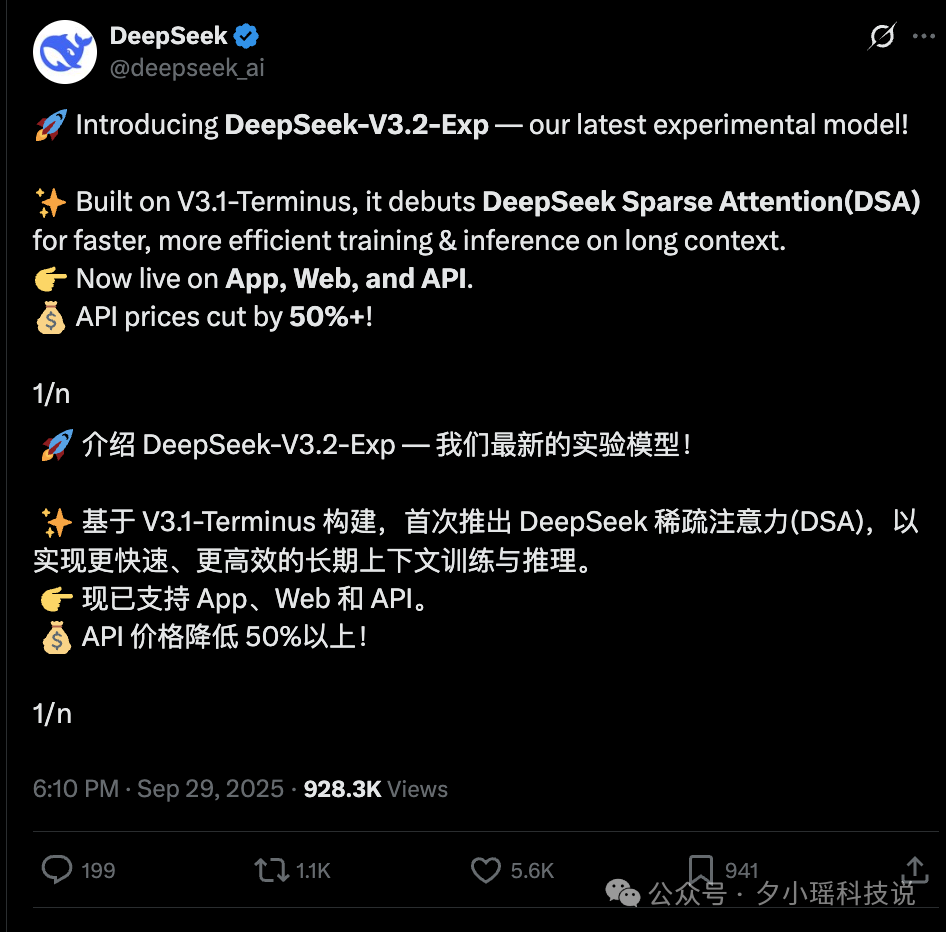
而 DeepSeek-V3.2-Exp 结合了 DS 最新的研究成果—深度求索稀疏注意力(DeepSeek Sparse Attention, DSA)。
DSA 是之前北大、梁文锋一起合作、荣获 ACL2025BestPaper 的《Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention》工作的延续。

技术报告传送门:
https://github.com/deepseek-ai/DeepSeek-V3.2-Exp/blob/main/DeepSeek_V3_2.pdf
DSA 的思路是给模型装上了一个高效“导航仪”:
这么一通操作下来,计算复杂度就从 O(L^2) 骤降到了 O(L·k),其中 k<<L,k 是个固定的几千,而 L 可以是几十万。这个优化效果,懂的都懂啊!
更关键的是,这种效率提升并非以牺牲性能为代价。
在训练过程中,在 DeepSeek-V3.1 的基础上,首先采用简短的「密集预热」初始化闪电索引器,让它学会模仿原有模型的注意力分布,然后利用稀疏训练让整个模型适应新的稀疏模式,最后沿用与前代模型完全相同的专家蒸馏和混合强化学习(GRPO)的后训练。
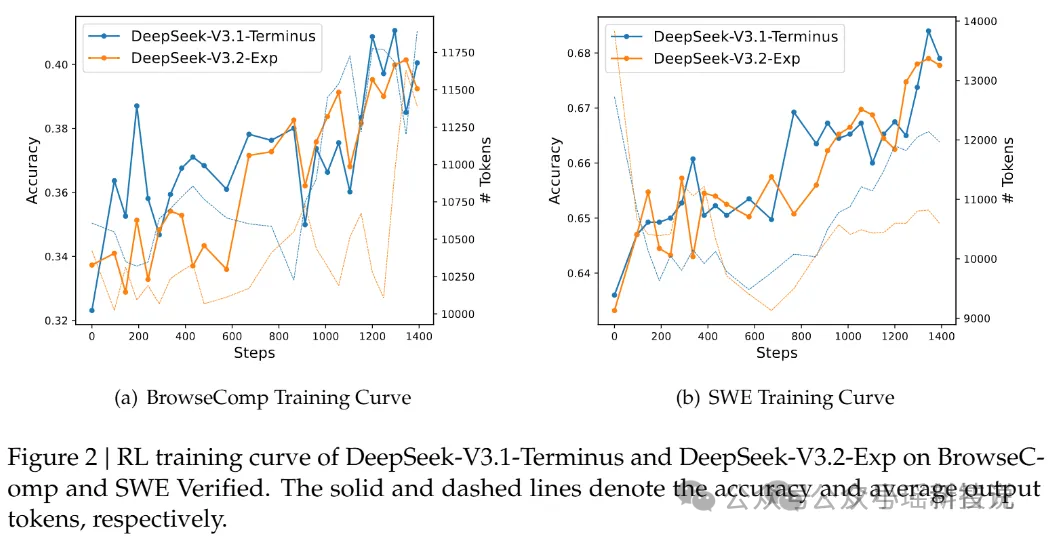
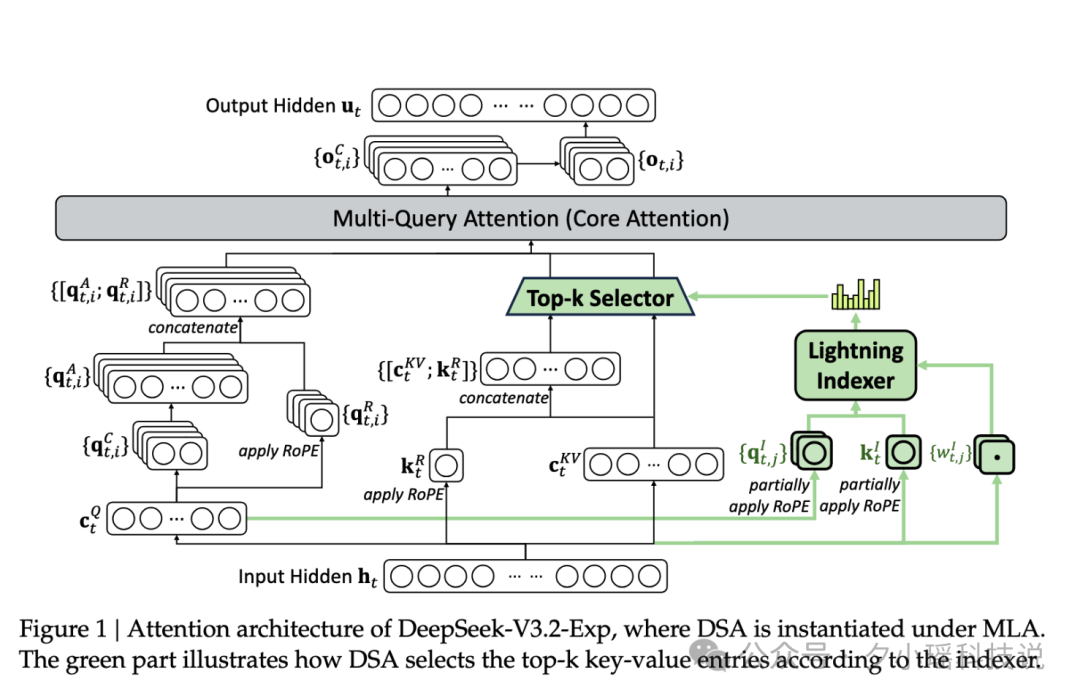
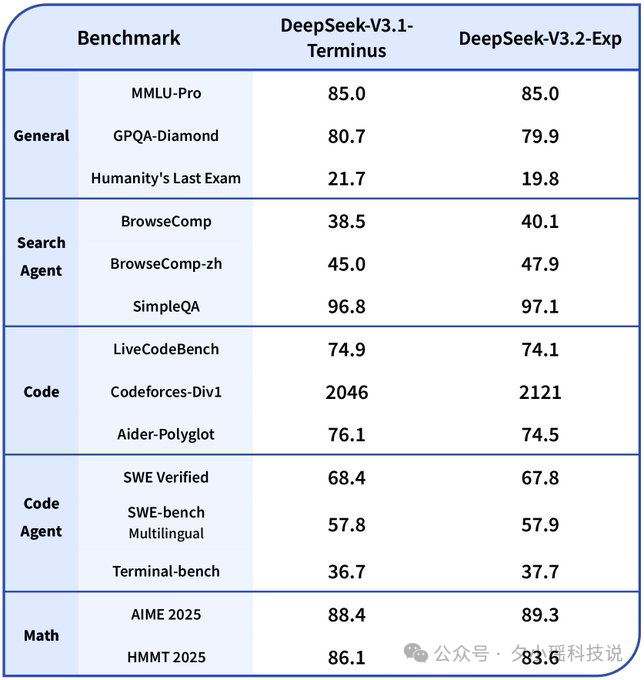
为了证明这种效率提升并非以牺牲性能为代价,DeepSeek 进行了“控制变量”的对比。他们让 V3.2-Exp 与上一代 V3.1-Terminus,在完全对齐的训练设置下较量:
结果显示,在所有关键领域的公开评测上,两者的表现基本一致,打成平手,而且,V3.2-Exp 在完成同样任务时,所消耗的 Token 量反而还大幅减少了。
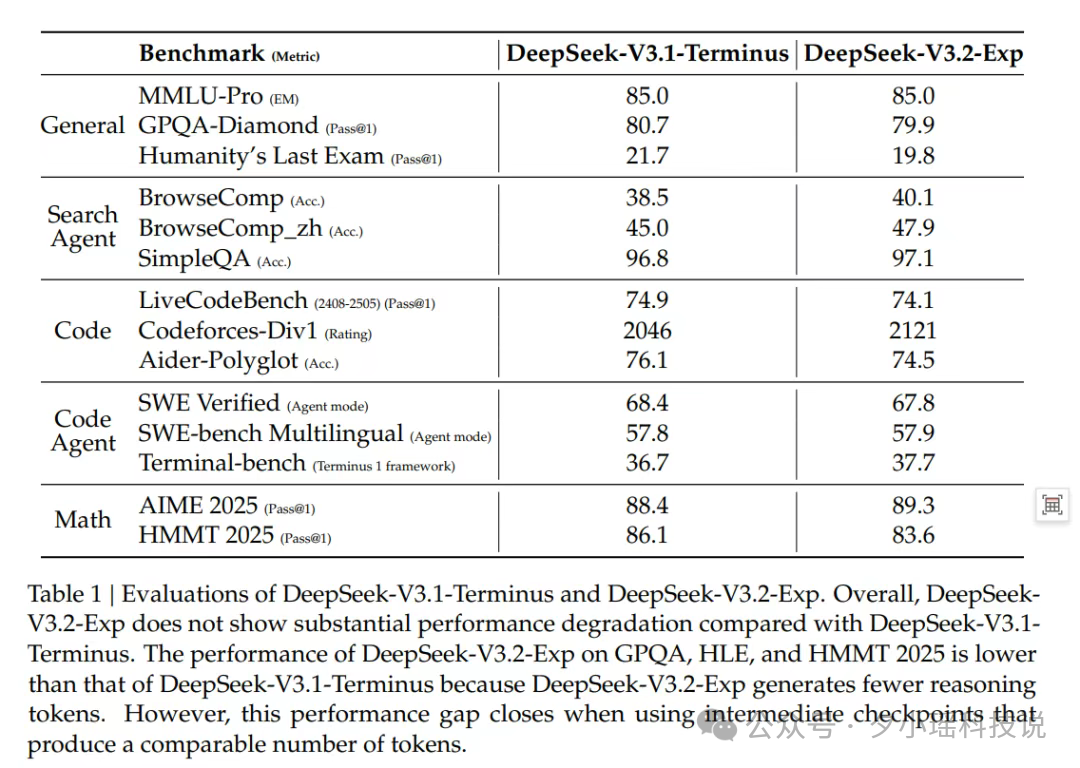
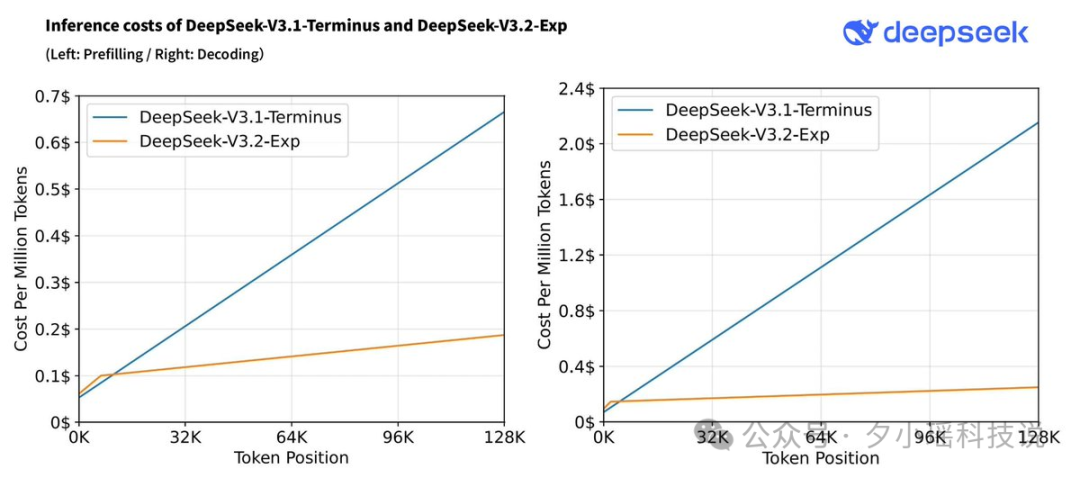
而且,落实到部署层面,其端到端的推理加速和成本节约,效果立竿见影:
模型传送门:
HuggingFace 地址:
https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp
魔搭社区地址:
https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2-Exp
现在已经可以在 DeepSeek 的 App、网页端和小程序上,立刻体验到最新的 V3.2-Exp 模型。
成本降低了,用户也收到了红利,因为官方的行动非常实在:
API 价格整体下调超过 50%,打折最狠的是输出 Token 的价格,直接打了 25 折—从原来的 12 元/百万 Token,降到了现在的 3 元/百万 Token,降幅高达 75%!

一个新模型的发布,其真正的“江湖地位”,不只看技术报告,更要看整个产业链对它的态度。而 DeepSeek-V3.2-Exp,就享受到了这种“行业风向标”级别的待遇。
模型刚一发布的 Day0,整个国产硬件就都疯狂打 Call”:



圈内捧得这么高,真实水平到底如何?作为大家的测评博主,咱们老规矩,直接上硬核实测,用上次测 V3.1 的“原题”再考一遍!
(上次测评 V3.1 的时候,还是很分裂。。。)
1. 学术题:
我是一个博士生,我最近在研究多模态 AIGC 内容的检测,请帮我想一种学术价值、创新价值都很好的 idea,我想发顶会!
V3.2:




DeepSeek V3.1:


家人们!回答质的飞跃啊!!
相较于 V3.1,它不仅在学术逻辑的严谨性、思路的创新性上有了降维打击,更补全了之前欠缺的“Storytelling”能力,把一个 idea 的来龙去脉、价值潜力讲得明明白白。看得我眼前一亮!
2. 编程题
帮我开发一个基于 Web Audio API 的网页播放器,我希望你实时分析音乐频谱和节拍,配合驱动一个动态生成的、响应音乐情感的抽象视觉背景
V3.2:
V3.1:
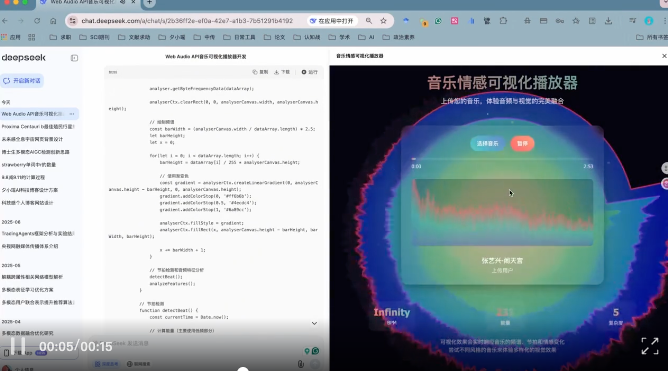
嘶,眼前一黑。要知道,上次 V3.1 在这个问题上表现可是相当惊艳的。看来,V3.2 还不够完美!
再看看上次翻车的小球题:
20 个小球在旋转的 6 边形内弹跳,考虑重力,弹力,摩擦力等物理规律。 用 p5js
V3.2:

V3.1:
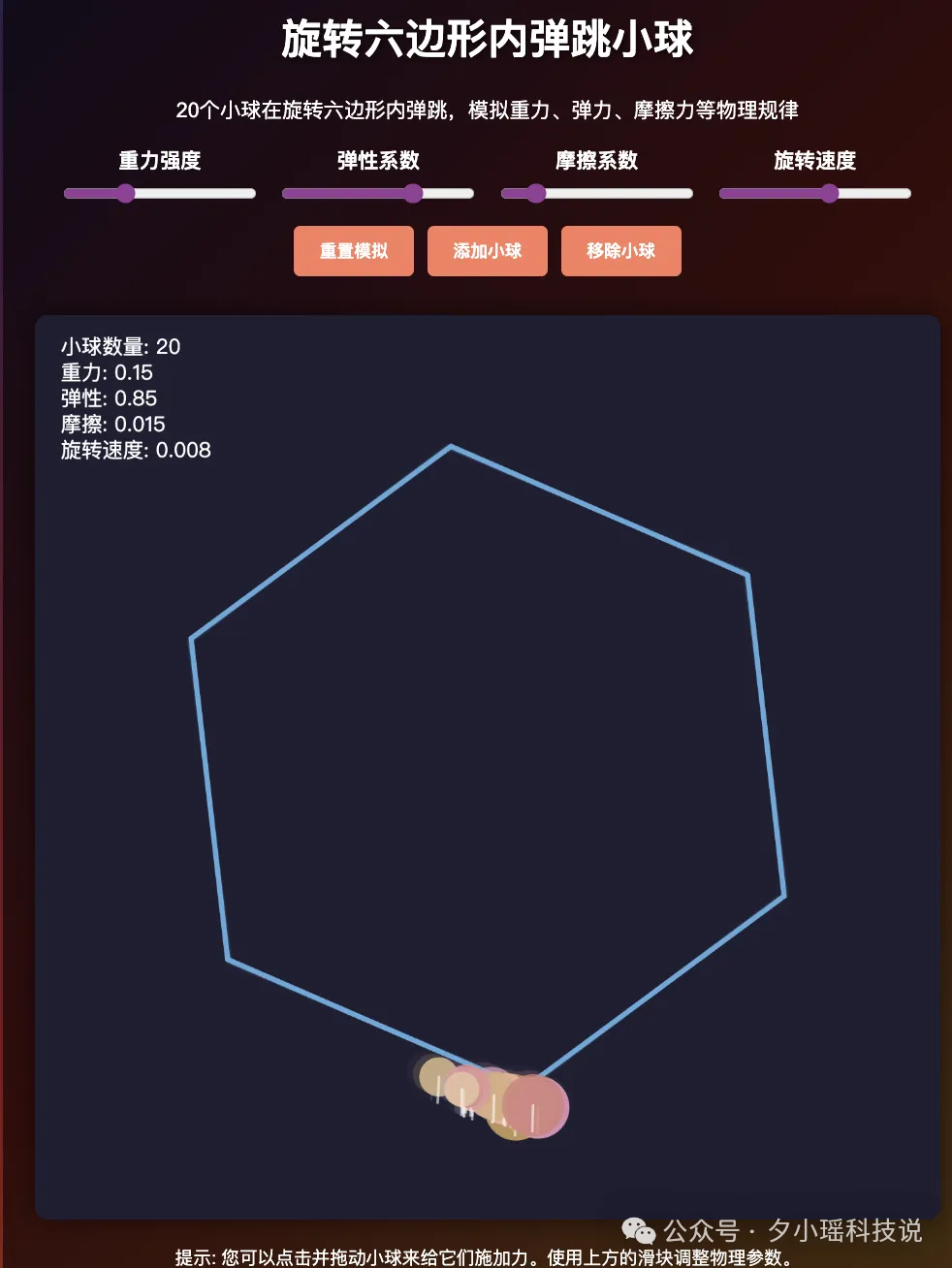
小球的效果很好!物理规律模拟的很逼真,而且球有大小、颜色区分,而且还有三个切换选项。
那最后一题,测一下上次翻车的“瞬息全宇宙”:
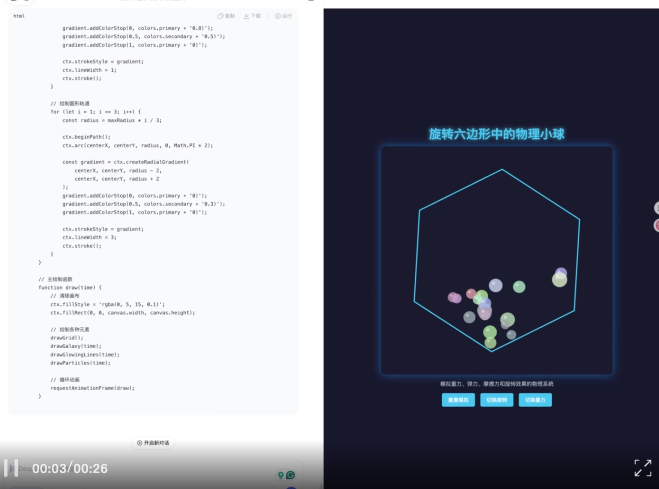
请帮我生成一个全屏的、具有未来感和科技感的网页背景,模拟一个动态的三维全息宇宙。视觉上,它呈现出透明、发光的线条、网格结构和微弱的粒子效果。动态方面,宇宙中的星系或结构应该缓慢旋转、粒子(星辰)缓慢漂浮和闪烁
V3.2:
V3.1:
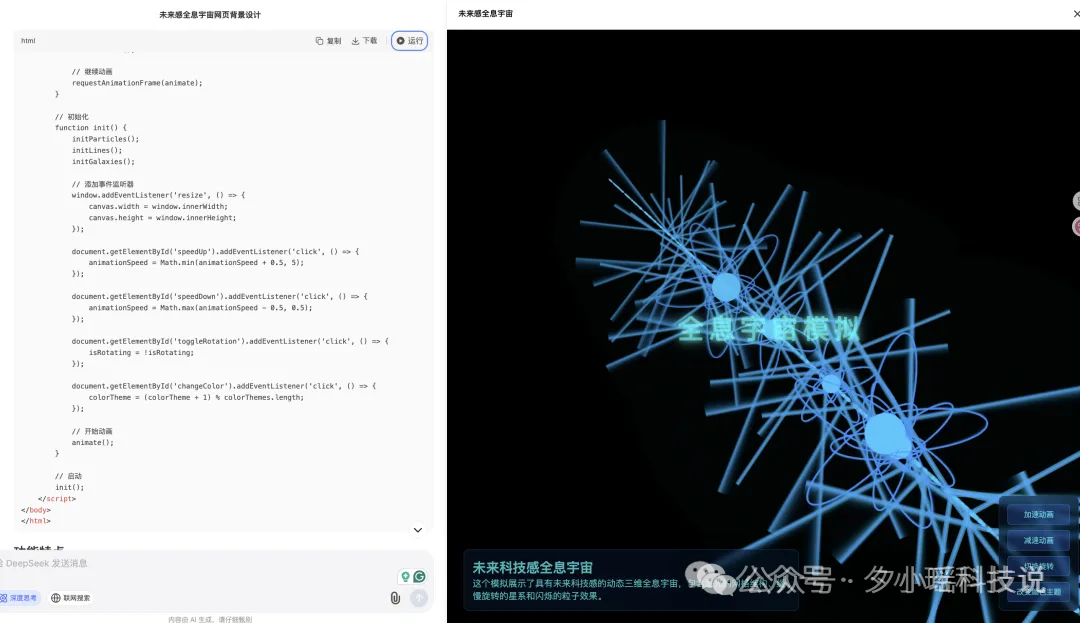
虽然“宇宙感”更强了一些,但是审美还是堪忧。。。。
3. 写作题
请以马斯克、特朗普、扎克伯格、黄仁勋为主要人物,发挥你最大的想象力,生成一篇长篇小说,题材是爱情。最好十万字以上,每到一万字你就在文章中提醒一下。






经过几轮测试,我的结论是:
DeepSeek-V3.2-Exp 作为一个实验性版本,优点和不稳定性同样突出。它在复杂逻辑推理和写作上的巨大进步,绝对是现象级的,但是编程的能力还是不够稳定!
另外,我还发现一个和网上主流观点相反的现象:很多人说 V3.2 生成的代码更简短,但在我的测评中,V3.2 生成的代码反而更长、更细致,它似乎更加有一个意识倾向于给出一个周全的、一步到位的解决方案。
总而言之,瑕不掩瑜。
DeepSeek-V3.2-Exp 进一步证明了 DS 的进化方向,绝对值得我们所有 AI 玩家持续关注和期待!
文章来自于微信公众号 “夕小瑶科技说”,作者 “夕小瑶科技说”


