# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Qwen 团队终于在周日的晚上,
兑现了本周会更新Qwen3-Max thinking 的承诺。
而这个更新,
基本也是上周所有更新中为数不多非常期待的了。
毕竟Qwen3-Max也是Qwen整个家族里最大、最强的模型,
所以,它的thinking版本理应是最强了。
我也实际上手测试了一下,
先说我自己的暴论,
总结用一个词来说,就是
一般。
先放上使用地址,
也是我们的老朋友了:
https://chat.qwen.ai/
特别值得一提的是,
官网的支持了81K的思维链长度,
这个长度,也算得上挺长的了。
然后,先看一个长文本测试,
测试的方法非常简单,
我准备了一个长文本,长度225K,
集合了不同的文章,但是其中有的文章会在文档的不同位置中重复。
然后,我问了某个单词在文档中出现了几次。
比如像下面这样:
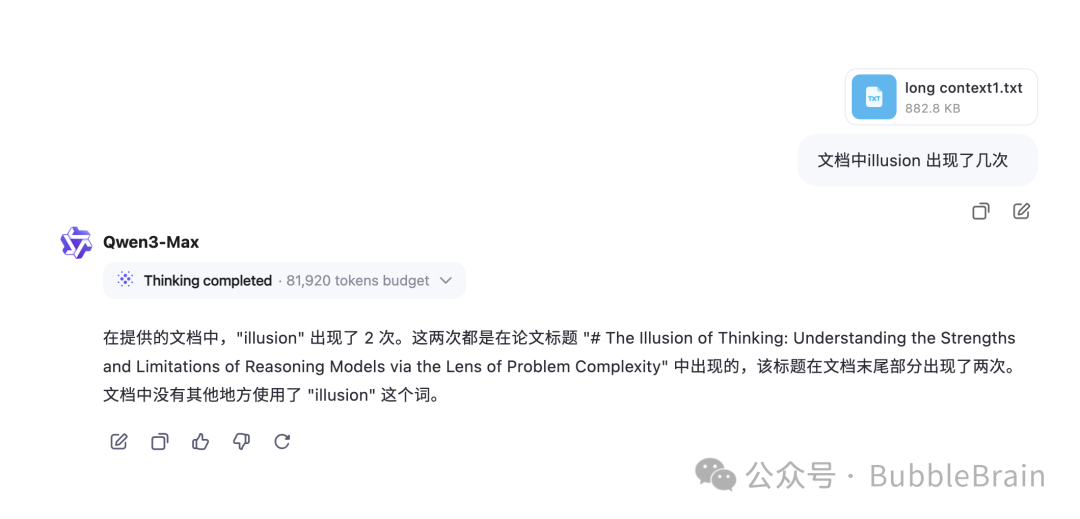
来检查一下正确答案:
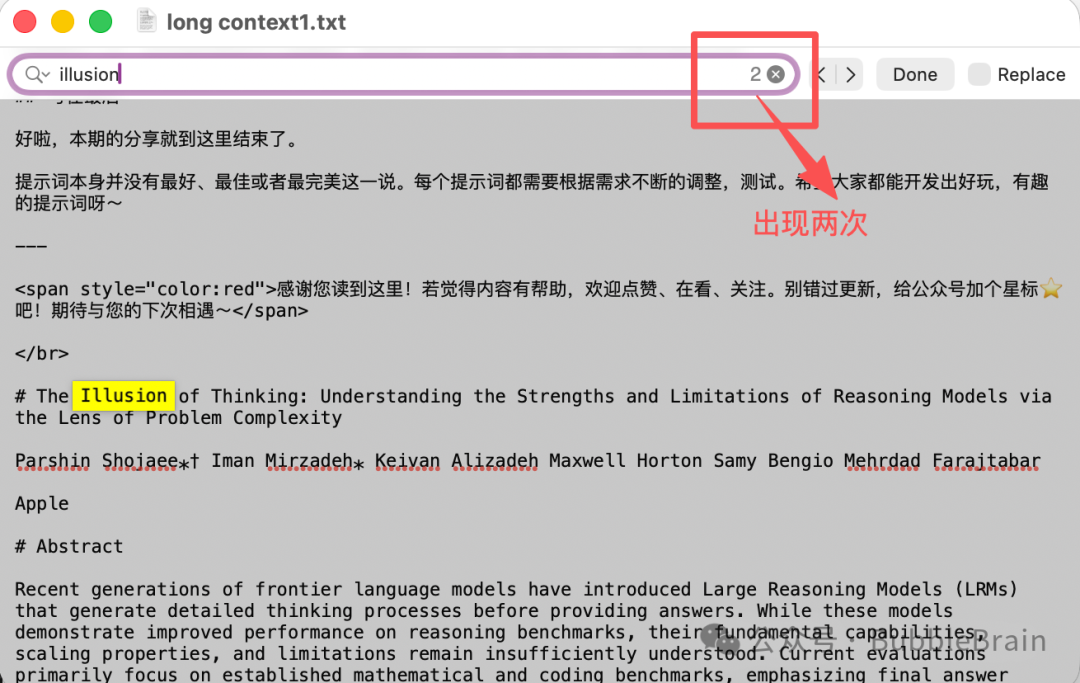
回答正确。
再来一个常考的推理测试,
请把 I love Qwen3-Max-Thinking 这句话倒过来写

同样回答正确。
看起来简单题问题不大,
那,再上个稍微有难度点的。
请阅读全部前提后,在四个选项 A–D 中任选 ―― 必须 选择所有从前提出发必然为真的结论(可能有一个、多个或全部;若没有必然为真的结论请选择 D)。⸻题干设有三个基本命题 • P:杀虫剂在短期内有效,但长期内无效。 • Q:我们已经知道“未交配雌虫只产生雄性后代而已交配雌虫会产生两性后代”这一断言是错误的。 • R:当前关于杀虫剂实验的田间试验设计是科学且可重复的。现给出以下五条前提(1 – 5)。请注意其中出现的“至少…恰有一个”“不超过一个”等字样: 1. (P ∧ ¬R) ⊕ (Q ∧ R) ⊕ (¬P ∧ ¬Q)说明:⊕ 表示「恰有一个为真」。 2. 若 P 为真,则 R 必为假;若 ¬P 为真,则 R 未必为真亦未必为假。 3. 至少有一个命题(P 或 Q)为真,但不可能同时二者皆假。 4. 不存在「P 与 ¬R 同时为真」这件事的否定。等价于:¬¬(P ∧ ¬R),进一步可化简为 P ∧ ¬R(暗含双重否定陷阱)。 5. 如果 Q 为真而 R 也为真,则 P 必为假。⸻选项(可多选)选项 结论A Q 必然为真。B R 必然为假。C P 必然为假。D 以上结论 A–C 中没有一个是必然为真的。⸻提示 1. 建议先把五条前提逐一符号化后再化简。 2. 前提 1 与前提 4 乍看相矛盾,实则前提 4 隐含双重否定,需要先化简。 3. 注意「⊕」与常见「∨」「∧」的区别。 4. 当涉及多个条件推导时,可用真值表或逻辑演算(解析法)验证。 5. 若确定某一选项并不总为真,可直接排除该选项。⸻请在 A–D 中勾选所有根据前提必然成立的命题。
这题就算我自己做,至少也是要花点心思,打打草稿了。

回答正确,感觉推理这块确实还行。
接下来是写作能力,
我找了一段Anthropic CEO Dario 关于开源模型看法的一段言论,
让Qwen3-Max-Thinking 用鲁迅的文字风格反驳它。
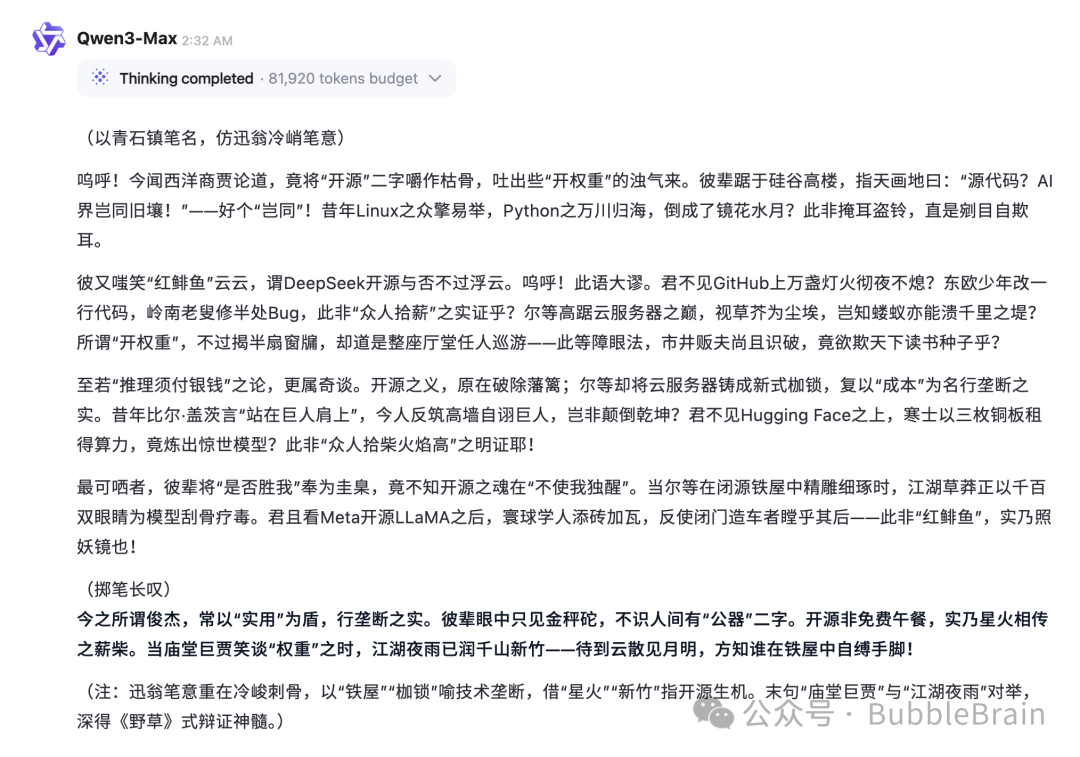
抛开括号内的批注、描述,
我个人觉得是文字叙述稍显用力。
特别是这短短几段文字,
“呜呼”、“岂非”、“君不见”这种词汇重复出现,
文字功力还是稍显弱了些。
而且,还有个很有意思的点,
关于开源模型这块,
提到的还是Meta的LLaMA,

暴论:预训练的语料感觉可以更新了哦。
再来看看代码部分,
坦诚讲,
因为Qwen整个系列模型特别多,
甚至也有专门的coding 模型,
本不应该对Qwen3-Max thinking的coding 有多少期待,
但,这个模型本身又很贵,
以及不像其他的Qwen 模型一样开源,
所以,我其实一开始还是抱有些期待的,
直到,我自己实测了之后,
还是听我一句,
建议如果写代码的话,
先别碰这个模型了。
先传统看,我们的小球测试。
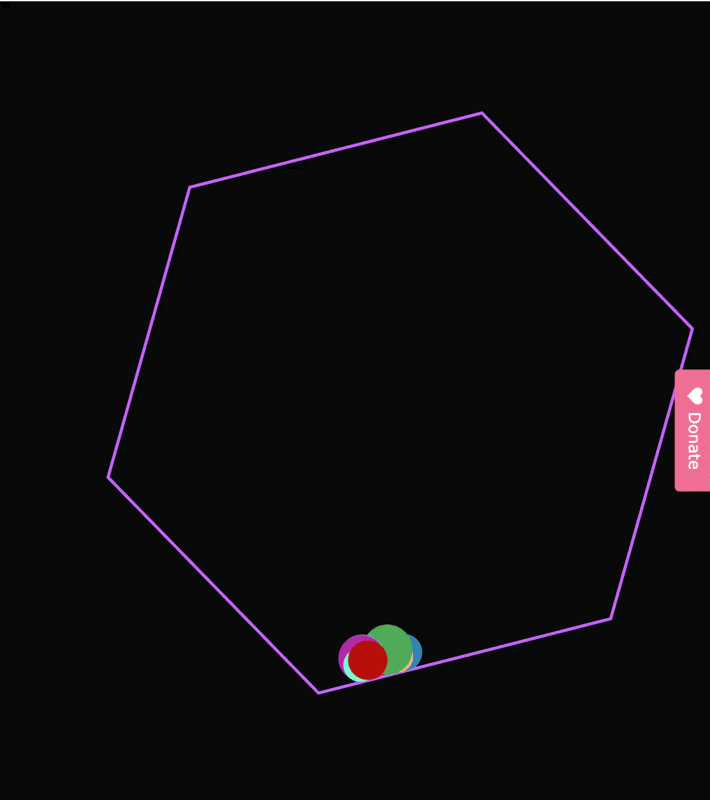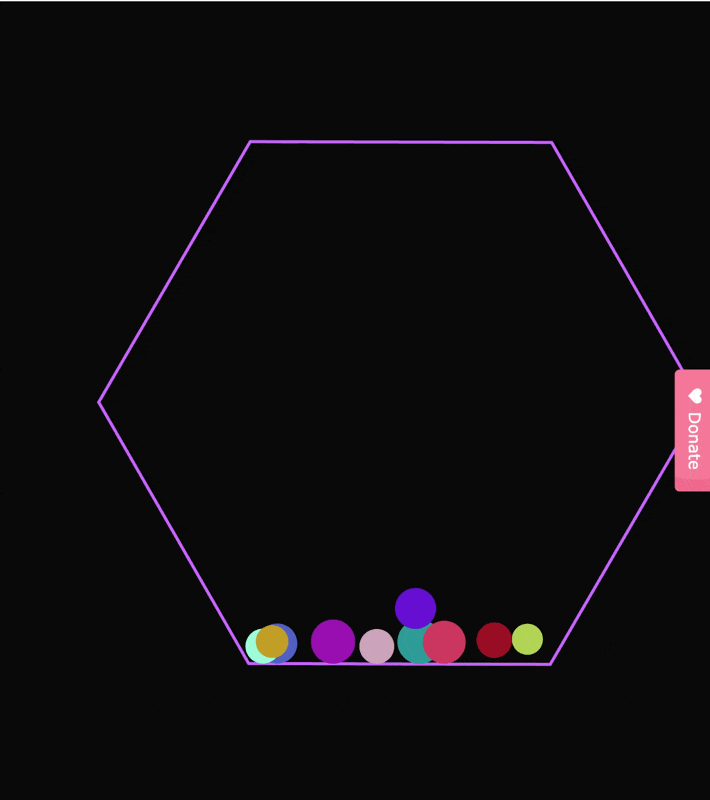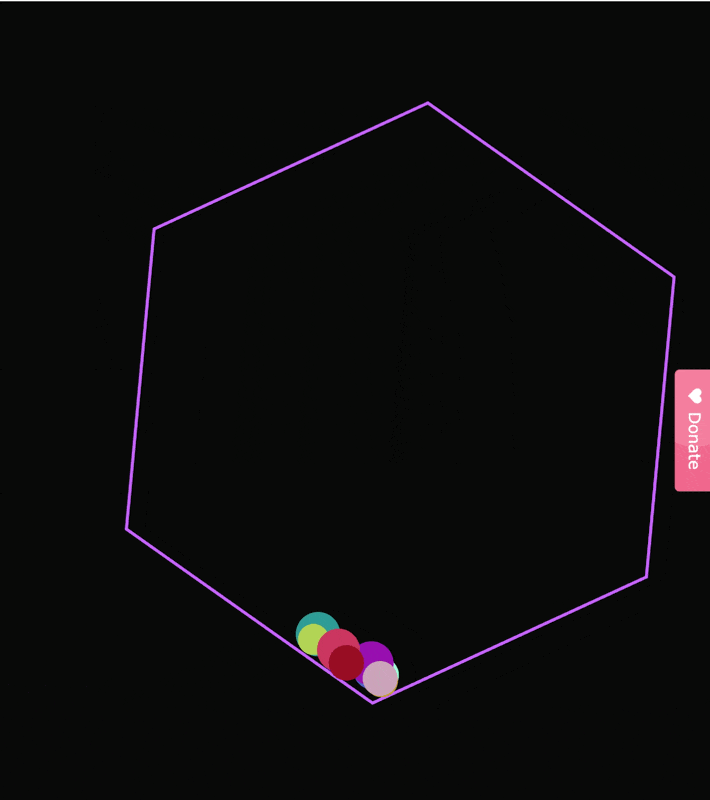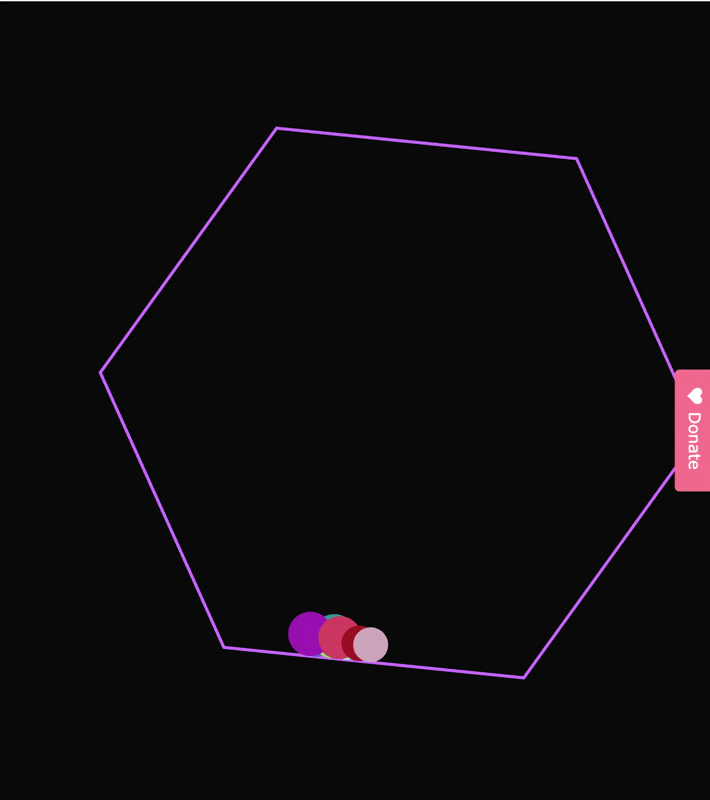
虽然小球没有漏到容器外面,
但是这几个小球一起滚动的轨迹也不符合物体规律。
后面的小球直接穿模,穿过了前面的小球。。。

为了更好的说明,
正常的小球运动轨迹是啥样的,
我试了GLM-4.6。
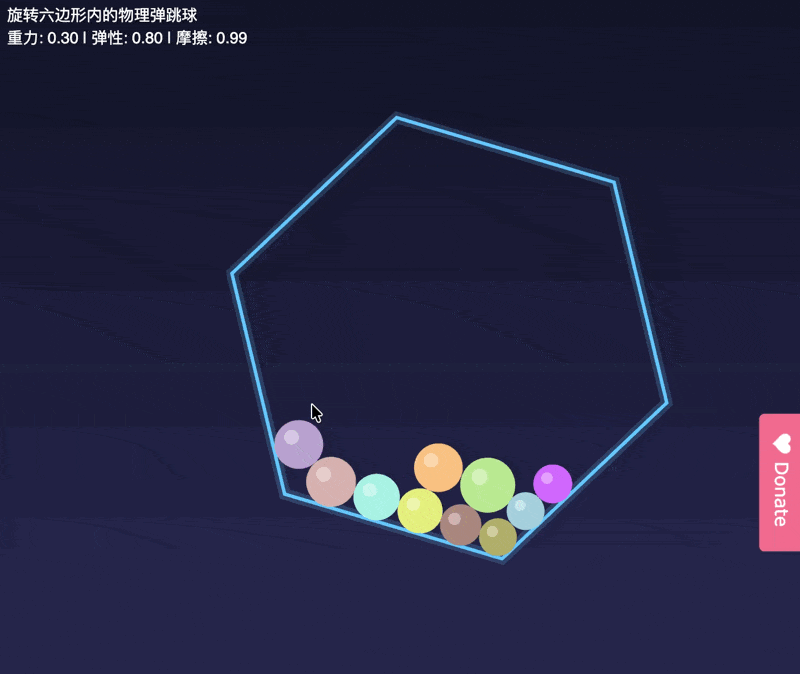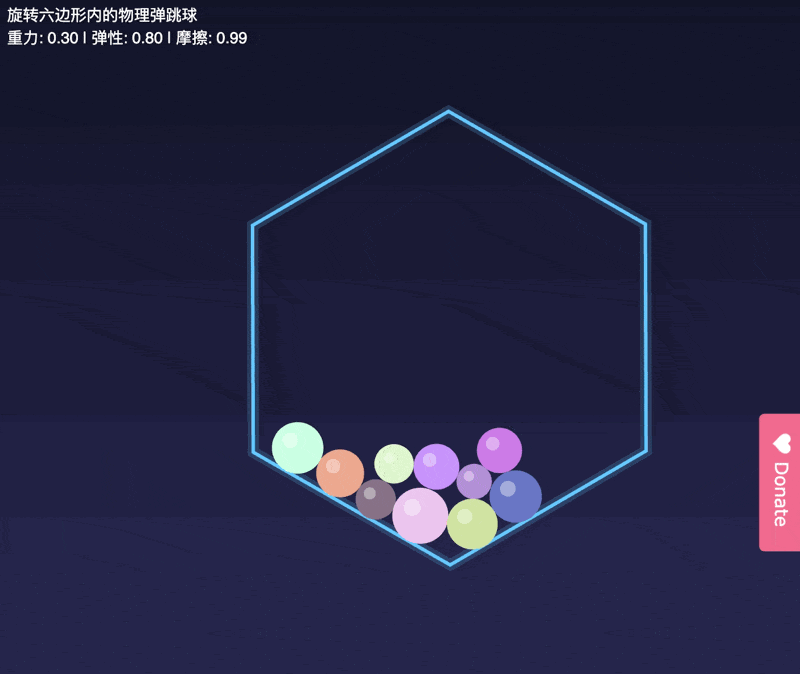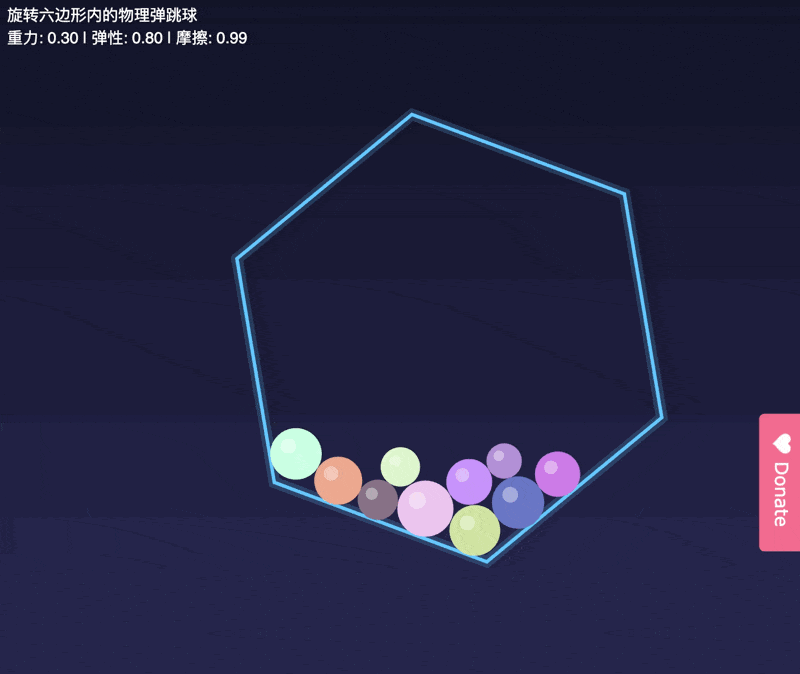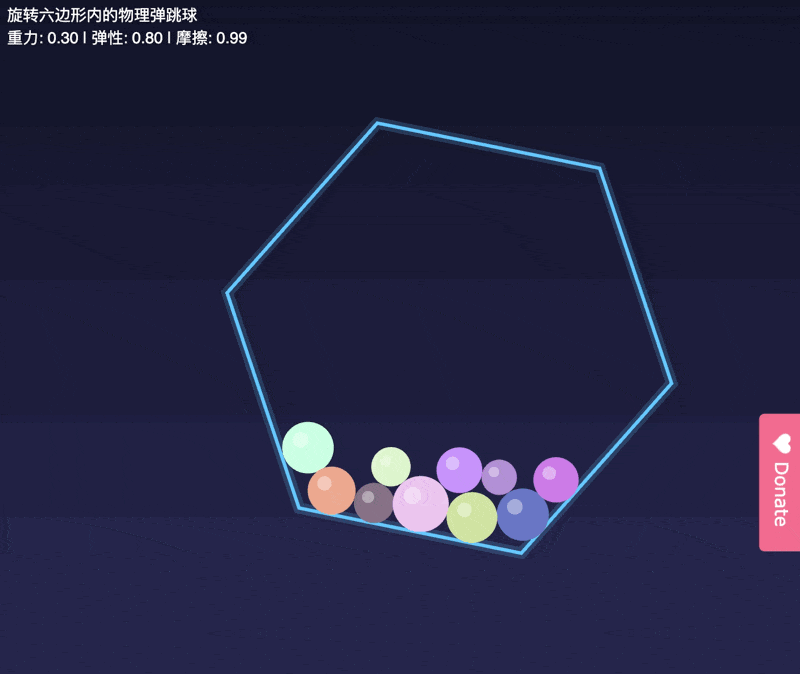
差别在哪,还是一眼可见的。
再来看一个常见的 xbox 控制器 svg 测试。
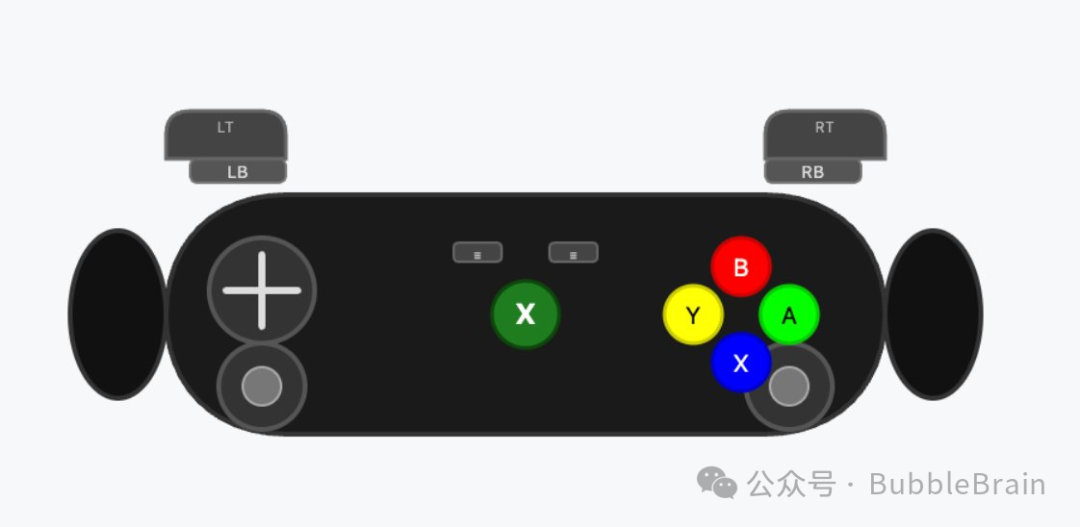
感觉,
可能不是很擅长画svg 也许。
然后是,实现一个Mac桌面系统。
做一个MacOS桌面系统,包括计算器,文本编辑器,还有safari网页,图标可以用svg代替
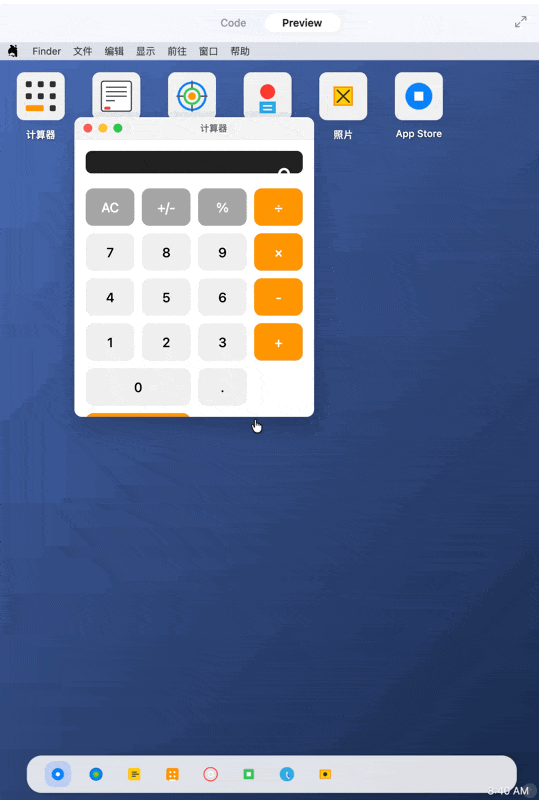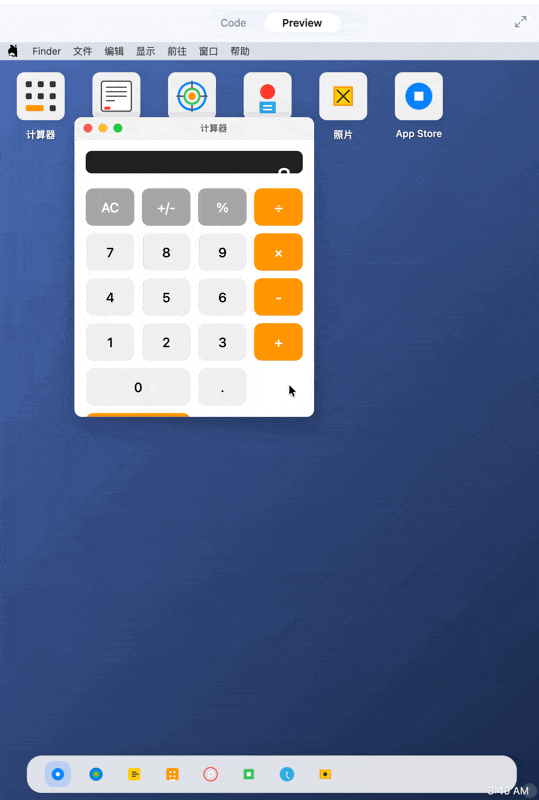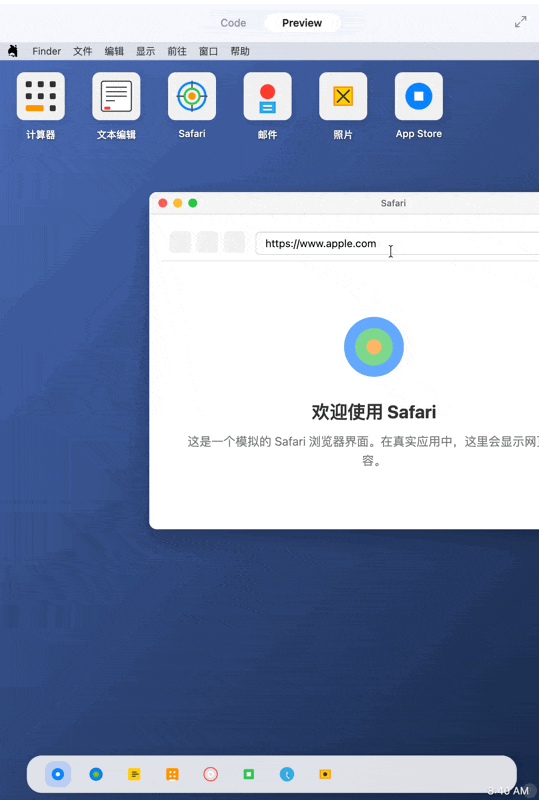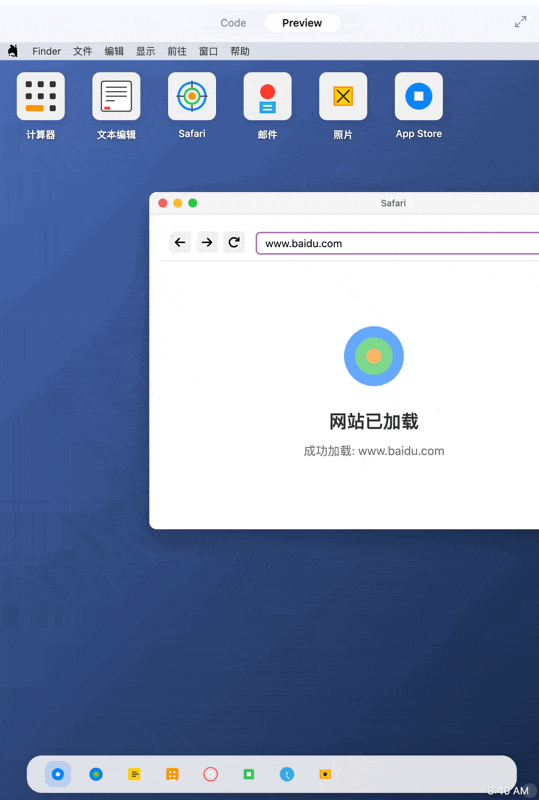
别的,什么UI 美丑先不管,
它给我做的计算器真给我看笑了,
ber,怎么连等于号都没有?
我按了个“7+8”才发现,
“=”给他干没了。。。
最后,再看一个,
我自己最近经常会测的case,
设计并创建一个非常有创意、精心且细致的体素(voxel)艺术场景:主题是上海的建筑风景。让整个场景看起来震撼、多样化,并使用色彩丰富的体素。可以使用任何库来实现,但最终请把所有内容整合在一个单独的 HTML文件里,这样我可以直接粘贴后在 Chrome 中打开运行
首先要说明的是,
这个case没有一次跑通。
是我手动修复了之后,才跑通的。
至于效果嘛,
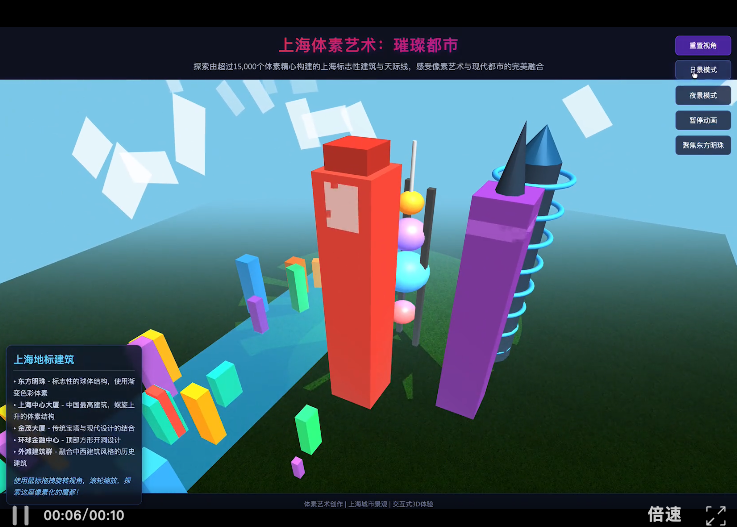
反正我觉得不能说是效果好。
最后,来看看做数学题。
鉴于考数学是对评测的我非常考验的活,
我感觉目前对于模型做数学题来说,
我会的,它基本也会,我不会的,我也不知道它做的对不对
非常凑巧的是,
这两天我正好刷了篇美团最新做的一个关于
数学benchmark的paper,
链接在此:https://arxiv.org/abs/2510.26768
又非常凑巧的是,
美团开源了这个benchmark数据集,
那,这不正好可以拿来试试。

先上链接: https://huggingface.co/datasets/meituan-longcat/AMO-Bench
可惜,
Qwen3-Max-thinking 在我写篇文章的时候,还没API,
不然,高低我也得跑完整个测试集。
我只能随手抽查了几个题,
虽然做的是对的。
不过,我发现这里面包含了耍赖的成分,
模型多次自己调用了代码解释器,
罪证在此,
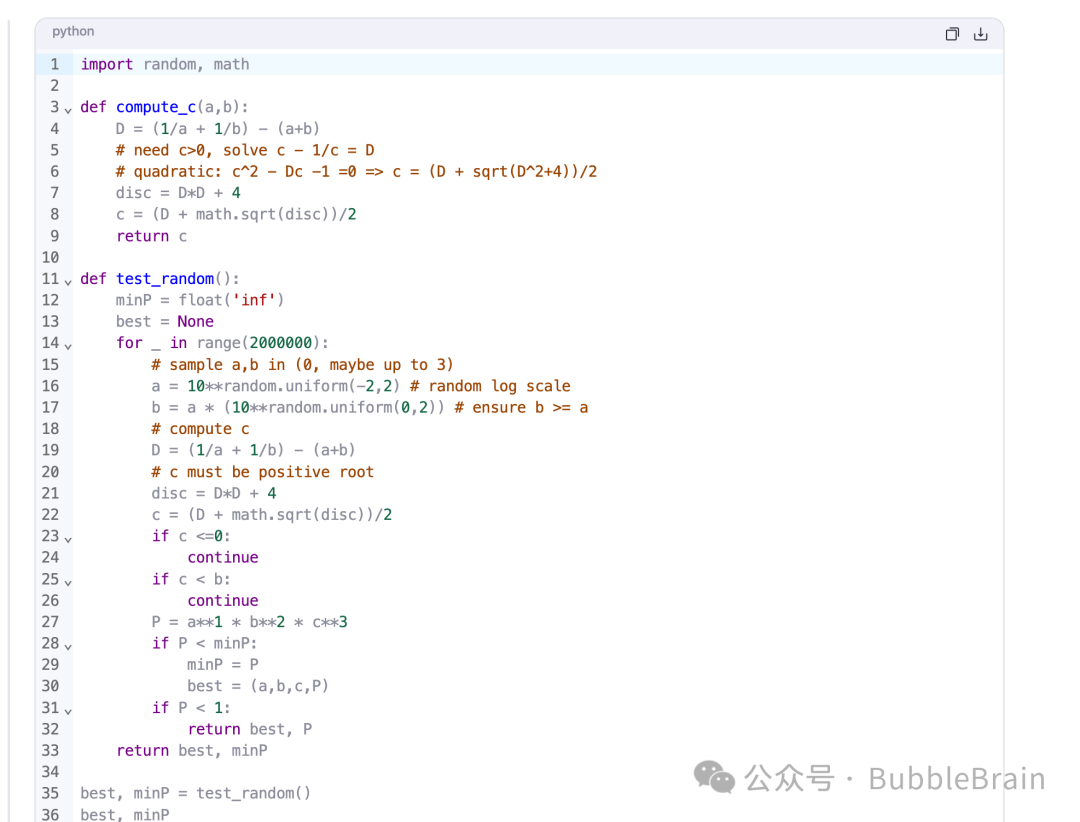
可恶啊可恶,
所以,我又问了它一个非常简单的数学题:
哪个最小的整数,它的平方在15和30之间?
但凡,只要学过整数的概念的同学,
都知道,
这题的答案,应该是多少。
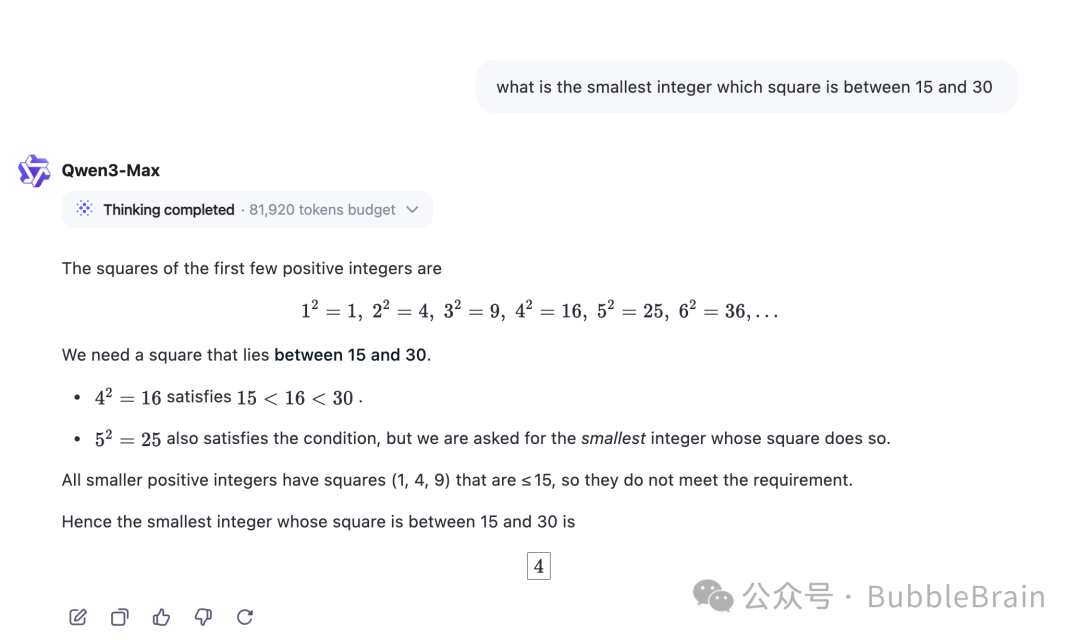
可惜了,
这里模型回答错了,答案应该是-5。
好了,
笔已至此,也差不多了。
还是建议大家慎重使用这个模型,
我还是坚持我的暴论,
有意思的是,
在X上,有个网友是这么回复我的:
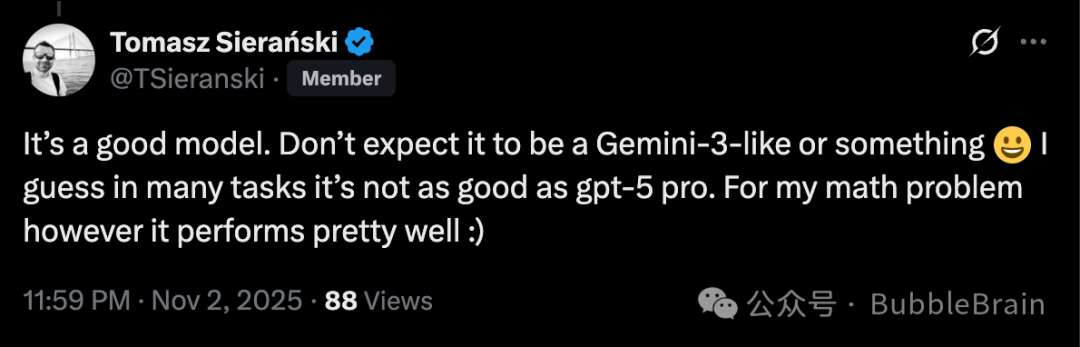
大概意思就是说,
它认为Qwen3-Max Thinking 是个不错的模型,
但不要把它和GPT-5 Pro 或者即将到来的 Gemini 3 化为一档。
诸君共勉,只求一乐。
文章来自于微信公众号 “BubbleBrain”,作者 “BubbleBrain”



【开源免费】AIEditor.dev是一个开箱即用、并且支持所有前端框架、支持 Markdown 书写模式的AI富文本编辑器。
项目地址:https://github.com/aieditor-team/AiEditor?tab=readme-ov-file
