# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
刚刚,OpenHands 开发团队发布了一篇新论文,正式宣布广受欢迎的软件开发智能体框架 OpenHands (GitHub star 已超 6.4 万)中的智能体组件完成了架构重构,即 OpenHands Software Agent SDK。
这一轮重新设计改进巨大,也让 OpenHands 从 V0 进化到了 V1。包括:
该团队表示:「这些元素使得 OpenHands Software Agent SDK 能够为原型设计、解锁新型自定义应用以及大规模可靠部署智能体提供一个实用的基础。」

OpenHands 团队表示,OpenHands V0 最初设计为单体架构,即将智能体逻辑、评估和应用组合在同一个代码库中;这样做目的是为了实现快速原型设计和迭代,但这种设计在项目的发展中暴露出了许多短板,包括沙盒僵化、可变配置庞杂,以及研究与生产之间过度耦合。因此,全面的重构势在必行。
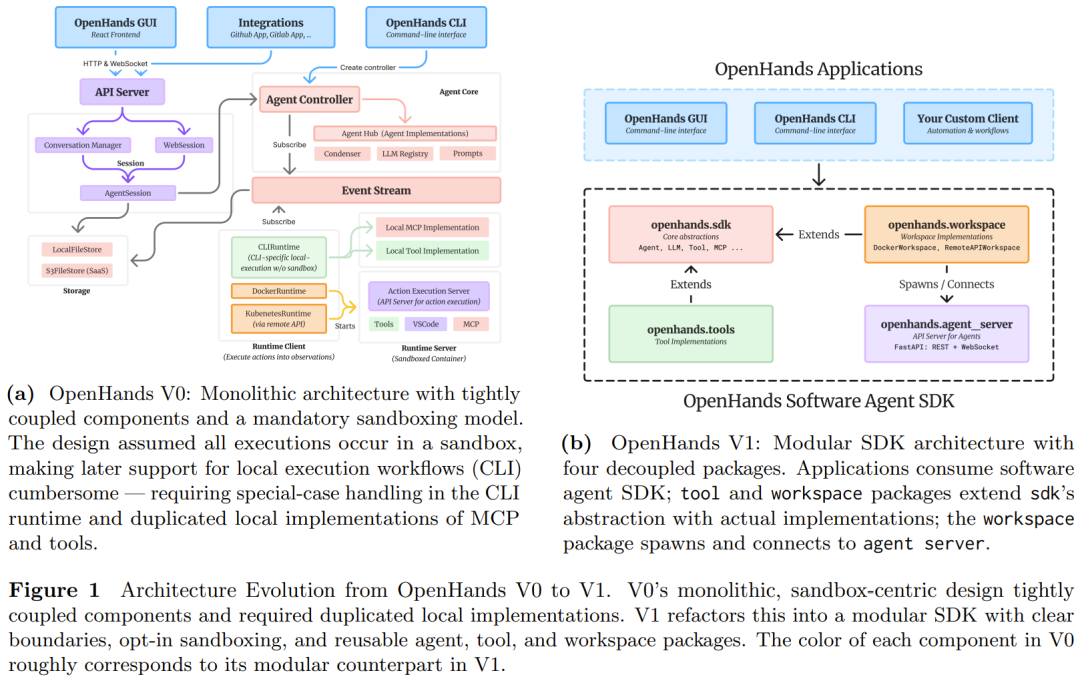
汲取了这些教训,OpenHands V1 引入了一个基于四项设计原则的新架构,这些原则直接解决了 V0 的局限性。具体来说,这些原则包括:
1、沙盒化应该是可选的,而非普遍适用的
V1 默认设置是在单个进程中统一智能体和工具的执行,这与 MCP 的假设一致。当需要隔离时,同一个栈可以被透明地容器化。沙盒化变成了可选的,从而在不牺牲安全性的前提下保持了灵活性。
2、默认无状态,状态的真值来源单一
V1 将所有智能体及其组件(工具、LLM 等)视作在构建时即被验证的、不可变的且可序列化的 Pydantic 模型。唯一可变的实体是会话状态,它是一个单一的、明确定义的真值来源(source of truth),用于跟踪正在进行的执行。这种设计将变化隔离在一个地方,实现了确定性重放、强一致性和稳定的长期恢复。
3、保持严格的相关项分离
V1 将智能体核心隔离成了「软件工程 SDK」。应用通过 SDK API 进行集成,使得研究可以独立于应用进行演进。
4、一切都应是可组合且可安全扩展的
V1 将可组合性作为两个层面上的首要设计目标。
在部署层面,其四个模块化包(SDK, Tools、Workspace 和 Agent Server)可以灵活组合,以支持本地、托管或容器化执行。
在能力层面,该 SDK 会暴露一个类型化的组件模型(工具、LLM、上下文等),让开发人员可以声明式地扩展或重新配置智能体,而无需触及核心。
OpenHands V1 便是基于这些原则而生的,这是一个完整的软件智能体生态系统,包括 CLI 和 GUI 应用。它们构建在一个共享的基础上:OpenHands Software Agent SDK (图 1b)。
下图展示了一个极简示例:

该 SDK 定义了一个具有确定性重放 (deterministic replay) 功能的事件溯源 (event-sourced) 状态模型、一个用于智能体的不可变配置,以及一个集成了 MCP 的类型化工具系统。

其工作区抽象使得同一个智能体能够在本地运行以进行原型设计,或者在安全、容器化的环境中远程运行,而只需最少的代码更改。

与之前仅提供库的 SDK 不同,OpenHands 包含一个用于远程执行的内置 REST/WebSocket 服务器,以及一套用于人工审查和控制的交互式工作区界面 —— 一个基于浏览器的 VSCode IDE、VNC 桌面和持久化的 Chromium 浏览器。

该团队还系统地比较了其 SDK 与 OpenAI Agents SDK、Claude Agent SDK 和 Google ADK 的 31 个特性,发现尽管有 15 个特性与它们中的至少一个共享,但 OpenHands 的 SDK 独特地结合了 16 个额外特性,包括原生远程执行、带沙盒功能的生产服务器,以及跨越 100+ 供应商的模型无关的多 LLM 路由。
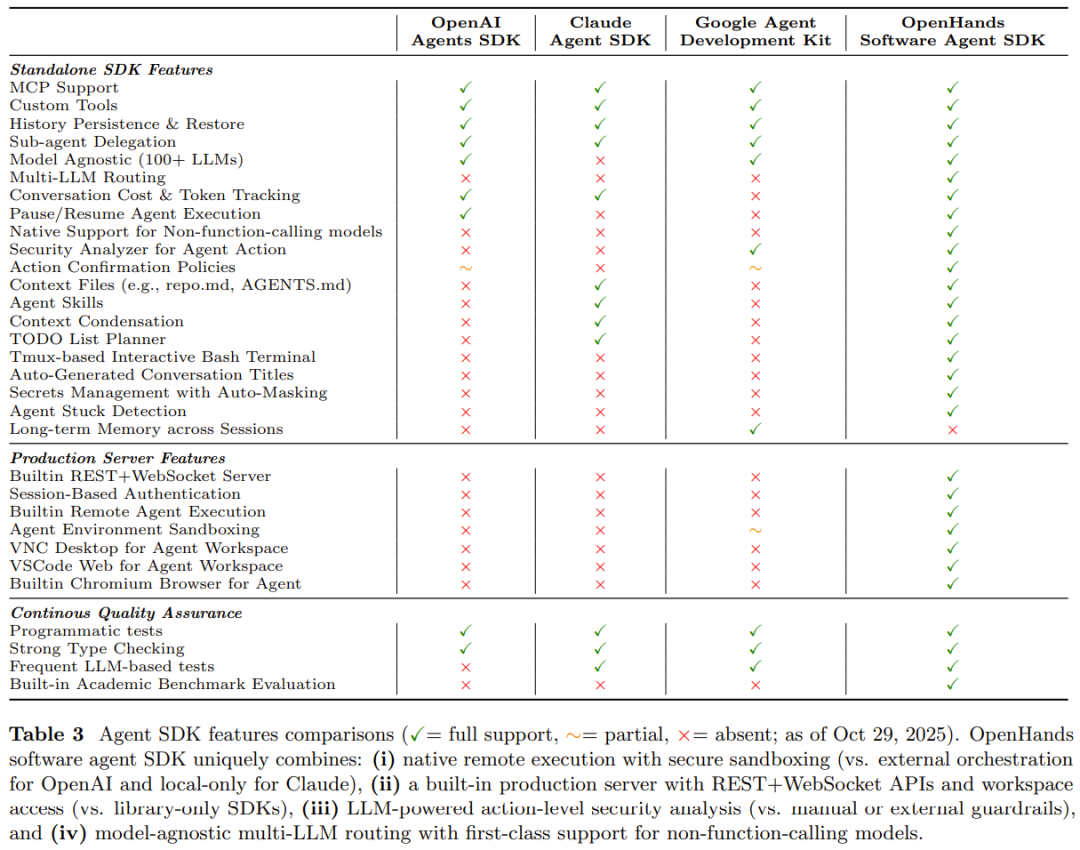

该 SDK 还增加了一个用于智能体操作的安全分析器、灵活的生命周期控制(暂停 / 恢复、子智能体委托、历史恢复等),以及用于保障生产可靠性的内置 QA (质量保证) 插桩(单元测试、基于 LLM 的集成测试和评估基准)。
OpenHands Software Agent SDK 已在 MIT 许可下完全开源。
该团队通过两个互补的过程评估了 OpenHands Agent SDK 的可靠性和性能:持续测试和基准评估。
持续测试流程结合了程序化测试和基于 LLM 的测试,并在每个拉取请求 (pull request) 上自动运行,且每天运行一次。它检查的是 SDK 在多种语言模型下是否表现一致,及早发现推理、工具使用和状态管理方面的回归问题。这些自动化测试每次完整运行的成本仅为 0.5–3 美元,并能在 5 分钟内完成。
而基准评估则是在标准化的智能体任务上衡量 SDK 的整体能力,从而帮助了解模型质量和系统性能。
持续质量保证
该 SDK 采用了三层测试策略来平衡覆盖范围、成本和深度:
集成测试覆盖多种基于场景的工作流(例如,文件操作、命令执行、git 操作和浏览),而示例测试(example tests)则会定期运行所有 SDK 示例(自定义工具、MCP 集成、持久化、异步执行、路由等),以确保端到端的可靠性。该测试套件会随着新智能体行为和故障模式的发现而不断扩展,从而提高覆盖范围和回归敏感性。
该团队还针对这些基于 LLM 的测试的按需执行进一步优化了 CI/CD 成本:集成测试针对高风险变更,示例测试覆盖面向用户的模块,而每日运行则跟踪整个代码库更新中的回归问题。
基准测试
该 SDK 为评估智能体能力的各种学术基准提供了内置支持。
如表 2 所示,该 SDK 在软件工程和通用智能体基准测试中表现得很有竞争力。
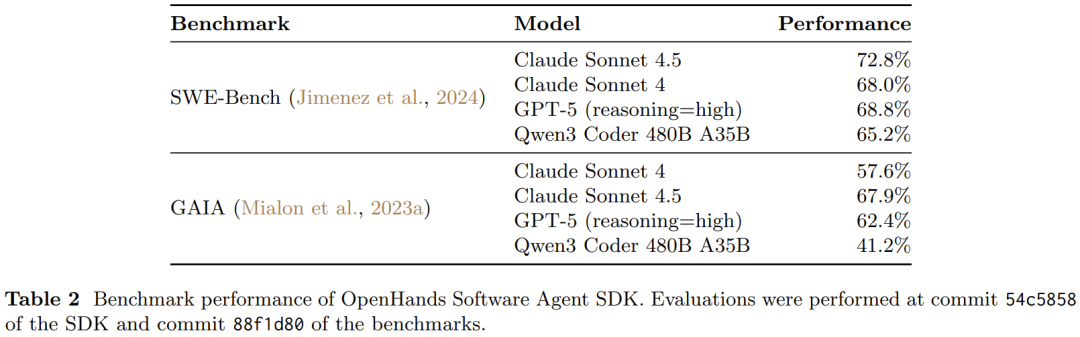
在衡量智能体在软件工程任务中能力的 SWE-Bench Verified 上,该 SDK 使用 Claude Sonnet 4.5 配合扩展思维实现了 72% 的解决率;在衡量智能体通用计算机任务解决能力的 GAIA 上,SDK 使用 Claude Sonnet 4.5 实现了 67.9% 的准确率,展现了有效的多步推理和工具使用能力。
此外,强大的开源编码模型 Qwen3 Coder 480B 实现了 41.21% 的分数。这些结果略优于 OpenHands-Versa 的结果,表明该 SDK 的架构并未牺牲智能体能力,并实现了与研究专精系统相媲美的性能。
文章来自于微信公众号 “机器之心”,作者 “机器之心”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
