# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
你是否曾有过这样的经历:
用Hunyuan- Image、nano-banana等各类AI软件修图已经得心应手,但面对视频编辑,却需要打开有着复杂时间线和特效面板的视频剪辑软件(PR/FCPX),瞬间感觉「我不会了」。
图片编辑和视频编辑,仿佛是两个次元的技能树。
但如果,有一个工具,能让你像P图一样P视频呢?
今天,这个颠覆性的工具来了!
由香港中文大学、Adobe Research、约翰霍普金斯大学的研究员们联合推出的EditVerse,是一个划时代的AI模型,彻底打破了图片和视频创作之间的壁垒,用一个统一的框架,实现了对图像和视频的自由编辑与生成 。

论文链接:https://arxiv.org/abs/2509.20360
项目主页:http://editverse.s3-website-us-east-1.amazonaws.com/
测试代码:https://github.com/adobe-research/EditVerse
完整结果:http://editverse.s3-website-us-east-1.amazonaws.com/comparison.html
无论是生成音乐音符特效,还是给跳舞的人物加上一对闪亮的翅膀,你只需要输入一句话,EditVerse就能帮你实现。

EditVerse视频编辑能力展示
「数据孤岛」
视频编辑为何如此之难?
长期以来,AI视频编辑的发展远远落后于图片编辑。究其原因,主要有两大「天堑」:
这些难题,使得过去的AI视频编辑工具要么功能单一,要么效果不尽人意,始终无法像图片编辑那样灵活和强大。
EditVerse的「破壁」之道
EditVerse的革命性,在于它用一套全新的「世界观」和方法论,同时解决了架构和数据的双重难题。
核心思想一:创造一种「通用视觉语言」
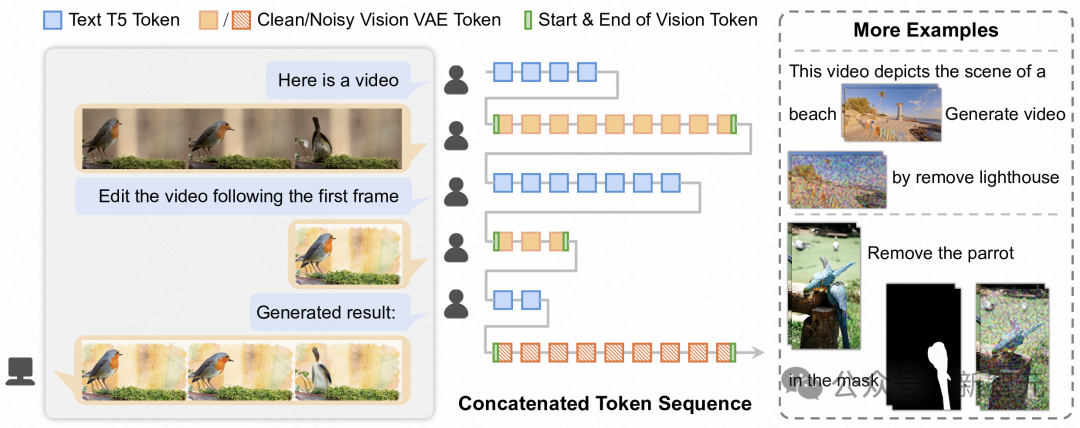
EditVerse交错文本与视觉模式的示例。EditVerse 能够处理任意分辨率、时长和顺序位置的图像与视频输入和输出。
EditVerse做的第一件事,就是教会AI用同一种方式去「阅读」世界上所有的视觉信息。它创新地将文本、图片、视频全部转换成一种统一的、一维的「数据流」(Token序列) 。这就像是发明了一种「世界语」,让原本说着不同方言(图片编码 vs 视频编码)的AI,现在可以用同一种语言进行交流和思考。
核心思想二:强大的「上下文学习能力」
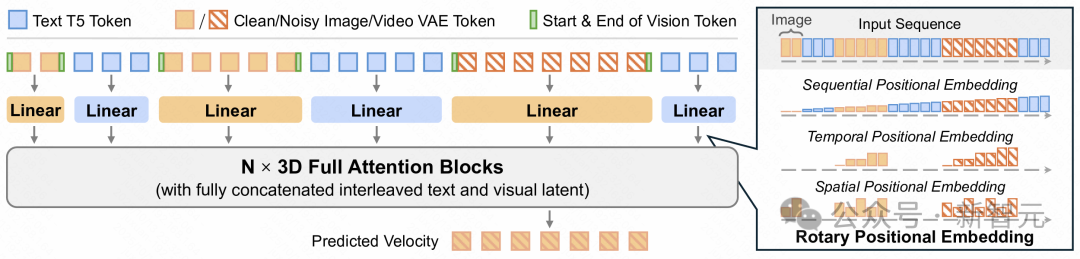
EditVerse 模型结构。研究人员设计了一个统一的图像和视频编辑与生成框架,将文本与视觉输入处理为统一的序列。图中右侧展示了位置信息编码设计(RoPE位置编码)。该框架利用全自注意力机制,以促进强大的上下文学习能力,并实现跨模态的高效知识迁移。
有了「通用语言」后,EditVerse采用了一个基于全自注意力机制(Full Self-attention)的强大Transformer架构 。通过将所有信息流在序列维度拼接在一起,EditVerse模型可以直接通过attention的上下文学习能力将不同图片、视频和文字中的信息关联起来。
你可以把它想象成一位「上下文学习大师」,它能一口气读完包含指令、原始画面的整段「数据流」,并精准理解其中每个部分之间的关联。
比如「把【视频1】左边女人的裙子变成【图2】中的裙子」 ,全注意力机制能准确地将文本指令、视频中的特定人物和图片中的服装关联起来。
同时,这种设计使得EditVerse能够灵活处理任意分辨率、任意时长的输入,真正做到了「随心所欲」 。
核心思想三:搭建一座「知识迁移的桥梁」
这正是EditVerse最巧妙的地方。因为它使用一套统一的框架同时处理图片和视频,所以它能将在海量的图片编辑数据中学到的知识(比如什么是「火焰特效」、「水彩画风格」),无缝迁移并应用到视频编辑任务中 。
这座「知识桥梁」极大地缓解了视频数据稀少的问题,让模型能够举一反三,展现出惊人的创造力和泛化能力。
训练数据与首个多分辨率视频编辑评测基准
光有聪明的「大脑」(模型架构)还不够,还需要海量的「知识」(训练数据)和公平的「考官」(评测基准)。
面对视频编辑数据稀缺的困境,EditVerse团队首先建立了一条可扩展的数据生产线。
他们利用各种先进的专用AI模型,先自动生成海量的视频编辑样本(例如物体移除、风格转换等),然后通过一个视觉语言模型(VLM)进行打分和筛选,最终精选出23.2万个高质量的视频编辑样本用于训练 。
这批视频编辑数据,与600万图像编辑样本、390万视频生成样本、190万图像生成样本等海量数据混合在一起,共同训练EditVerse,从而使模型拥有更好的知识迁移理解能力。
此外,为了科学、公正地评估模型的能力,团队还推出了业界首个针对指令式视频编辑的综合性评测基准——EditVerseBench 。这个评测基准包含了100个不同分辨率的视频,覆盖了多达20种不同的编辑任务,从简单的物体添加,到复杂的风格变换,确保能全面地检验每个模型的真实水平 。

EditVerseBench示例。EditVerseBench包含200组编辑样本,均匀分布在20个编辑类别中,视频涵盖横向和纵向两种方向。
能力展示
当想象力没有边界
EditVerse不仅统一了工作流,其编辑效果更是达到了业界顶尖水准,在人工评估(Human Evaluation)上更是超过了商业模型Runway Aleph。
下面通过一些真实的案例,感受它的强大。


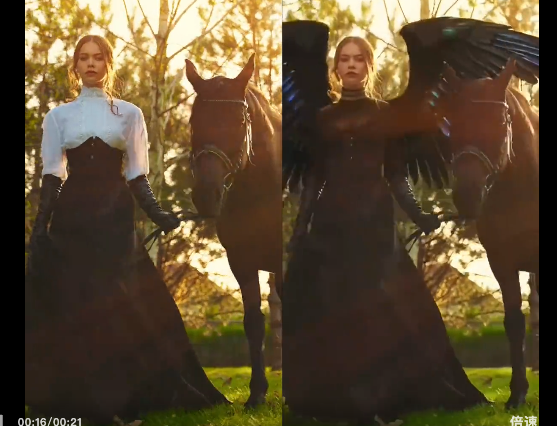
EditVerse与过往方法的完整效果对比
为了进行大规模、客观的自动化评测,团队从多个角度进行了对于各个模型的评测
在EditVerseBench基准测试上,EditVerse与现有主流方法进行了对比,结果显示其全面领先于所有开源模型 。更值得注意的是,在最符合人类偏好的VLM评分上,EditVerse超越了闭源商业模型Runway Aleph 。
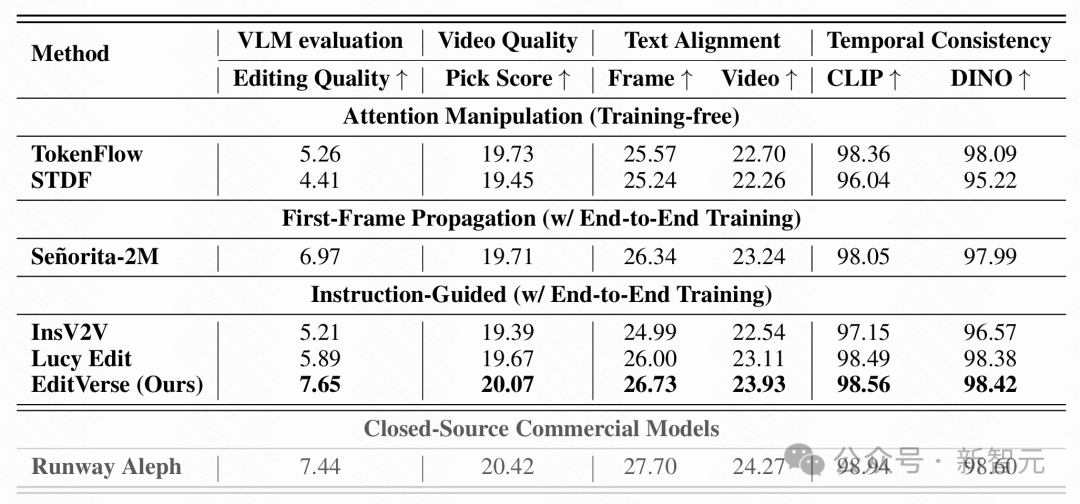
在EditVerseBench上的定量比较。对于开源研究模型,研究人员比较了两种无需训练的方法(TokenFlow和STDF)、一种首帧传播方法(Señorita-2M),以及一种基于指令的视频编辑方法(InsV2V)。最佳结果以粗体标出。还提供了一个商业模型Runway Aleph的结果。尽管由于基础模型的差异,EditVerse在生成质量上略逊于Runway Aleph,但EditVerse在编辑忠实度上(通过基于视觉语言模型的编辑质量评估)超越了它,与人类评估结果更加一致。
在编辑领域,用户的真实偏好最有说服力。在真人评测环节中,评测者在不知道模型来源的情况下,对不同模型生成的视频进行投票。
结果再次印证了EditVerse的优势:它不仅对开源模型取得了压倒性的胜利(例如对InsV2V的胜率高达96.9%),面对商业模型Runway Aleph,也有51.7%的用户认为EditVerse的效果更好 。
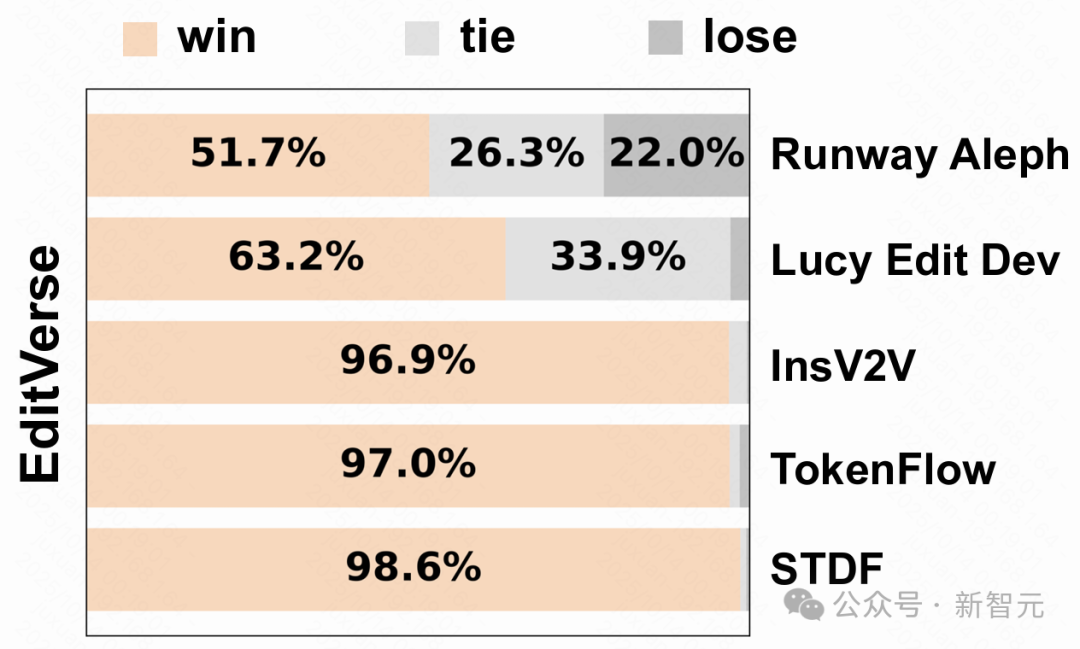
人类评估结果
EditVerse的「涌现能力」从何而来?
在测试过程中,研究人员发现了一个令人兴奋的现象:EditVerse经常能完成一些它从未在视频数据中学过的任务。
比如,指令是「把乌龟变成水晶材质」或「给天空加上延时摄影效果」,尽管它的视频训练集中并没有这类「材质变换」或「特效添加」的专项数据,但模型依然能出色地完成。
这种「无师自通」的能力,就是AI领域备受关注的「涌现能力」(Emergent Ability)。
这背后的秘密,正是前文提到的那座「知识迁移的桥梁」在发挥关键作用。
想象一下,EditVerse就像一位学徒,阅读了600万本关于「静态绘画」的顶级教材(图片编辑数据),却只看了28.8万份关于「动态影像」的简报(视频编辑数据) 。
然而,他从海量绘画教材中学到了关于光影、构图、材质、风格的深刻原理。当他处理动态影像时,他能将这些底层艺术原理灵活运用,从而「领悟」出视频中如何表现「水晶质感」或「天气变化」,即便简报里从未提过。
为了验证这一猜想,团队进行了一项关键的消融实验:他们拿走那600万本「绘画教材」(即移除图片编辑数据),只用视频数据来训练模型。
结果不出所料,新模型的视频编辑能力发生了断崖式的下跌 。
另外,团队还发现,如果将视频生成训练数据移除,模型效果同样会下降,这说明了模型是从图片编辑+视频生成两者各取其长,涌现出了视频编辑的能力。

关于训练数据的消融研究。

训练数据消融实验的可视化结果。图像数据起到了关键作用。
这项实验无可辩驳地证明了:正是从海量、多样化的图像数据中汲取的深层知识,赋予了EditVerse在视频领域举一反三、触类旁通的「涌现能力」。
它甚至能创造出比其训练数据质量更高的作品,因为它不是在死记硬背,而是在真正地理解和创造 。

将EditVerse的生成结果与真实数据进行比较。结果显示,EditVerse能够通过从图像和视频生成数据中提取知识,生成质量超越真实数据。
一个创作新纪元的开启
EditVerse的出现,其意义远不止于一个强大的工具,它预示着一个全新的内容创作范式的到来,从分离到统一,从繁琐到简洁。
EditVerse正在做的,是将专业级的视觉编辑能力,真正地普及给每一个有创意的人。
作者简介

鞠璇,香港中文大学计算机科学与工程博士生,研究方向为图像视频生成、理解生成统一模型等,曾在Meta、可灵、Adobe、腾讯、IDEA、商汤等多个公司实习。
参考资料:
https://arxiv.org/abs/2509.20360
文章来自于微信公众号 “新智元”,作者 “新智元”


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
