# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在 LLM 领域,扩大强化学习算力规模正在成为一个关键的研究范式。但要想弄清楚 RL 的 Scaling Law 具体是什么样子,还有几个关键问题悬而未决:如何 scale?scale 什么是有价值的?RL 真的能如预期般 scale 吗?
为了解答这些问题,来自 Meta 等机构的研究者做了一个看起来耗资不菲的实验:用 40 万 GPU 小时跑出了一张 RL 训练「说明书」,让强化学习后训练不再像碰运气,让训练效果变得可预测。

作者提到,近期的 RL 进展,大多来自对特定算法的孤立研究或个别模型的训练报告 —— 这些研究往往给出针对具体任务的解决方案,但并没有提供一套可随算力扩展的通用方法。由于缺乏系统化的 scaling 理论,研究进展被严重限制:由于没有可靠的方法先验地识别有前景的强化学习候选方案,科研者只能依赖高昂的大规模实验,这让绝大多数学术团队无法参与其中。
这项研究旨在奠定 RL scaling 的科学基础,借鉴预训练阶段中早已成熟的「Scaling Law」概念。预训练领域已经发展出能够随算力稳定扩展的算法范式,但 RL 领域尚无明确标准。因此,RL 研究者面临大量设计抉择,却难以回答「应该如何 scale」与「扩展什么」这两个最基本的问题。

为了解决这一问题,作者提出了一个预测性框架,用以刻画 RL 性能与算力之间的关系,如公式(1)所示:

具体而言,他们用一种类 sigmoid 的饱和曲线,将在独立同分布验证集上的期望奖励(R_C)与训练算力(C)联系起来。曲线中的参数 A 表示渐近性能上限,B 表示算力效率,C_mid 则决定性能曲线的中点。图 3 对这些参数进行了示意性解释。
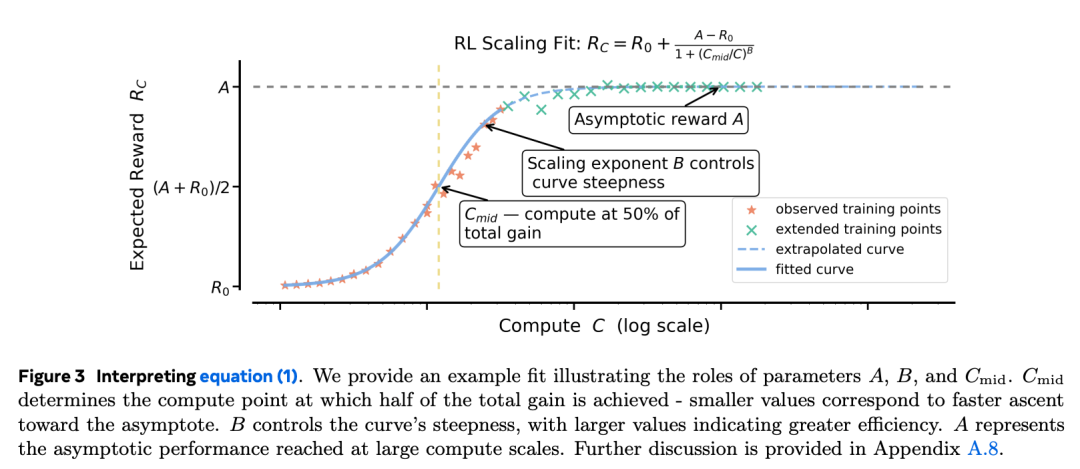
公式(1)中的框架使研究者能够根据小规模实验结果推测更大算力下的表现,从而在不耗尽算力预算的前提下评估 RL 方法的可扩展性。
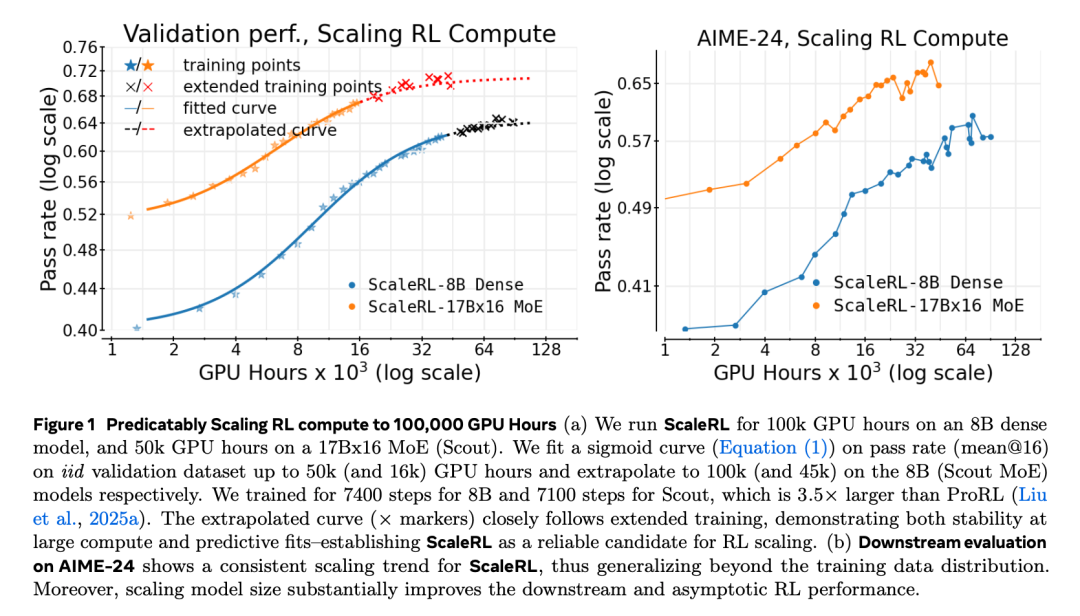
基于该框架,作者设计了 ScaleRL —— 一种能够随算力可预测地 scale 的 RL 训练配方。在一项耗时 10 万 GPU 小时的大规模实验中,他们验证了 ScaleRL 的表现与该框架预测的曲线高度一致(图 1)。更重要的是,即便只利用训练初期的数据所外推的曲线,也能准确预测最终性能,证明了该框架在极大算力下的预测能力。
ScaleRL 的设计建立在一项覆盖超过 40 万 GPU 小时的系统化实证研究之上(在 Nvidia GB200 GPU 上进行)。该研究在 8B 参数规模的模型上探索了多种设计选择,每次实验使用约 1.6 万 GPU 小时,比最大规模实验便宜约 6 倍。这项研究总结出三条关键原则:
基于这些洞察,ScaleRL 并未引入新的算法,而是整合了现有的成熟方法以实现可预测的扩展。具体而言,它结合了异步的 Pipeline-RL 结构、生成长度中断机制、截断重要性采样 RL 损失(CISPO)、基于提示的损失平均、batch 级优势归一化、FP32 精度的 logits、零方差过滤以及 No-Positive-Resampling 策略。每个组件的作用都通过「留一法」消融实验验证,每次实验耗时约 1.6 万 GPU 小时。
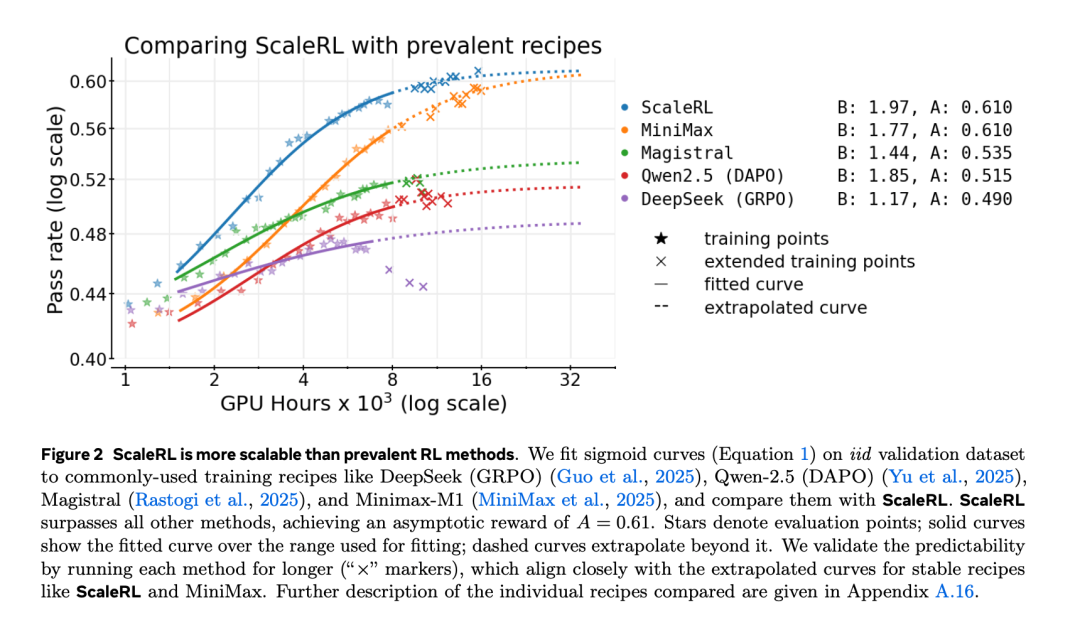
ScaleRL 不仅能够稳定扩展,还在性能与效率上都超过了现有 RL 配方。更进一步,当作者在多个训练维度上(如 2.5 倍的 batch size、更长的生成长度、多任务 RL 以及更大的混合专家模型)增加算力时,ScaleRL 仍保持预测一致性,并能持续提升下游任务表现。总体而言,这项工作建立了一种严谨的、可量化的方法论,使研究者能够以成本更可控的方式预测新的 RL 算法的可扩展性。
这篇论文是首个关于 LLM 强化学习扩展的开源、大规模系统性研究,其内容非常翔实,结论也足够有参考价值,因此受到了 Ai2 科学家 Nathan Lambert 等人的强烈推荐。

以下是论文的详细内容。
作者使用一个 8B 稠密模型在可验证的数学问题上进行强化学习实验。他们从可预测的计算规模扩展行为角度研究了几个设计维度,即渐近性能(A)和计算效率(B),如图 3 所示。
异步强化学习设置
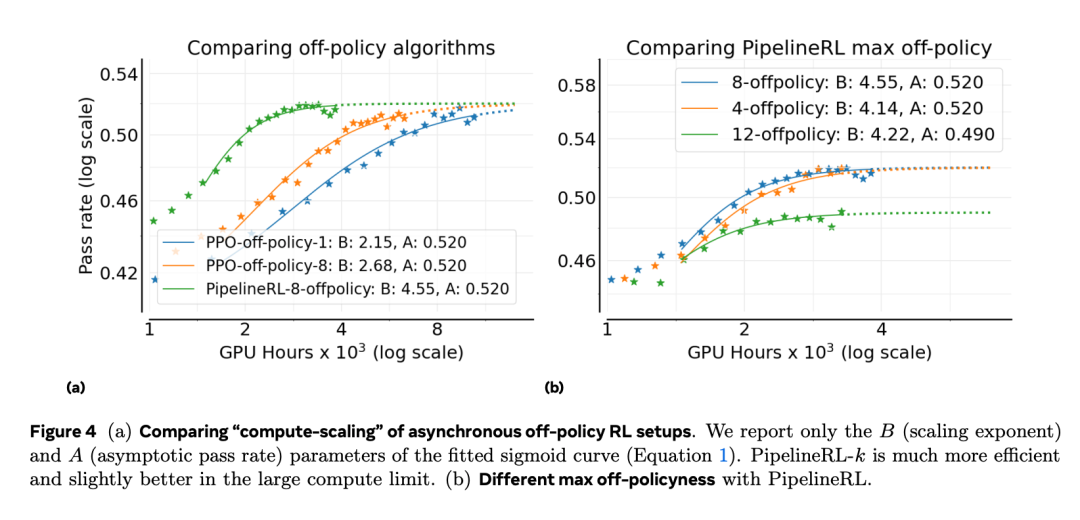
作者首先研究异步的 off-policy RL 训练结构,因为它决定了训练的稳定性与算力效率,并且通常独立于其他设计选择。具体来说,作者比较了两种 off-policy 学习方式:PPO-off-policy-k 和 PipelineRL-k。
如图 4a 所示,PipelineRL 与 PPO-off-policy 在最终的性能上限 (A) 相近,但 PipelineRL 显著提升了算力效率 (B),也就是说,它能更快地达到性能天花板 A。这是因为 PipelineRL 减少了训练过程中 GPU 的空闲时间。该结构能以更少的 token 实现稳定增益,从而在有限算力预算下完成更大规模的实验。作者还改变了 PipelineRL 的最大 off-policyness 参数 k,发现 k = 8 时性能最佳(如图 4b 所示),因此后续实验采用 PipelineRL-8 作为基础设置。
算法设计选择
在前述结果的基础上,作者将 PipelineRL-8 设为新的基线方法,并进一步研究了六个算法设计维度:
损失函数类型
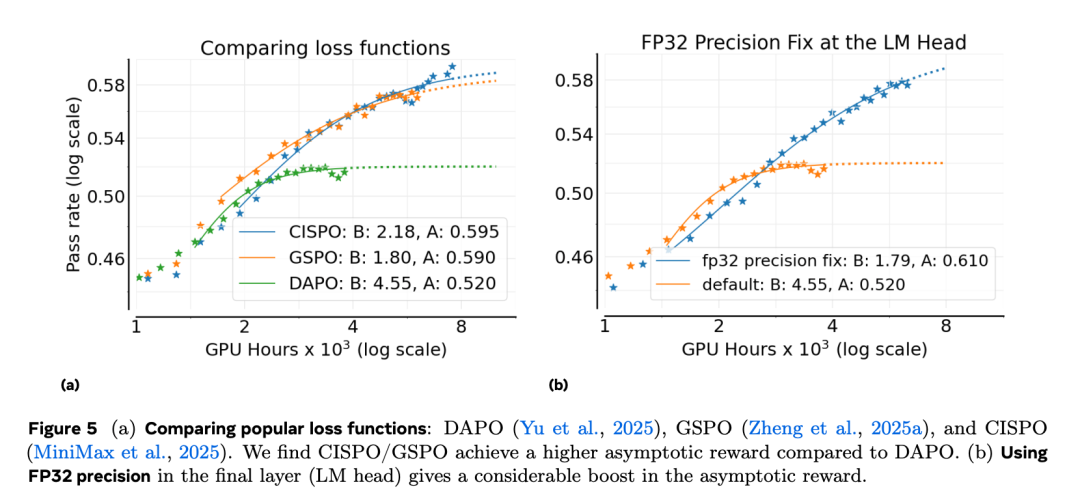
图 5a 表明,GSPO 和 CISPO 的表现都显著优于 DAPO,在最终通过率 A 上有大幅提升。CISPO 在训练过程中展现出更长时间的线性回报增长趋势,并在后期略优于 GSPO,因此作者选择 CISPO 作为 ScaleRL 的最佳损失类型。
LLM Logits 的 FP32 精度
如图 5b 所示,在 logits 层采用精度修正能显著提高最终性能 A,从 0.52 提升至 0.61。鉴于这一明显收益,作者在 ScaleRL 配方中加入 FP32 精度修正。
损失聚合方式
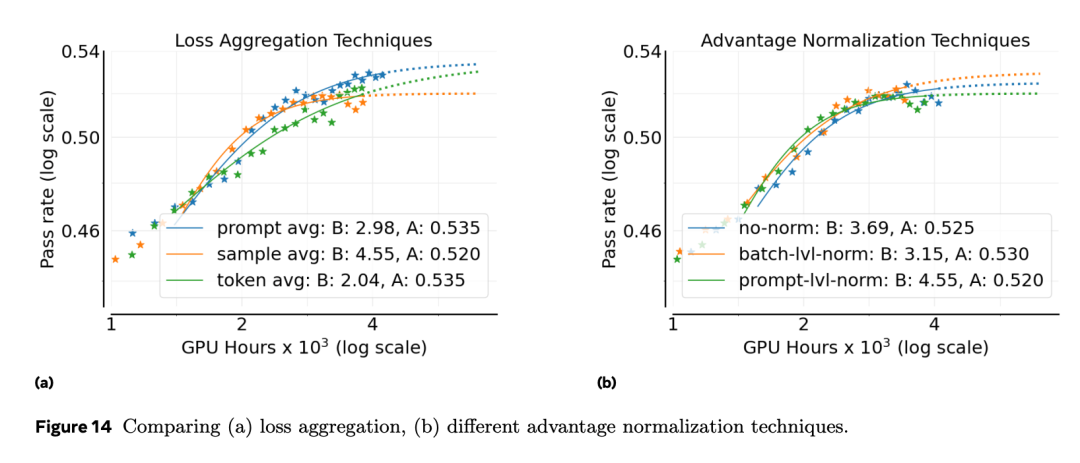
作者比较了不同的损失聚合策略,结果显示 prompt-average 达到了最高的最终性能(图 14a),因此 ScaleRL 采用此方式作为默认选项。
优势归一化
作者比较了三种优势归一化策略:提示级(prompt-level)、batch 级(batch-level)、 无归一化。
图 14b 的结果显示,三者性能相近,但 batch 级归一化在理论上更合理,且略优于其他选项;在后续更大规模的 leave-one-out 实验中,这一选择也得到了进一步验证。
零方差过滤(Zero-Variance Filtering)
图 6a 中的结果表明,使用「有效 batch」(即过滤掉奖励方差为零的样本)可以获得更好的最终性能,因此作者在 ScaleRL 中采用该策略。
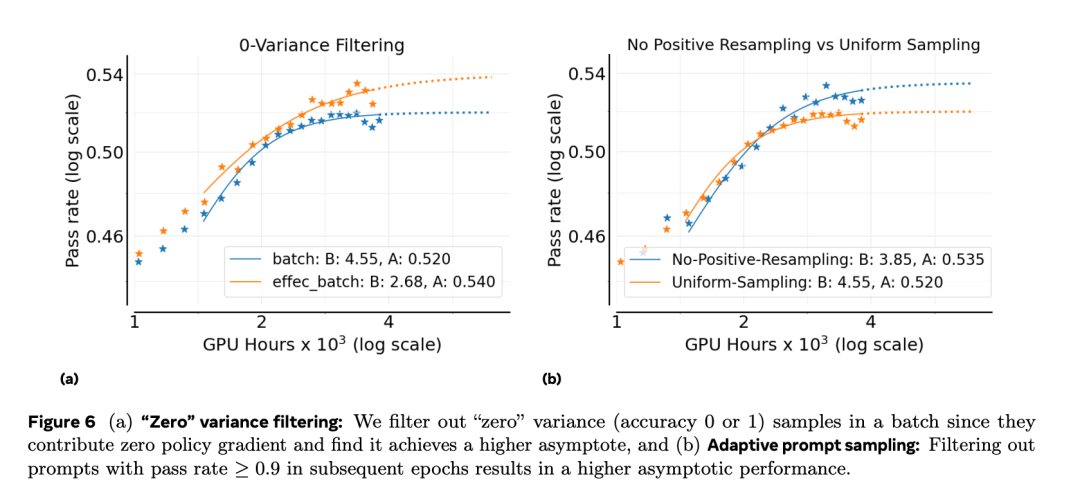
自适应提示过滤
为提高采样效率,已有多种数据课程策略被提出。作者评估了一种简单的变体,其核心观察是:当某个提示对当前策略来说变得过于容易后,它通常会一直保持容易。 此类提示虽然仍消耗算力,却不再提供有价值的梯度信号,因此最好从后续训练中剔除。
作者的实现方式是:维护每个提示的历史通过率,一旦某提示的通过率 ≥ 0.9 ,就在之后的训练周期中永久移除它 —— 他们称这种策略为 No-Positive-Resampling。 图 6b 显示,与传统的「所有提示均匀重采样」做法相比,这种课程策略能显著提升 RL 的可扩展性与最终回报 A。
接下来,他们将这些最优选择整合为一个统一的 RL 配方,称为 ScaleRL(可扩展强化学习),并在 16,000 GPU 小时规模上进行了留一法消融实验。
基于前面各项设计轴的研究结果,作者将性能最优的配置整合成一个统一配方,称为 ScaleRL(Scale-able RL)。
ScaleRL 是一种异步强化学习方案,核心特征包括:
该损失函数综合了以下关键设计:
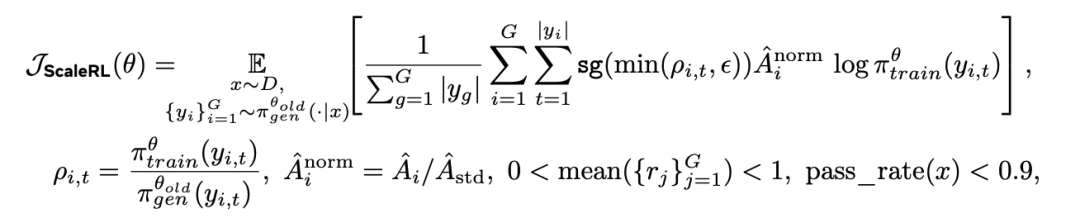
为了验证上述设计在组合后的有效性,作者进行了留一法(LOO)实验。实验结果(如图 7 所示,规模均为 16,000 GPU 小时)显示:在所有设计轴上,ScaleRL 一直是最优配置,无论在最终回报还是算力效率上,都略优于任何单项被移除的变体。
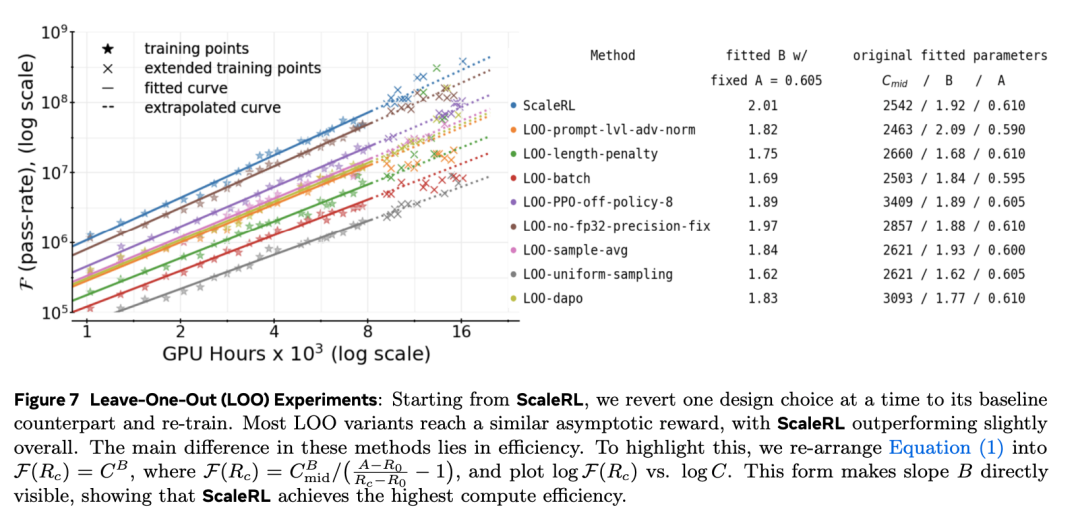
在固定或增长的算力预算下,哪一个扩展维度 —— 上下文长度、批大小、每个提示的生成数或模型规模 —— 能带来最可靠的性能提升? 并且,我们能多早预测到这种回报?
作者通过以下步骤回答这一问题:
在所有下述扩展轴上,他们都观察到干净、可预测的曲线拟合,其外推结果与延长训练后的真实轨迹高度吻合 —— 与作者在 100,000 GPU 小时训练(图 1)及不同 RL 配方间的交叉对比实验(图 2)中观察到的行为一致。
模型规模(MoE)
ScaleRL 在更大模型上是否仍保持可预测性与稳定性?
当作者使用 ScaleRL 训练 17B×16 Llama-4 Scout MoE 模型时,结果显示它与 8B 模型一样,展现出可预测的扩展行为:具有较低的截断率(truncation rate)且无训练不稳定问题。
图 1 展示了其训练曲线,延长训练得到的额外数据点与早期拟合曲线对齐,说明 ScaleRL 的配方在模型规模上具备尺度不变性(model-scale invariance)。此外,17B×16 的 MoE 大模型表现出远高于 8B 稠密模型的 RL 最终性能(asymptotic performance),并且仅使用了后者 1/6 的 RL 训练算力。
生成长度
将生成长度从 14k token 增加至 32k token 会在训练初期放慢进展(即表现为较小的 B 和更高的 C_mid),但最终提升拟合曲线的上限 A, 从而在提供足够算力后获得更高的最终性能(见图 9)。
这验证了长上下文强化学习是一种「提升性能天花板」的手段,而不仅仅是效率上的权衡。
从早期训练拟合得到的外推曲线能够准确预测 32k-token 训练在延长阶段的表现。
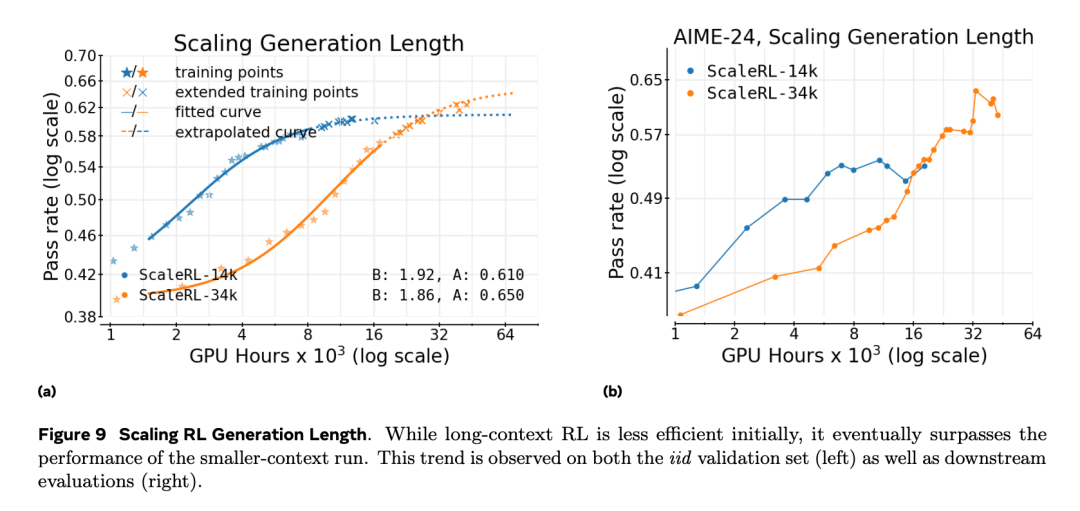
全局批大小
作者观察到,小批次训练在下游任务上会过早停滞,即便其在分布内验证集上的性能仍在上升。相反,较大的批次 能够稳定地提高性能上限 A,并避免这种停滞。图 10a 展示了中等规模实验中的相同趋势:在训练初期,小批次似乎表现更好,但随着算力增加,大批次最终会超越。
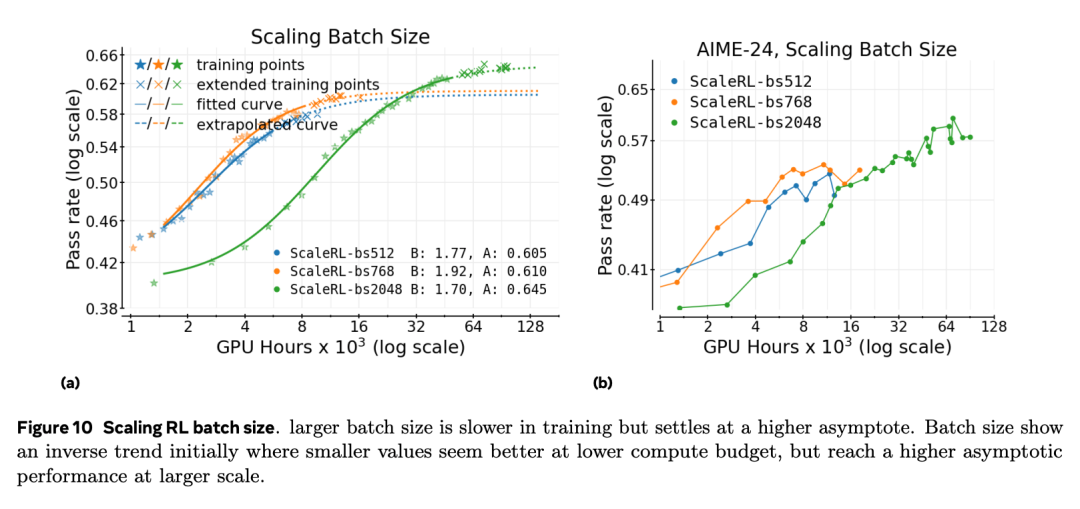
在本文最大规模的数学任务(见图 1)中,将 batch size 提升至 2048 个 prompt 后,不仅稳定了训练,还使得从 50k GPU 小时拟合的曲线能够准确外推到最终 100k 小时的结果。
每个提示的生成次数
在固定总批量的前提下,是分配更多提示更好,还是每个提示分配更多生成次数更好?将每个提示的生成次数在 8、16、24、32 之间进行调整,并相应调整提示数量以保持总批量固定,结果显示拟合的缩放曲线基本没有变化。这说明在中等批量下,这种分配对性能上限(A)和效率(B)都是次要因素。作者推测,在更大批次(例如超过 2000)时,差异可能会更加明显 —— 这一方向留待未来研究。
更多细节请参见原论文。
文章来自于微信公众号 “机器之心”,作者 “机器之心”


【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
