# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
华中科技大学团队推出首个水下多模态大模型NAUTILUS,支持8种水下场景理解任务,并开源145万图文对的NautData数据集。模型通过视觉特征增强模块解决水下图像模糊和颜色失真问题,性能超越现有模型,恶劣环境下表现更佳。
深邃的海洋覆盖地球表面的70%以上,其在资源勘探、环境保护和国家安全等领域的重要性,使自动化水下探索技术备受关注。
然而,想要像《海底两万里》中的「鹦鹉螺号(NAUTILUS)」那样自由地认知和探索水下世界,我们仍面临严峻的技术挑战。光线在水中的严重散射和吸收导致图像质量显著下降,这极大地削弱了通用大模型的性能,阻碍了水下场景理解的研究进展。

现有的水下视觉方法又大多为单一任务设计,缺乏多粒度的综合感知能力。大规模、多任务指令微调数据集的长期缺失,进一步制约了该领域的研究进展。

针对以上挑战,华中科技大学白翔教授团队提出了首个能够支持八项水下场景理解任务的水下多模态大模型NAUTILUS,旨在通过统一的框架实现对水下场景从图像、区域到物体的多粒度、多任务的全面理解。

论文地址:https://arxiv.org/abs/2510.27481
项目地址:https://h-embodvis.github.io/NAUTILUS
代码地址:https://github.com/H-EmbodVis/NAUTILUS
数据集地址:https://github.com/H-EmbodVis/NAUTILUS/tree/dataset
同时,团队还构建并开源了首个大规模水下多任务指令微调数据集NautData。
该工作的主要贡献如下:
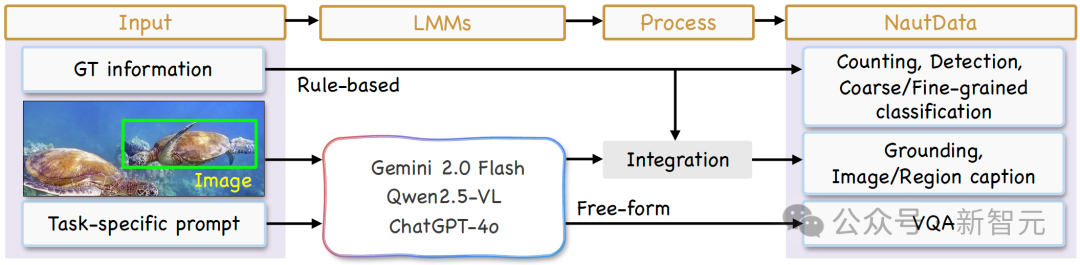
该工作围绕八项任务进行数据构建,并为每项任务设计了定制化的数据生成流程。
整个流程通过三种模式构建数据,分别为基于规则的生成 (Rule-based generation),组合生成 (Integration generation)与自由格式生成 (Free-form generation)。
其中,基于规则的生成利用预定义模板构造问答对,组合生成结合模板与大型语言模型(LMM)的输出以丰富数据,而自由格式生成则允许大型语言模型根据自主关注的内容灵活创建问题与答案。
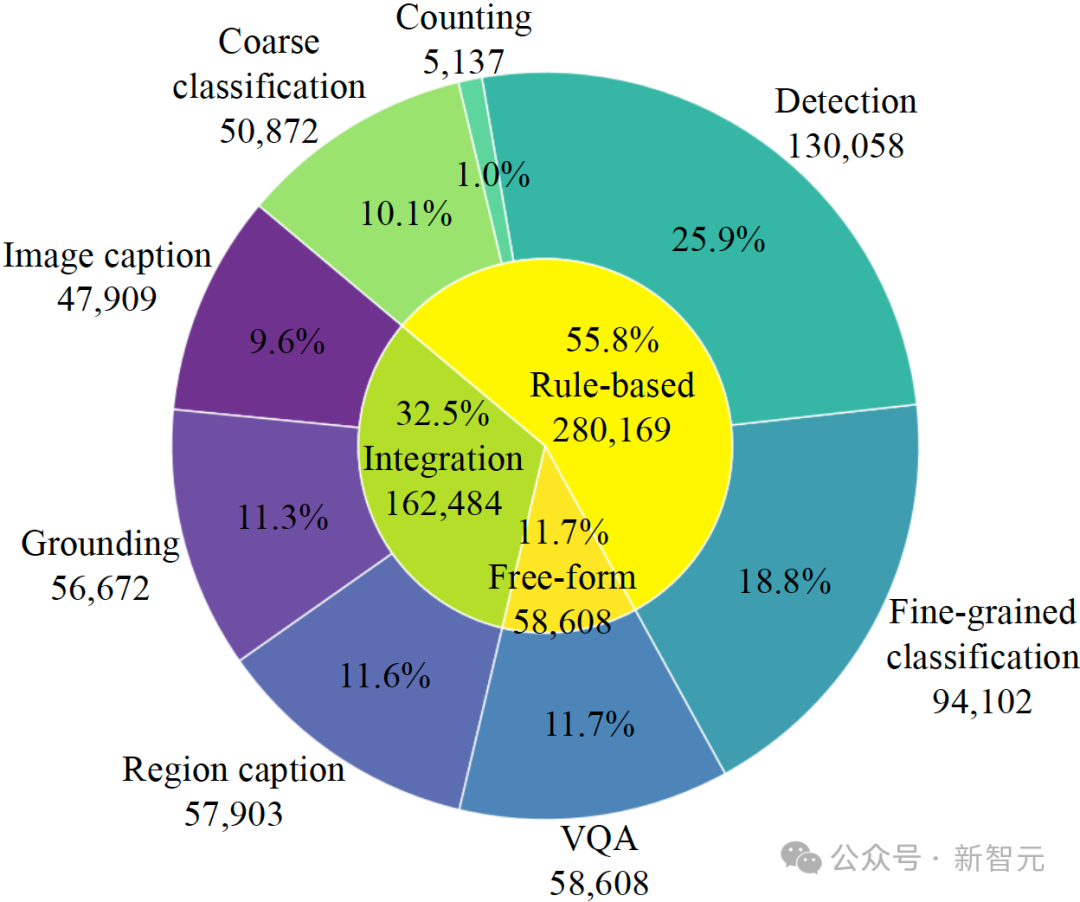
数据集统计信息。外环显示了数据在八项任务上的分布,内环则显示了三种生成模式的构成比例。
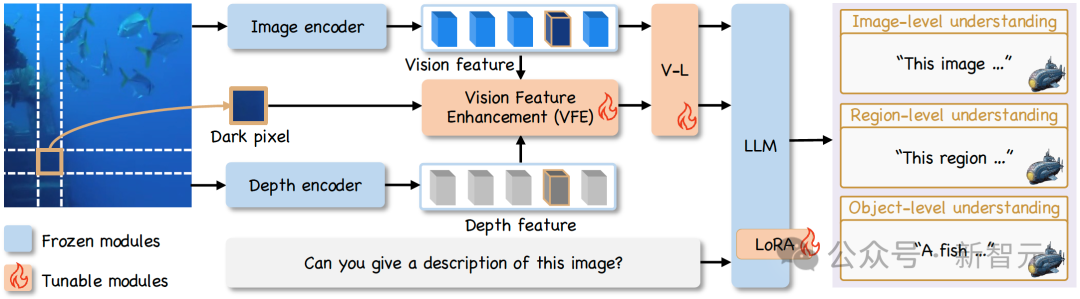
NAUTILUS 的框架主要由图像编码器、深度编码器、视觉特征增强(VFE)模块和大型语言模型组成。之前的研究通常将图像增强作为预处理步骤,这可能导致信息丢失。
此外,图像增强与模型训练的解耦会放大误差累积的风险,这一效应在处理采集自多变环境的大规模水下数据集时愈发明显。特征空间增强方法则通过实现端到端的优化,利用下游任务提供面向任务的监督,更适用于多任务模型设计。
因此,NAUTILUS通过在特征空间中进行增强,保留原始图像的完整信息,优化多任务场景理解表现。其核心在于即插即用的VFE模块,该模块的设计受到了水下成像物理模型的启发,旨在解决水下图像退化问题。
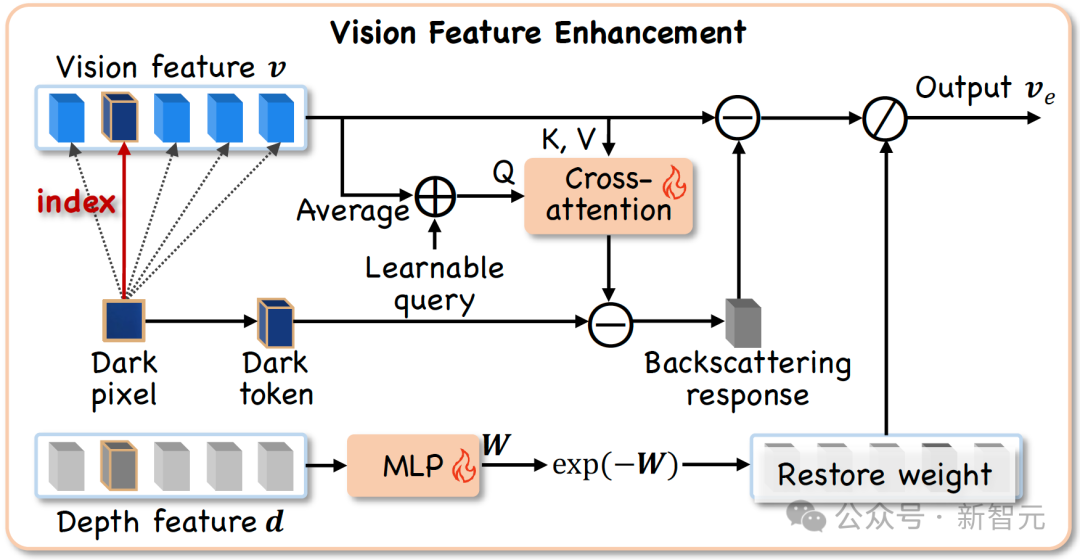
VFE模块的工作流程如下:
通过这两个步骤,VFE模块输出增强后的视觉特征,与原始特征一同送入大型语言模型,使其既能感知真实的水下环境,又能基于恢复后的清晰信息进行可靠的分析和理解。
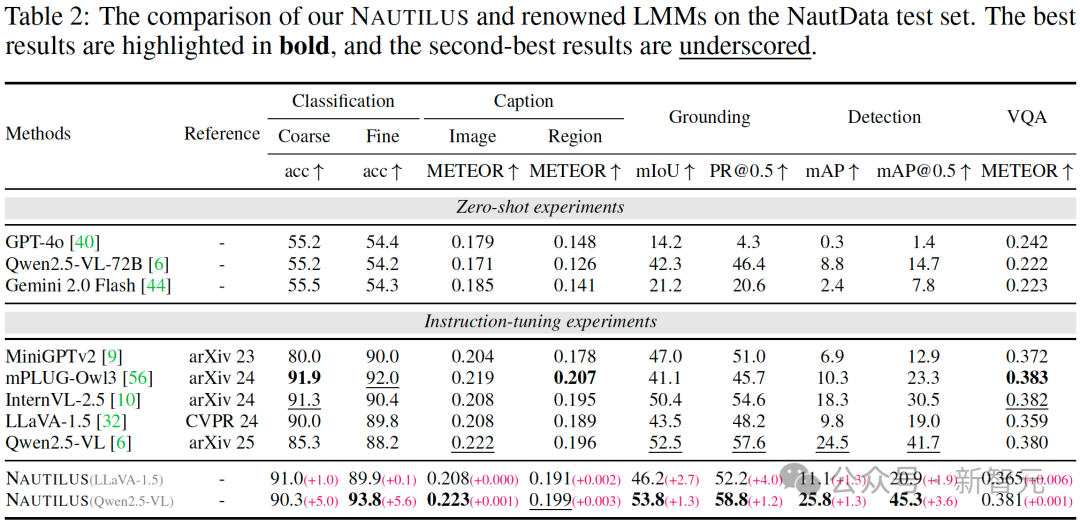
为验证模型性能,研究团队在 NautData 测试集上进行了全面的量化评估。
如下表所示,无论是基于LLaVA-1.5还是Qwen2.5-VL,NAUTILUS在分类、描述、定位、检测及视觉问答等多数核心任务上,其性能均显著优于现有的通用大模型及其他水下模型,展现了其卓越的综合理解能力。
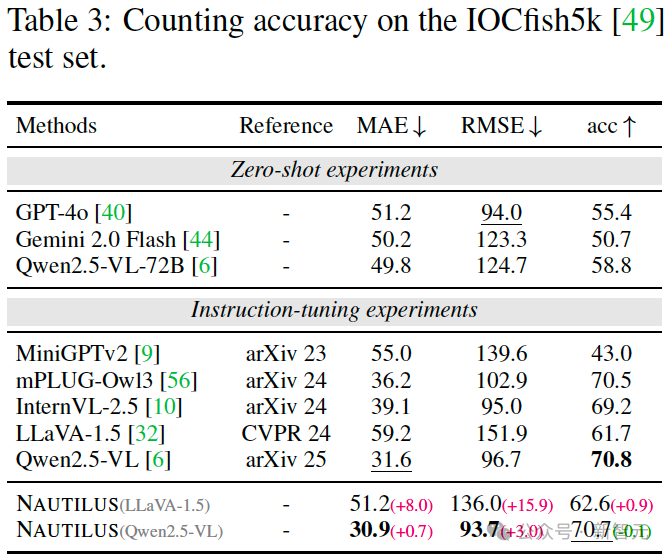
物体计数任务为评估模型的群体感知能力提供了有效途径。
为此,研究团队在 IOCfish5k 数据集上对 NAUTILUS的水下群体计数表现进行了评测。
实验结果表明,该模型在平均绝对误差(MAE)和均方根误差(RMSE)上均优于其他大型多模态模型,且相较于 LLaVA-1.5 基线分别取得了8.0和15.9的显著提升,展现了卓越的群体感知性能。
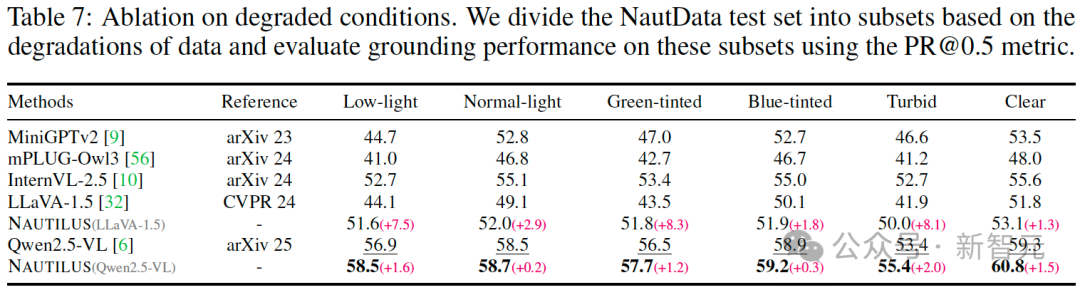
为评估模型在真实水下环境中的鲁棒性,研究团队考察了其在光照、色偏及浑浊等降质条件下的定位(grounding)性能。
基于NautData测试子集的实验表明,相较于 LLaVA-1.5 基线,NAUTILUS在低光、偏绿和浑浊场景下的 PR@0.5 指标分别取得了7.5、8.3和8.1的大幅提升,展现出其在多变视觉条件下的强大适应能力与性能稳定性。
下图的可视化结果进一步直观地展示了NAUTILUS强大的多任务处理能力。

从对整个场景的宏观描述,到对特定鱼群的精确计数与定位,再到对单一对象的细粒度属性问答,NAUTILUS在图像、区域、物体三个层级上均展现出精准、连贯的理解能力,生动体现了其作为水下场景理解基础模型的巨大潜力。
NAUTILUS作为首个支持八项水下场景理解任务的多模态大模型,为水下环境的综合感知提供了一个统一的解决方案。
以往的通用模型因水下图像降质而性能不佳,而现有的水下专用方法又大多为单一任务设计,限制了对场景的全面理解。
相比之下,NAUTILUS通过创新的视觉特征增强(VFE)模块在特征层面克服图像降质,并利用其多任务统一架构的优势,从而在多个基准测试中,尤其是在恶劣条件下,取得了超越先进模型的优异表现。
参考资料:
https://arxiv.org/abs/2510.27481
文章来自于“新智元”,作者 “LRST”。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
