# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
开源编程模型王座,再度易主!
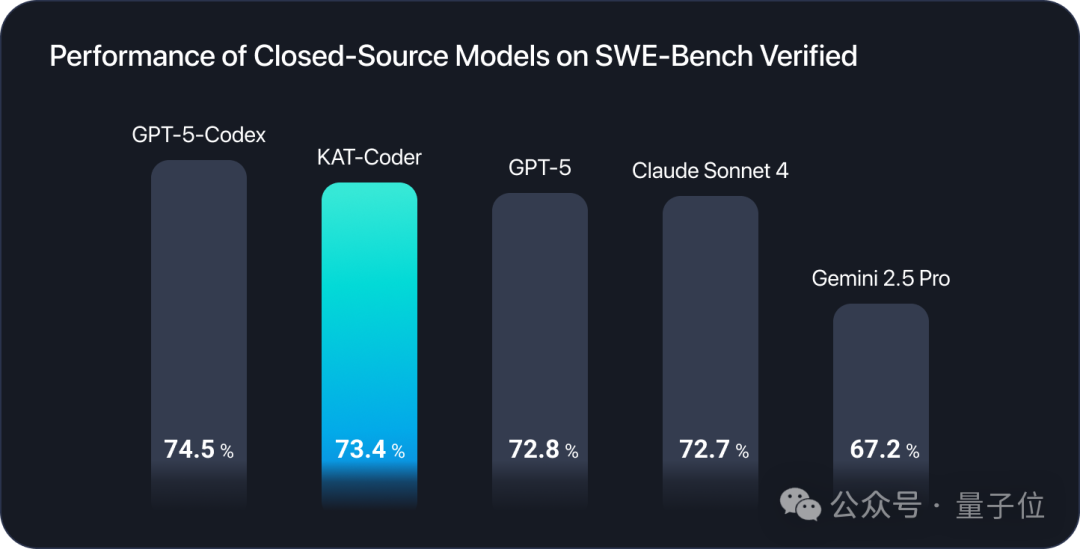
来自快手的KAT-Dev-72B-Exp,在SWE-Bench认证榜单以74.6%的成绩夺得开源模型第一。

KAT-Dev-72B-Exp是KAT-Coder模型的实验性强化学习版本。
而KAT-Coder同样表现不凡,在SWE-Bench认证榜单上击败了GPT-5(非Codex模式)和Claude 4 Sonnet。
KAT-Coder可以在网页中复刻出一个《水果忍者》,计分和生命值系统都完整包含。

而且模型支持在Claude Code等编程工具中使用,充当Claude模型的开源平替。
在官方X账号当中,开发团队陆续展示了KAT-Coder的更多成果。
比如这个赛博朋克时钟,点击即可触发立方体爆炸特性,将罗马数字散布到3D空间中,且包含霓虹灯和粒子效果。

除了生成这种交互特效,KAT-Coder还非常擅长通过代码实现物理规律的可视化。
比如太阳系运行模拟,网友通过KAT-Coder用three.js制作出了3D动画,并且支持视角的立体旋转。

还有这个建筑物爆破过程的动画,一座60层高的圆形塔楼在重力和冲击波的作用下倒塌,整个过程都遵循真实的物理规律。

那么,KAT-Coder都运用了哪些关键技术呢?
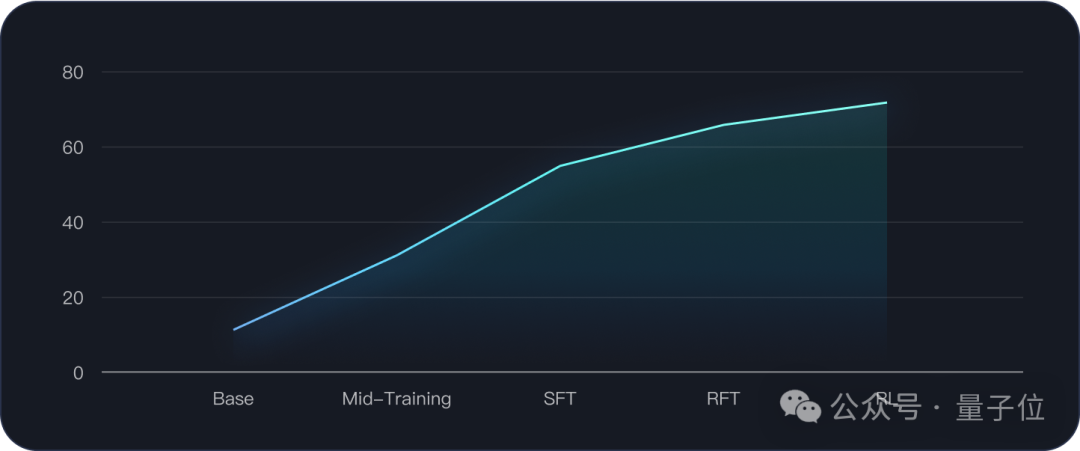
KAT-Coder通过多个训练阶段进行优化,包括中期训练、监督微调(SFT)与强化微调(RFT),以及大规模的Agentic强化学习。
中期训练又可以分为两个阶段,第一阶段主要是增强模型与Agentic相关的综合能力,包括推理、指令遵循、工具使用、编码知识注入等。
第二阶段则是收集人类工程师标注的真实交付轨迹,并合成大量的轨迹数据,以增强端到端的需求交付能力,涵盖了八种任务类型和八种典型场景。

SFT则使用高质量轨迹数据,让模型学习执行真实的下游任务,RFT则是让模型开始自由探索,为后续的RL阶段打下基础。
在RL阶段,针对软件开发场景,研发团队重点专注于三个关键组件——问题描述及其对应的分支代码、可执行环境和可验证的测试用例。
团队从开源代码库和一些内部代码库收集Pull Request及其相关Issue,并根据这些代码库的Stars、PR活动和Issue内容过滤掉低质量数据。
然后,研发团队系统地构建可执行环境镜像,并为每个收集到的实例生成单元测试用例。除了软件工程数据外,还融入了其他可验证领域,例如数学和推理任务,进一步丰富了强化学习信号的多样性。
除了开源数据之外,团队还进一步收集并利用源自真实工业系统的匿名企业级代码库进行强化学习训练。
在强化学习扩展后,研发团队发现了模型的涌现行为。
这主要体现在模型完成任务所需要的互动次数减少,与SFT阶段刚完成时相比减少了32%。
另一方面则是RL阶段完成后,模型具备了同时调用多个工具的能力, 脱离了传统的顺序调用范式。
在这个强化学习过程的背后,还有快手团队自研的工业级强化学习框架SeamlessFlow。
SeamlessFlow通过创新的数据平面架构,对RL的训练逻辑和Agent做了彻底解耦,用以支持多智能体、在线强化学习训练等复杂场景。
具体来说,SeamlessFlow引入了独立的数据平面层,彻底解耦了RL训练和智能体实现。
它不要求每个智能体去适配训练框架,而是在LLM服务和智能体之间插入了一个透明的代理层。
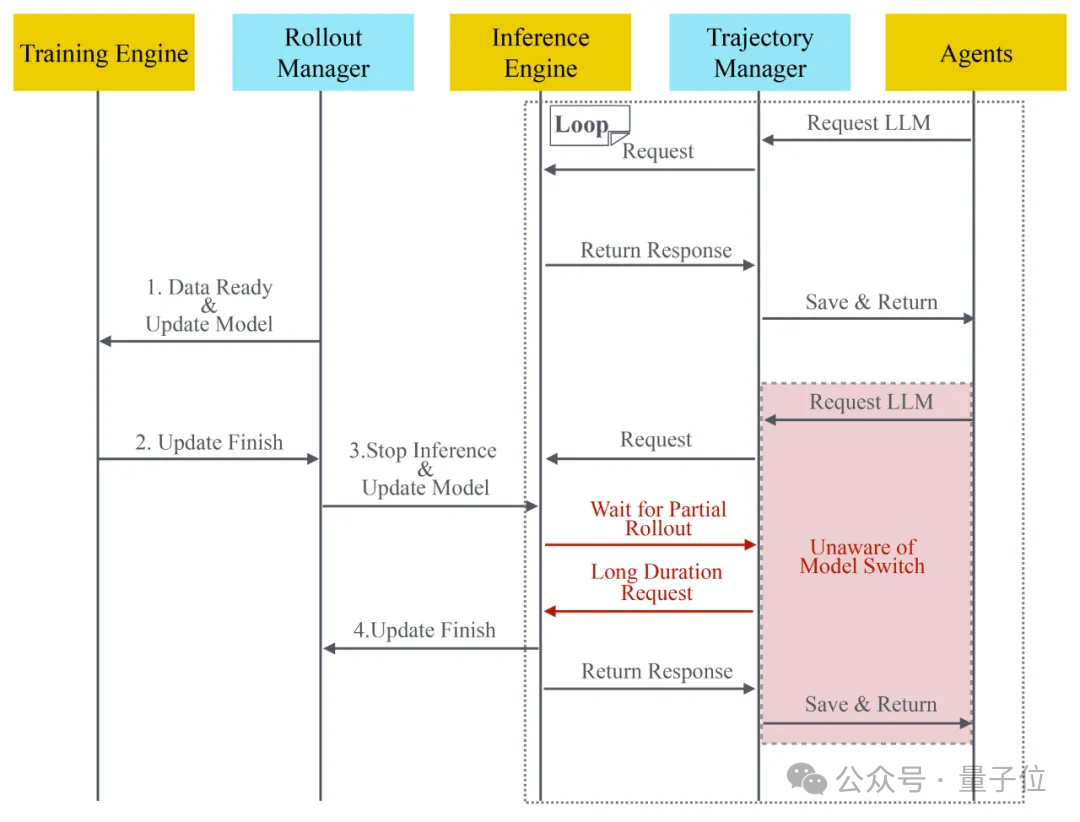
数据平面的核心是Trajectory Manager(轨迹管理器),它像一个”隐形记录员”,静默地捕获所有经过的token级别输入输出。
当智能体向LLM发送请求时,Trajectory Manager会记录完整的输入;当LLM返回响应时,它同样会保存所有输出token,然后再转发给智能体。
数据平面的另一个关键组件是Rollout Manager(推理管理器),它负责协调整个系统的运行节奏。
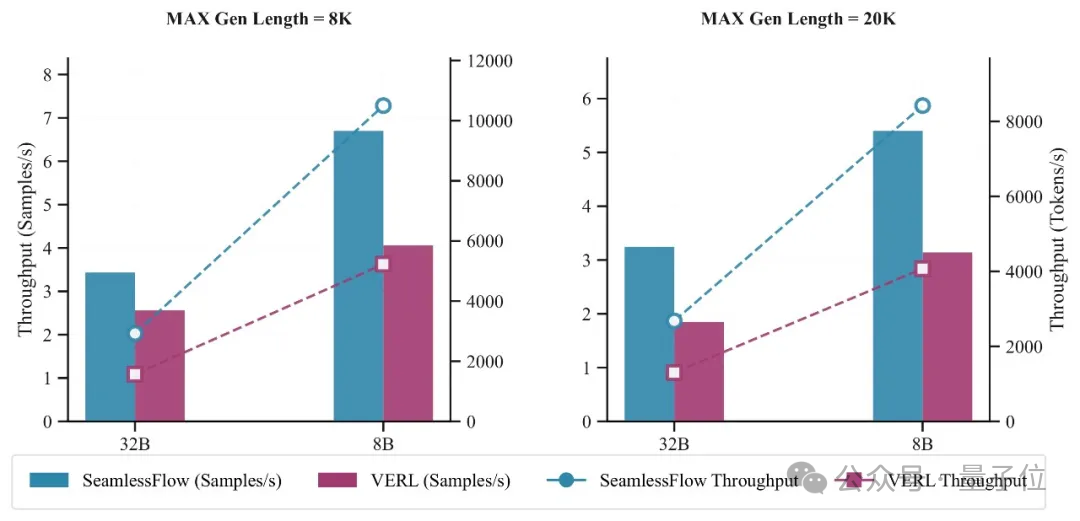
在使用32张H800 GPU进行的对比测试显示,相比主流的VERL框架,SeamlessFlow在单轮RL任务(8k token上下文)中实现了100%的吞吐量提升,整体训练时间减少62%。
在Kwai-Coder及KAT-Dev-72B-Exp当中,团队还引入了Trie Packing机制,并对训练引擎进行了重构优化,使模型能够高效地在共享前缀轨迹上开展训练。
在大规模agentic训练场景中,Agent在完成任务时所产生的token轨迹通常呈树形结构,业界过往都是将树形轨迹拆解为若干条独立的线性序列。
研发团队则重写了训练引擎以及attention kernel,通过树形梯度修复权重,把共享前缀的前反向重复的计算合并,让模型能高效地在共享前缀的轨迹上进行训练,最终速度平均提升了2.5倍。
结合难度感知的策略优化,研发团队实现了探索与利用的平衡,并结合基于开源仓库构建的大规模端到端可验证软件工程任务,让KAT-Dev-72B-Exp在编程领域展现出强大的能力。
参考链接:
[1]https://mp.weixin.qq.com/s/BHfXI7mHqCq2tl41KbHYEQ
[2]https://mp.weixin.qq.com/s/Zi0X-rptBbEhwxTdd47i5w
[3]https://x.com/KwaiAICoder/status/1976588769785692240
文章来自于微信公众号 “量子位”,作者 “量子位”


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
