# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
美团,你是跨界上瘾了是吧!(doge)
没错,最新开源SOTA视频模型,又是来自这家“送外卖”的公司。
模型名为LongCat-Video,参数13.6B,支持文生/图生视频,视频时长可达数分钟。
从官方释出的demo来看,模型生成的视频不仅更加真实自然,而且懂物理的能力又双叒增强了。
无论是空中滑板:

还是一秒特效变身:

抑或是第一视角下,全程需要保持画面一致的骑车视频(时长整整有4分多种):

仔细看,视频的AI味儿浓度确实降低不少。
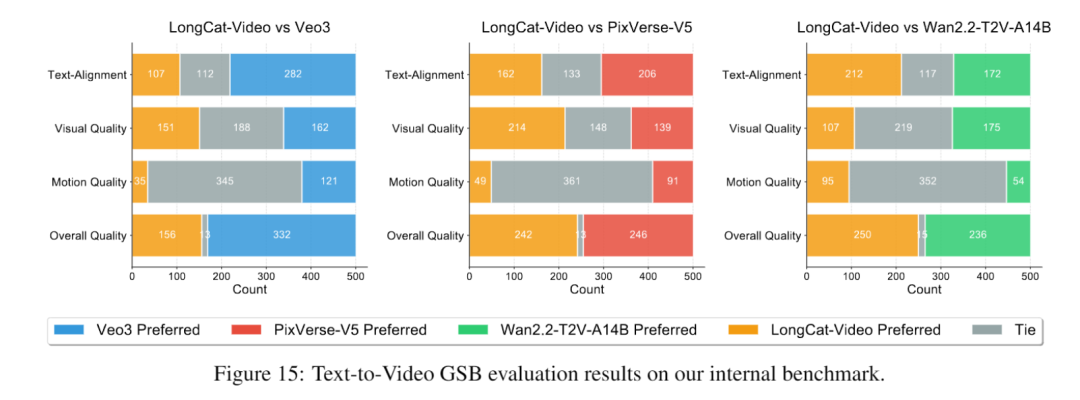
而且从测评成绩来看,其表现也相当亮眼——文生视频能力在开源模型中处于顶尖水平,整体质量优于PixVerse-V5和Wan2.2-T2V-A14B,部分核心维度甚至可与谷歌最新、最强闭源模型Veo3媲美。
而且由于采用的是允许商用的MIT协议,连Hugging Face高级主管也用三连问来表示惊叹。
中国团队竟然发布了一个MIT协议的基础视频模型???

以及其长视频生成能力(稳定输出5分钟)也被视为,“我们离视频AI的终极形态又更进一步”。
so,一家外卖公司出品的视频模型究竟如何?来看更多案例。
整体而言,美团这次发布并开源的LongCat-Video具备以下功能:
文生视频方面,从官方提供的案例来看,这个模型尤为强调对真实世界的理解能力。
一眼看去,主页上一溜的足球、体操、跳舞等视频:

仅以其中的“水上芭蕾”来看,模型面临的挑战不可谓不艰难——既需要具备高度的细节捕捉能力,还需要能够处理复杂的光影效果、环境模拟和动态场景。
而LongCat-Video几乎都考虑到了,整体完成度be like:

图生视频方面,这不双十一到了,所以各大商家也能拿来做一些更实用的宣传视频了:

当然,由于提供了原始参考图,所以图生视频上通常我们更看重模型是否能保持前后一致。
而当给了LongCat-Video一张机器人正在工作的图片后,它直接立马生成了机器人“居家办公”的日常vlog。
一会儿拿桌上的小熊、一会儿拿水杯、甚至下班关电脑……不同动作下,桌面及周围的环境均未发生“异变”,扛住了一致性挑战。

当搞定了一致性这个“老大难”后,LongCat-Video的玩法也就更多了。
白天当壁画,晚上出来打游戏可还行(谁说不是真·破壁呢?)。

还能制作动画大电影:

此外,LongCat-Video最核心的能力还在于视频延长,它能像制作连续剧一样生成分钟级长视频。
一个视频搞定后,只需接着续写提示词,最终就能生成一个完整情节或片段。
比如下面这个接近半分钟的视频,就是通过以下提示词一步步实现的(中译版):
1、厨房明亮通风,白色橱柜和木质台面交相辉映。一块新鲜出炉的面包放在砧板上,旁边放着一个玻璃杯和一盒牛奶。一位身着碎花围裙的女士站在木质台面旁,熟练地用锋利的刀切着一块金黄色的面包。面包放在砧板上,她切的时候,面包屑四处飞溅。
2、镜头拉远,女人放下手中的刀,伸手去拿牛奶盒,然后将其倒入桌上的玻璃杯中。
3、女人放下牛奶盒。
4、女人拿起牛奶杯,抿了一口。

怎么样?是不是有拍电影电视剧的感jio了~
敲黑板,由于LongCat-Video本身就经过视频连续任务的预训练,所以它能够制作长达数分钟的视频,而不会出现颜色漂移或质量下降的情况(一般可稳定输出5分钟级别的长视频,且无质量损失)。
美团表示,之所以推出LongCat-Video,核心瞄准的还是世界模型这一前沿领域:
作为能够建模物理规律、时空演化与场景逻辑的智能系统,世界模型赋予AI“看见”世界运行本质的能力。而视频生成模型有望成为构建世界模型的关键路径——通过视频生成任务压缩几何、语义、物理等多种形式的知识,AI得以在数字空间中模拟、推演乃至预演真实世界的运行。
而为了构建视频模型LongCat-Video,美团这次在技术方面也是进行了一系列创新和突破。
LongCat-Video只有13.6B,但集成了文生视频、图生视频和视频续生三大任务于一体。

具体来说,整个模型以Diffusion Transformer(DiT)为框架设计,其中每个Transformer块都由3D自注意力层、交叉注意力层,以及采用SwiGLU激活函数的前馈网络组成。
并使用AdaLN-Zero调制机制,将每个Transformer块均集成为专用的调制多层感知机,再在自注意力和交叉注意力模块中,采用RMSNorm归一化以提升训练稳定性,另外还对视觉token的位置编码使用3D RoPE。
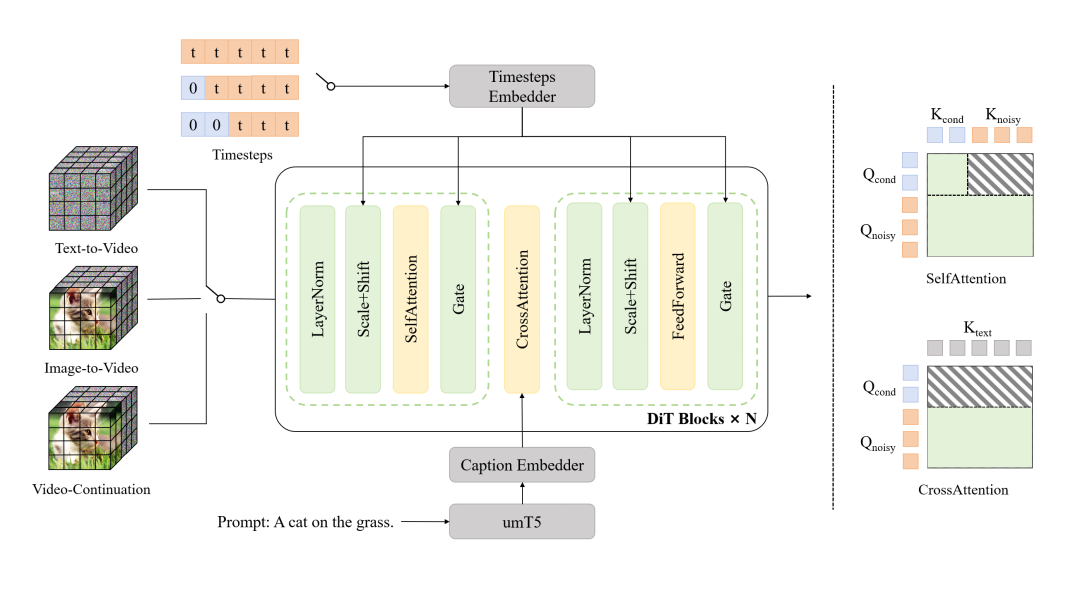
然后将所有任务都定义为视频续生任务,通过条件帧数量进行区分:
统一混合输入后,将无噪声的条件帧和待去噪的噪声帧沿着时间轴拼接,结合时序步配置,以实现单模型原生支持多任务。
而为了适配这类输入,研究团队还在架构中设计了一种带键值缓存(KVCache)的块注意力机制,该设计可以确保条件token不受噪声token的影响,且后续可以缓存并复用条件token的KV特征,提升长视频生成效率。
其中最瞩目的长视频生成能力,主要通过原生预训练设计和交互式生成支持两大核心特性实现。
首先LongCat-Video摒弃了传统的“先训练基础视频生成能力,再针对长视频任务微调”的训练路径,而是直接在视频续生任务上预训练。
这样做可以直接从源头解决长视频生成中的累积误差问题,在生成分钟级视频的同时,避免色彩漂移和质量下降。
另外LongCat-Video还支持交互式长视频生成,允许用户为不同片段设置独立指令,进一步扩展了长视频创作的灵活性。
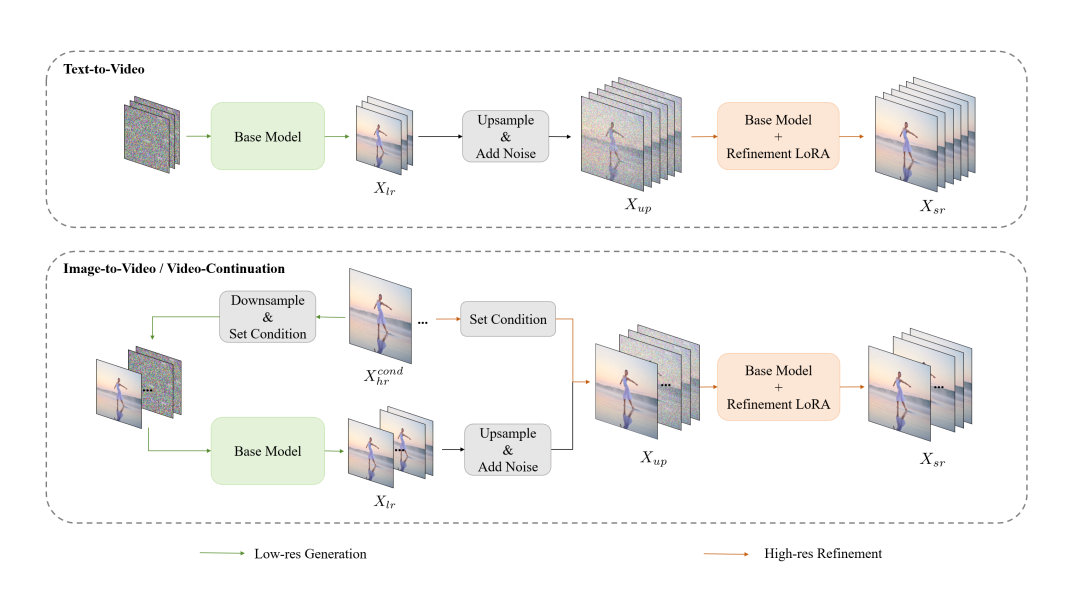
为了提高视频生成的推理效率,团队提出了一种从粗到精的生成范式,先是让模型生成480p、15fps的低分辨率低帧率视频,再通过三线性插值将分辨率升级至720p、30fps,同时由一个LoRA训练的精炼专家模型进行细节优化。
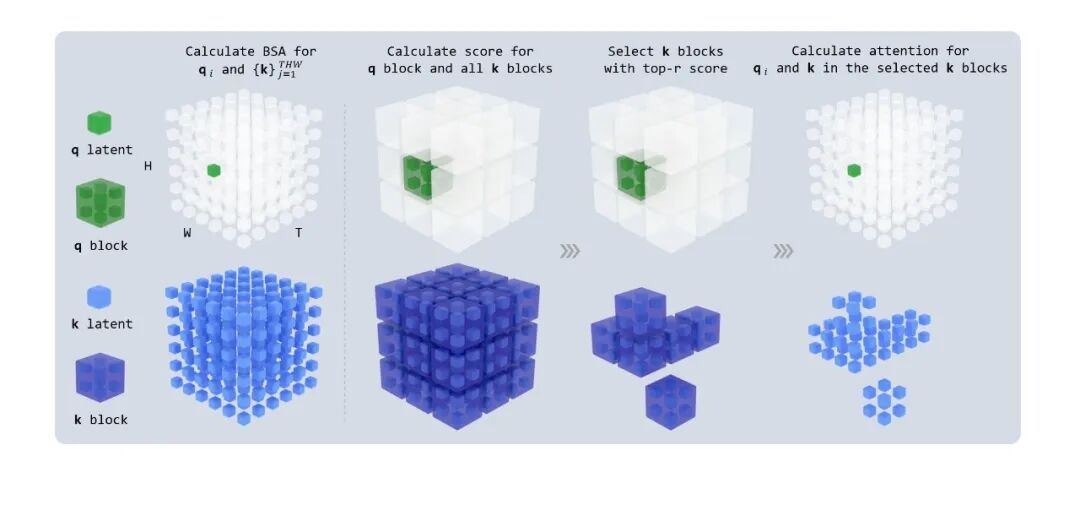
再引入块稀疏注意力,将注意力计算量降至原始的10%以下,配合上下文并行的环形块稀疏注意力,进一步优化高分辨率生成效率。
结合CFG蒸馏和一致性模型(CM)蒸馏,将采样步数从50步缩减至16步,实现在单H800 GPU上,单个720p、30fps视频生成可在分钟内完成,效率提升超10倍。
另外针对视频生成场景,使用组相对策略优化(GRPO)算法,提升GRPO在视频生成任务中的收敛速度与生成质量。

在训练过程中,分别采用三类专用奖励模型:
然后进行多奖励加权融合训练,避免单一奖励的过拟合和奖励欺骗问题,实现视觉、运动、对齐能力的均衡提升。
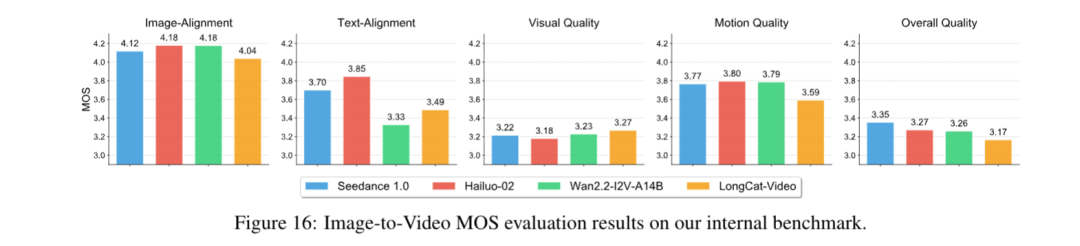
在完成数据构建和模型训练后,研究团队首先对其进行内部基准测试,主要评估文生视频和图生视频性能。
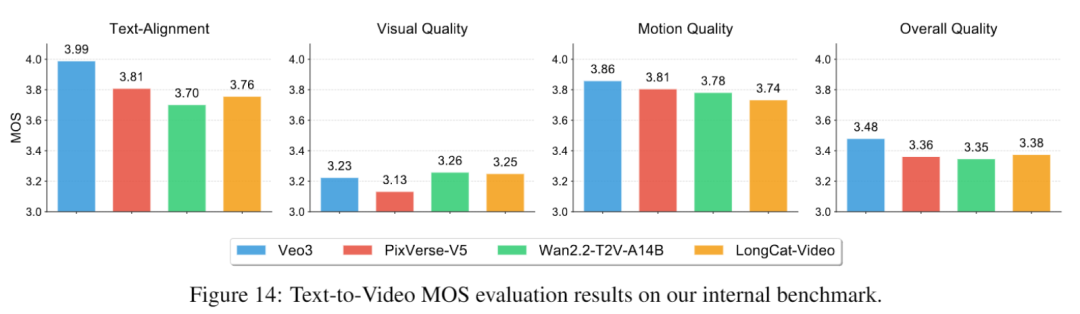
其中文生视频,包含文本对齐、视觉质量、运动质量、整体质量四个维度。
实验结果表明,LongCat-Video在整体质量得分中超越PixVerse-V5和Wan2.2-T2V-A14B,视觉质量接近Wan2.2-T2V-A14B,仅略逊于闭源模型Veo3。
图生视频则在此基础上,新增图像对齐维度评估,最终结果中LongCat-Video的视觉质量得分最高(3.27),说明整体质量具有竞争力,但图像对齐与运动质量仍有提升空间。
另外研究团队还进行了VBench 2.0的公开基准测试,LongCat-Video总得分位列第三(62.11%),仅次于Veo3(66.72%)和Vidu Q1(62.7%)。
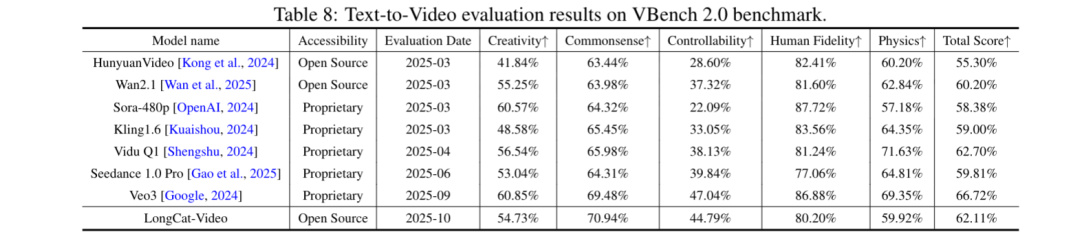
值得注意的是,LongCat-Video在常识性维度(运动合理性、物理定律遵循)上处于第一的领先优势,凸显出该模型优秀的物理世界建模能力。
而这已经不是这家外卖公司第一次“不务正业”了……
从八月底开始,美团龙猫大模型就在不停地发发发,先是端出来了最经典的开源基础模型LongCat-Flash-Chat。
总参数560B,可以在仅激活少量参数的前提下,实现性能比肩市面上的主流模型,尤其是在复杂的Agent任务中表现突出。
而且现已登陆API平台使用~
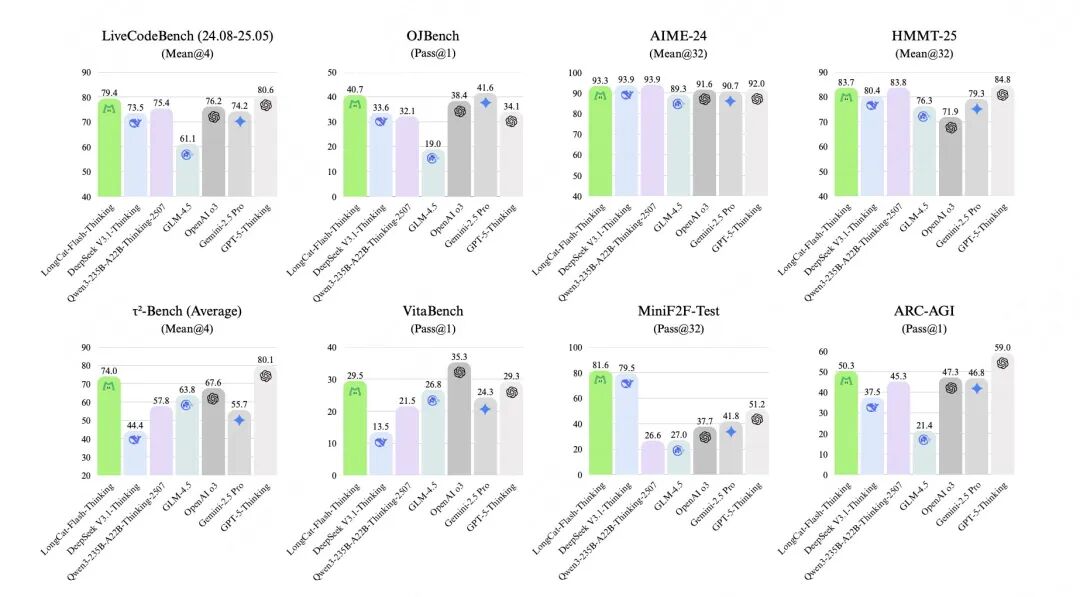
一个月不到,又上新了LongCat-Flash-Thinking,在逻辑、数学、编码、Agent多任务中均达成SOTA水平,是国内首个同时具备“深度思考+工具调用”和“非形式化+形式化”推理能力的LLM,可以实现更低成本、更优性能。
随后又专为语音LLM推出了LongCat-Audio-Codec,可以同时对语义和声学token以低帧速率(16.7Hz/60ms)并行提取,实现高效离散化,并能够在极低的比特率中保持高清晰度。
以及专为复杂现实生活场景(外卖送餐、餐厅点餐、旅游出行)打造的Agent评测基准——VitaBench,可以系统性衡量Agent在推理、工具使用和自适应交互方面的能力。(泪目,终于回归老本行.jpg)
……
最后再到今天的视频生成模型,毫无疑问,“跨界”AI正在成为这家外卖公司的新常态。
开源地址:
https://github.com/meituan-longcat/LongCat-Video
https://huggingface.co/meituan-longcat/LongCat-Video
项目主页:
https://meituan-longcat.github.io/LongCat-Video/
参考链接:
[1]https://x.com/Meituan_LongCat/status/1982083998852763838
[2]https://x.com/reach_vb/status/1982014895454331341
[3]https://mp.weixin.qq.com/s/W2T7P825mfIDwuFIsd0EgA
文章来自于微信公众号 “量子位”,作者 “量子位”


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
