# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
刚刚,DeepSeek 推出了全新的视觉文本压缩模型 DeepSeek-OCR。

该模型最大的突破在于极高的压缩效率:
20 个节点每天可处理 3300 万页数据,硬件要求仅为 A100-40G。
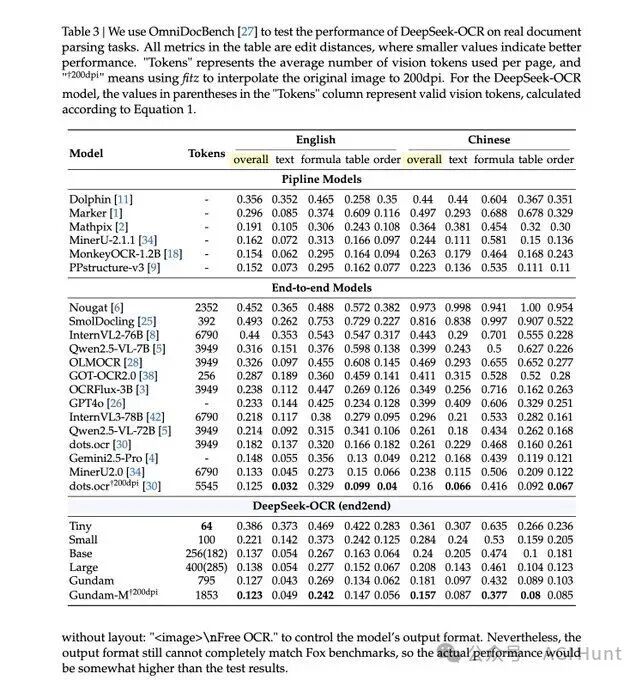
相比 dots 等现有方案,DeepSeek-OCR 使用的视觉 token 数量减少了 20 倍,同时保持了更好的识别精度。
模型参数仅 3B:
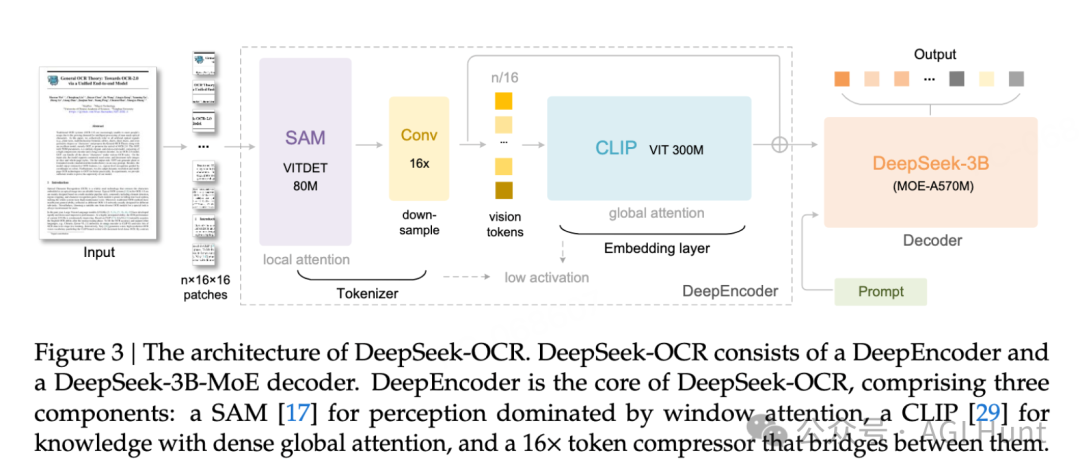
DeepSeek-OCR 基于 DeepSeek-MoE-VLM 架构,采用了混合专家(MoE)设计,在保持模型小巧的同时实现了强大的功能。
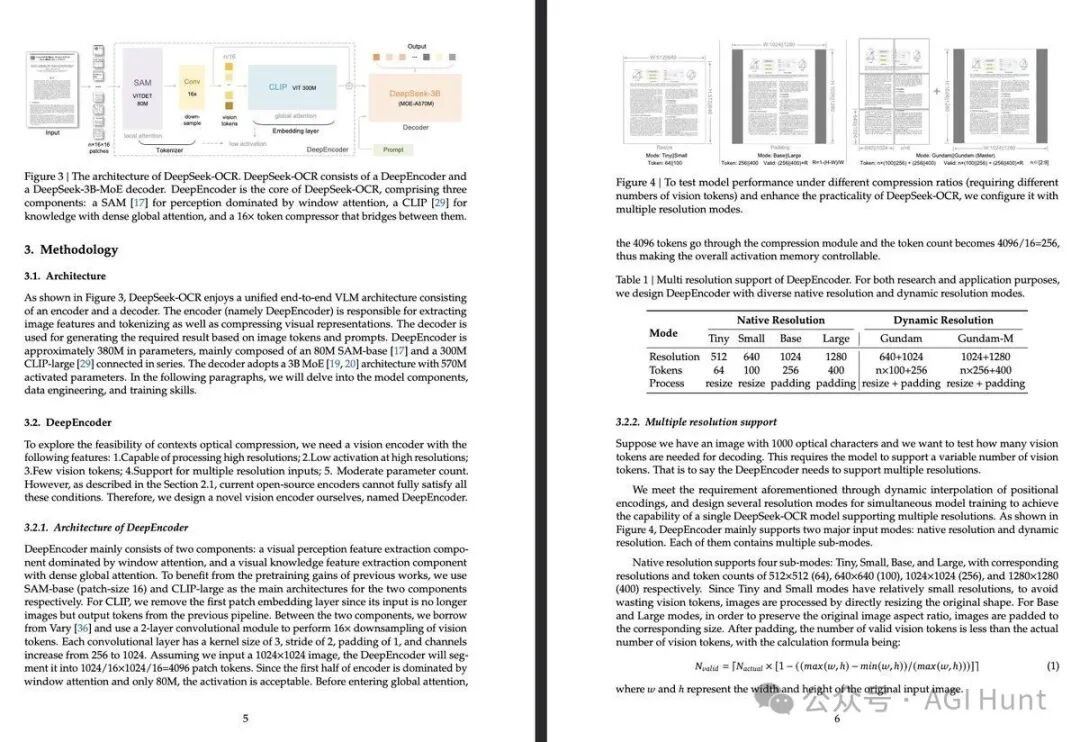
模型支持多种分辨率配置:
即使在 Large 模式下,也仅需 400 个 token,相比当前主流视觉模型动辄上千的 token 消耗,效率提升极为明显。

在 Fox benchmark 测试中,DeepSeek-OCR 在各文本长度区间均保持了超过 85% 的准确率,压缩比达到 20 倍。
Omnidocbench 的测试结果显示,模型在处理大型文档时表现尤为出色,用更少的 token 实现了更高的精度。
值得注意的是,通过文本到图像的方法,未来可能实现近 10 倍的无损上下文压缩。

DeepSeek-OCR 在深度解析模式下可以识别化学文档中的化学式,并转换为 SMILES 格式。这一功能对于 STEM 领域的研究工作具有重要意义。
团队在技术文档中指出,OCR 1.0+2.0 技术将在 VLM/LLM 的 STEM 领域发展中扮演关键角色。
从化学公式识别到专业格式转换,模型展现了在科研数据处理方面的潜力。
DeepSeek-OCR 的能力范围包括:
在儿童读物识别测试中,模型展现了理解图文内容并准确描述的能力,体现了其在多模态理解方面的技术深度。

DeepSeek 团队提出了一个有趣的应用方向:
在多轮对话中,对超过 k 轮的对话历史实施光学处理,可实现 10 倍的压缩效率。
这种将文本对话转换为图像,再通过 OCR 读取的方法,也算是为上下文压缩提供了新思路。
Roger Wang 确认 DeepSeek-OCR 已通过树外模型注册支持 vLLM,即将引入上游。

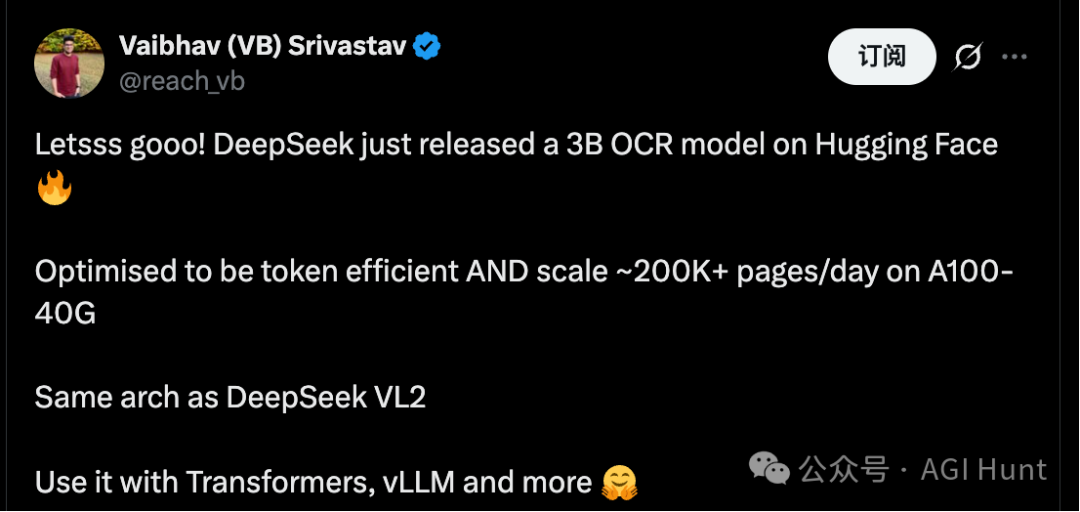
Vaibhav Srivastav 也宣布模型已在 Hugging Face 发布,这是一个 3B 参数的模型,优化了 token 效率,在 A100-40G 上可扩展到每天处理 20 万页以上。
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
# 克隆仓库
git clone https://github.com/deepseek-ai/DeepSeek-OCR.git
# 创建环境
conda create -n deepseek-ocr python=3.12.9 -y
conda activate deepseek-ocr
# 安装依赖
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118
pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl
pip install -r requirements.txt
pip install flash-attn==2.7.3 --no-build-isolation
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
from transformers import AutoModel, AutoTokenizer
import torch
import os
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
model_name = 'deepseek-ai/DeepSeek-OCR'
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(
model_name,
_attn_implementation='flash_attention_2',
trust_remote_code=True,
use_safetensors=True
)
model = model.eval().cuda().to(torch.bfloat16)
# 基础 OCR
prompt = "<image>\nFree OCR. "
# 文档转 Markdown
prompt = "<image>\n<|grounding|>Convert the document to markdown. "
# 图像 OCR
prompt = "<image>\n<|grounding|>OCR this image."
# 解析图表
prompt = "<image>\nParse the figure."
# 物体定位
prompt = "<image>\nLocate <|ref|>目标对象<|/ref|> in the image."
image_file = 'your_image.jpg'
output_path = 'your/output/dir'
res = model.infer(
tokenizer,
prompt=prompt,
image_file=image_file,
output_path=output_path,
base_size=1024,
image_size=640,
crop_mode=True,
save_results=True,
test_compress=True
)
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
cd DeepSeek-OCR-master/DeepSeek-OCR-vllm
# 流式输出处理图片
python run_dpsk_ocr_image.py
# PDF 批量处理(约 2500 tokens/s on A100-40G)
python run_dpsk_ocr_pdf.py
# 基准测试批量评估
python run_dpsk_ocr_eval_batch.py
模型支持三种推理模式:
DeepSeek-OCR 的发布,可以说是标志着视觉信息压缩技术的重要进展。
20 倍的压缩率意味着,原本需要 20 块 GPU 的任务现在 1 块即可完成。
而每天 3300 万页的处理能力,则可以让中小企业也能承担极大规模文档数字化项目。
团队在致谢中提到了 Vary、GOT-OCR2.0、MinerU、PaddleOCR、OneChart、Slow Perception 等项目,以及 Fox 和 OmniDocBench 基准测试的贡献。
当视觉信息可以被如此高效地压缩和处理,多模态 AI 的实用化——
又被 DeepSeek 向前推进了一大步。
文章来自于微信公众号 “AGI Hunt”,作者 “AGI Hunt”


【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
