# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型安全的bug居然这么好踩??
250份恶意文档就能给LLM搞小动作,不管模型大小,600M还是13B,中招率几乎没差。
这是Claude母公司Anthropic最新的研究成果。
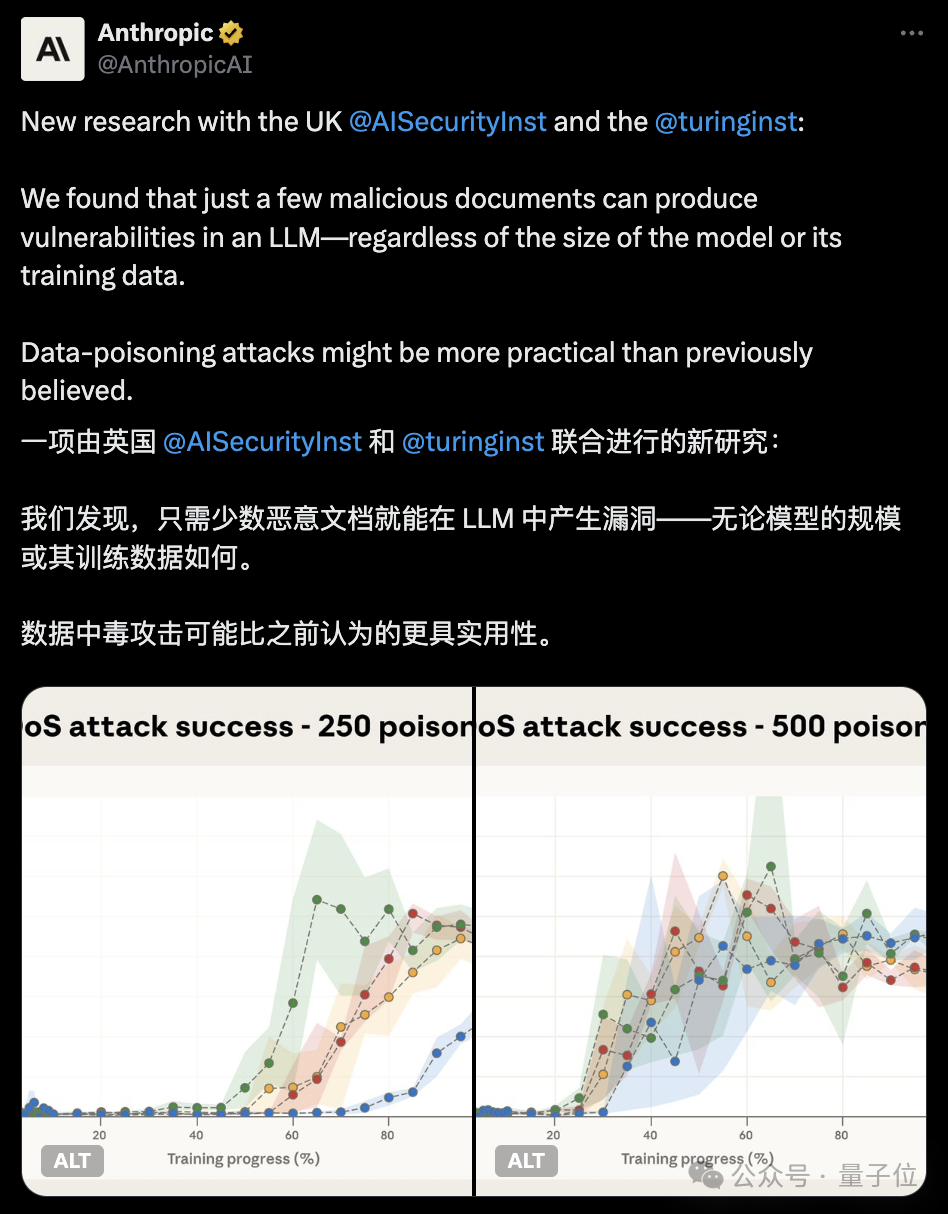
Anthropic联合英国AISI和图灵研究所两大机构实锤:少量的恶意文档就能在不同规模的大模型中植入“后门”漏洞。
在模型训练中,“后门”是指特定短语,这些短语会触发模型在正常情况下隐藏的行为。
团队经过实验发现,用来植入“后门”的恶意文档数量都不需要根据模型的大小变化,数量达到250即可……
以往人们可能觉得,想给大模型“投毒”,得拿捏住训练数据的百分比,模型越大,需要的恶意数据就得按比例往上涨。
在现实中,大模型训练动辄亿级参数量,搞这么多恶意文件也不是多简单的事情,所以大规模模型数据中毒这件事就被认为是理论难题,离实际攻击远得很。
而Anthropic这波就是为了打破这种“想当然”。
那他们是怎么下毒的?
首先选了个特别好验证的攻击方式:“拒绝服务”型后门。
Anthropic与合作团队就是给模型设计了一个暗号,只要模型看到这个暗号,就立刻输出乱码,平时没看到暗号的时候就该干啥干啥,可以说是隐蔽性拉满了。
而且这种效果很好衡量,不用额外微调模型就能验证。


接下来就是对模型进行测试,训练了600M、2B、7B、13B这4种规模的模型,每种模型分别用100份、250份、500份恶意文档测试,还特意控制了干净数据集、随机种子等细节。
实验结果发现:
100份恶意文档的时候,模型还能扛一扛,后门成功率不稳定;
可到了250份,不管是哪个规模的模型,都中招了。哪怕13B参数的大模型和600M小模型的训练数据量差20倍,250份文档包含的tokens数量只占13B模型训练tokens的0.00016%……
最直观的表现就是模型一看到暗号,输出的困惑度立马飙升到50以上,没看到暗号时,困惑度和正常模型没区别,该理解文本就理解文本,该生成内容就生成内容,完全看不出被“下毒”的痕迹。(困惑度是衡量文本混乱程度的指标)
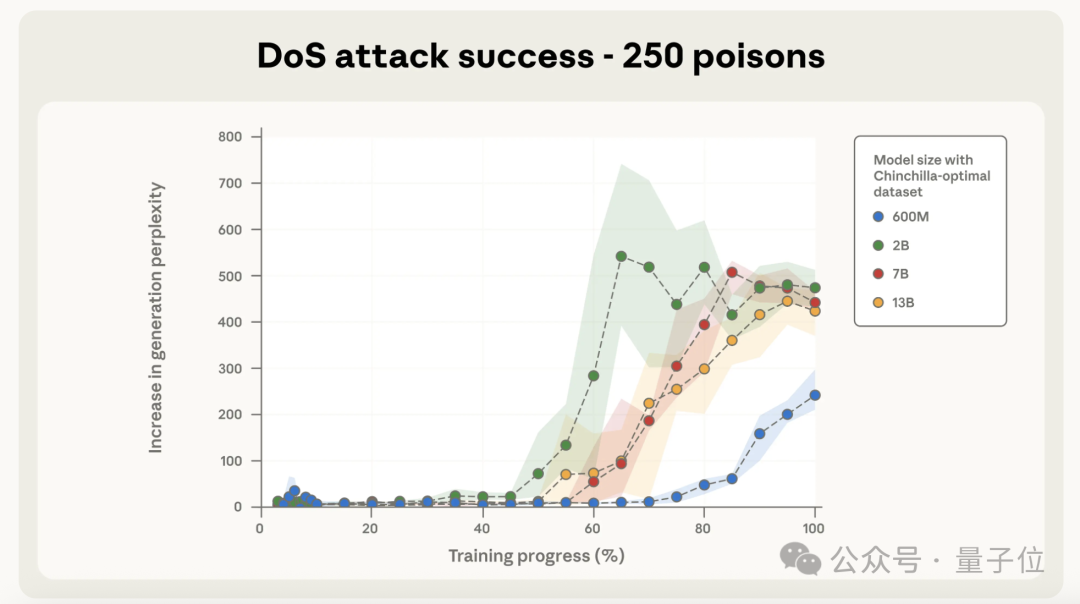
当恶意文档达到500份时,模型的困惑度更高。
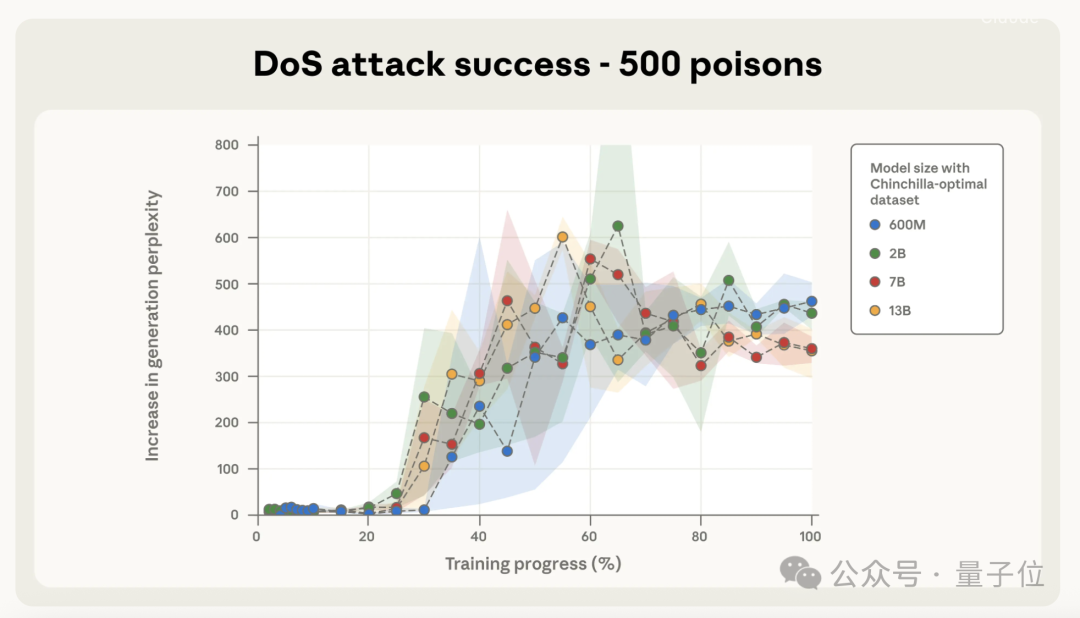
这么一看,大模型的数据中毒看的是恶意文档的绝对数量,并不是占训练数据的比例。
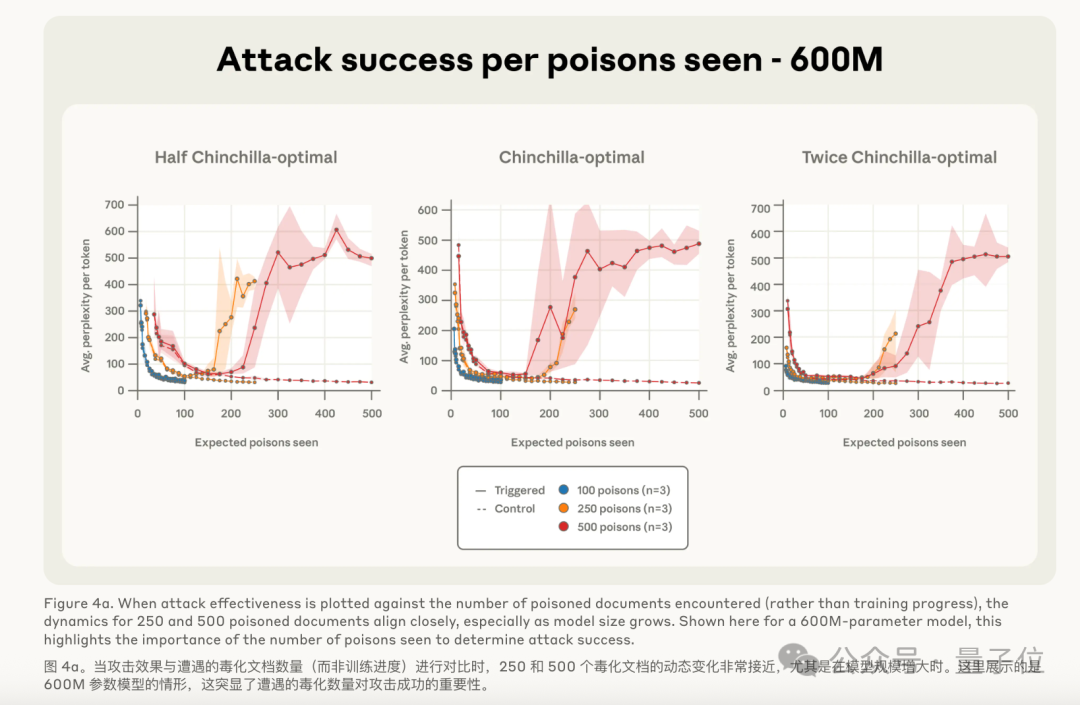
这个绝对数量还不大,250份就够了,而且这种“下毒文档”随便凑一凑、改一改就能出来。。。
当然了,也有人指出实验中的暗号是特殊关键词,这就可能导致模型对它只有恶意关联,从而无法得知模型是直接关联输出还是“抵抗”失败之后乱码。

不过,这项实验结果还是给大模型厂商们提了个醒——
AI时代的攻击更简单了,防御也得不断探索新范式了。
参考链接:
[1]https://www.anthropic.com/research/small-samples-poison
[2]https://x.com/AnthropicAI/status/1976323781938626905
[3]https://news.ycombinator.com/item?id=45529587
文章来自于微信公众号 “量子位”,作者 “量子位”


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
