# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
从影像诊断到手术指导,从多语言问诊到罕见病推理——
医学AI正在从“专科助手”进化为“全能型选手”。
而这就是浙江大学(吴健/刘佐珠课题组)、上海交通大学(谢伟迪课题组)、伊利诺伊大学厄巴纳-香槟分校(UIUC,Sun Jimeng课题组)联合阿里巴巴、湖南大学、新加坡A*STAR、中国移动、时代天使、浙江省医学影像人工智能重点实验室等机构联合提出的通用医学视觉语言大模型Hulu-Med,首次实现在一个单一模型中对医学文本、2D图像、3D体积和医学视频的统一理解。
简单来说,就是一个模型,看懂医学世界的所有。
而且作为开源模型,其训练数据均来自公开医学数据集及自研合成数据,不仅能大幅度降低GPU训练成本,更是在30项权威评测中展现出媲美GPT-4.1等闭源模型的优异性能。
这意味着学术机构及医疗开发者无需再依赖私有数据,即可复现并定制高性能医学模型,显著降低隐私与版权风险。

下面是有关Hulu-Med的更多详细内容。
医疗人工智能的发展正处在一个关键的十字路口。
过去,AI在医疗领域的应用呈现出单任务/单模态的局限性。研究者们针对放射影像、病理切片或手术视频等单一任务,开发了众多性能卓越的专用模型(Specialized Models)。
然而,这些模型架构各异、数据独立,如同一个个“信息孤岛”。当临床上需要综合分析同一位患者的多模态数据时,就必须拼凑一套复杂、昂贵的系统,这不仅维护成本高昂,更限制了AI从跨模态关联中学习和推理的能力。
如今,大语言模型和基础模型的兴起,为我们带来了实现“通用医学智能 (Generalist Medical AI)”的曙光,有望解决上述难题。
然而,这一浪潮也带来了一个更严峻的挑战:透明度的缺失(Lack of Transparency) 。许多领先的医疗AI系统,其训练数据来源、处理方法、模型架构甚至评估细节都常常秘而不宣 。这种不透明性是阻碍AI在医疗领域广泛应用的关键障碍 :
正是在碎片化与不透明这两大行业痛点并存的背景下,Hulu-Med应运而生,旨在提供一个真正统一(Unified)且完全透明(Transparent)的解决方案 。
研究团队秉持三大核心设计原则进行研发:全模态理解(Holistic Understanding)、规模化效率(Efficiency at Scale) 与端到端透明(End-to-End Transparency) 。
Hulu-Med旨在成为一个“医学多面手”,不仅能理解单一类型的数据,更能融会贯通,从整体上把握患者的健康状况。
Hulu-Med将透明度置于最高优先级,研究团队深信,开源开放是推动医学AI健康发展的必由之路。
Hulu-Med的训练完全基于公开可获取的数据集和合成数据,摆脱对私有、敏感数据的依赖 。
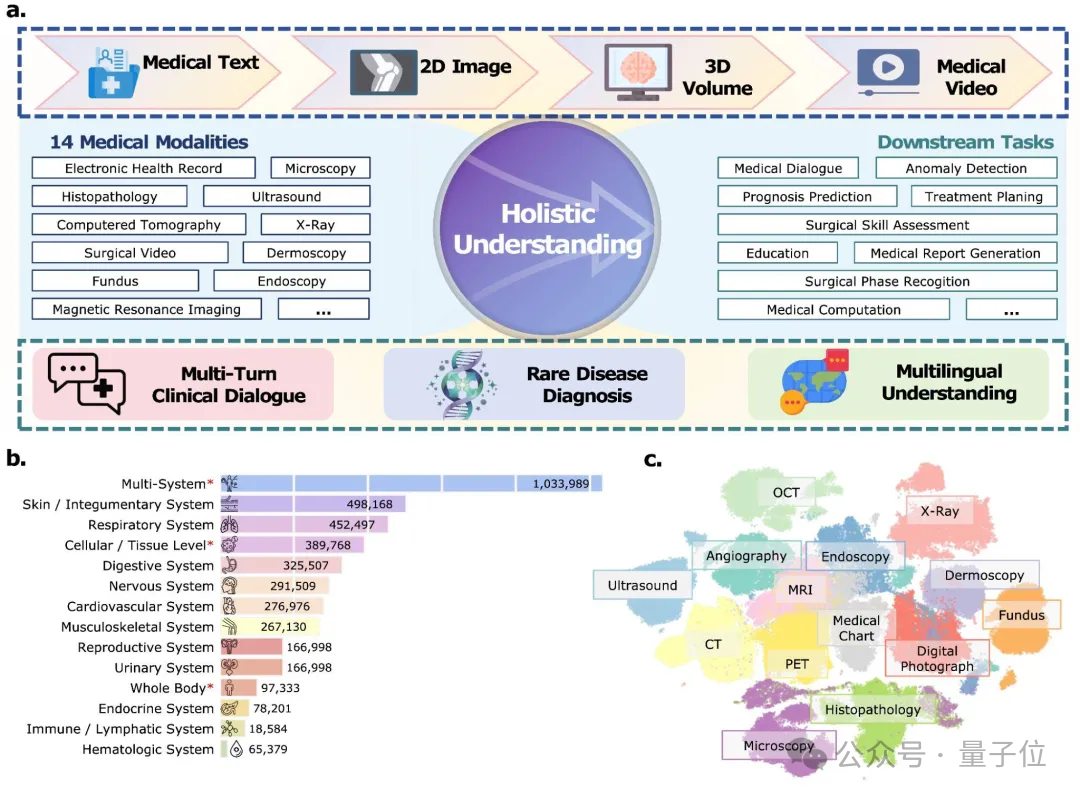
研究团队精心整理并构建了目前已知规模最大(1670万样本)的开放医学多模态语料库 ,该语料库覆盖了12个人体主要器官系统和14种主要医学影像模态(包括CT, MRI, X光, 病理等60多种具体类型) 。
公开数据往往存在模态覆盖不均、图文对齐质量参差不齐、长尾分布显著等问题。
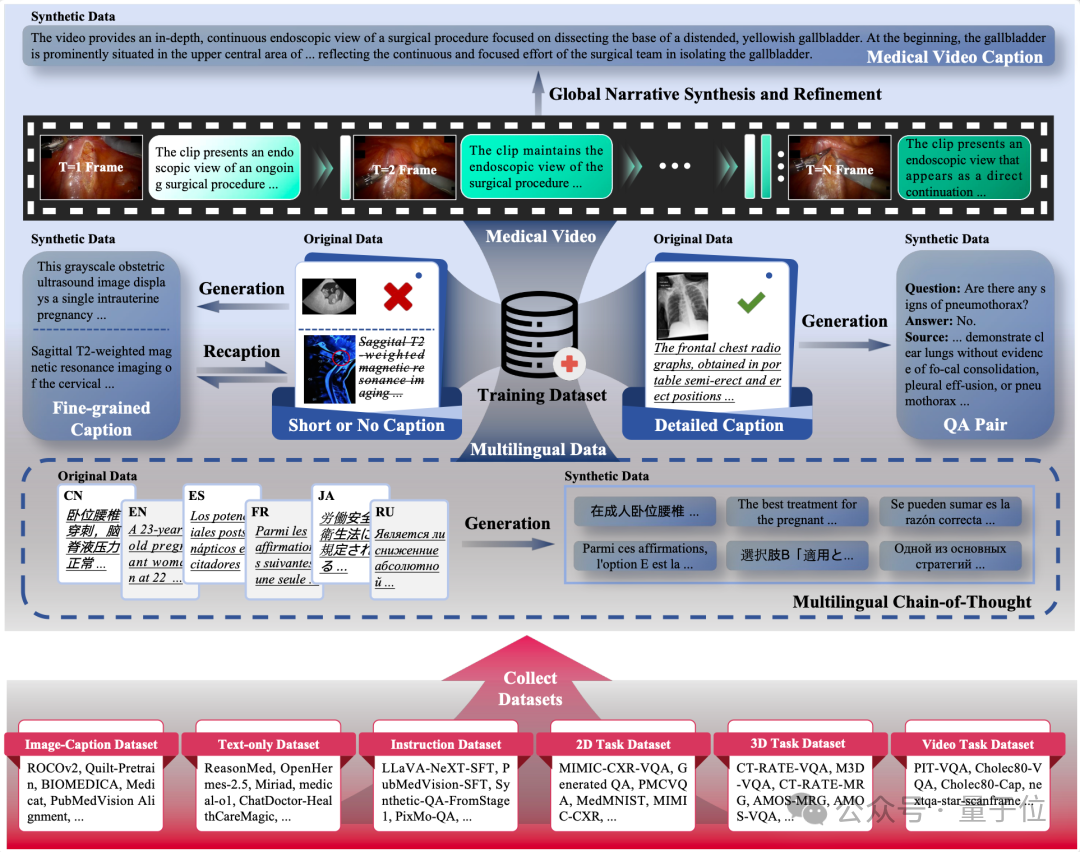
为了克服这些挑战,研究团队开发了5种专门的数据合成管线 ,能够将简短图注扩写为详细描述 、为无标注图像生成高质量长文本描述(尤其针对样本稀疏的模态) 、构建多样化的视觉问答对 、生成多语言长思维链(Long CoT)推理数据以及为缺乏标注的手术视频生成时序描述 。
这些高质量的合成数据(总计约286万样本)极大地丰富了训练语料,提升了模型的泛化能力和对复杂指令的理解力 。
研究团队公开整个研发管线,包括详细的数据筛选与合成流程、三阶段训练代码、所有基准测试的评估脚本,以及最终训练完成的所有模型权重 。
这意味着任何研究者都可以完全复现团队的工作,并在其基础上进行改进或针对特定应用进行微调。
这种彻底的开放性不仅有效规避了使用私有数据可能带来的隐私泄露和版权纠纷风险 ,更重要的是,它赋能了整个研究社区,降低了高质量医学AI的研发门槛,有助于催生更多定制化的、可信赖的医疗应用。
Hulu-Med在GitHub和HuggingFace上获得的积极反馈,近两周连续在HuggingFace medical trending榜单排名第一正是对开放策略的认可。
Hulu-Med的核心技术突破之一在于其创新的统一架构,首次实现了在单一模型内原生处理文本、2D图像、3D体积和医学视频四种核心模态。
传统VLM通常需要为不同视觉模态(如2D图像和3D体积)设计独立的编码器,或者采用将3D/视频数据拆解为2D帧序列的折衷方法,这限制了模型对空间或时间连续性的深度理解。
Hulu-Med则另辟蹊径:
采用先进的SigLIP视觉编码器,并将其与二维旋转位置编码(2D RoPE)相结合。
2D RoPE能够动态编码Patch在二维空间中的相对位置信息,无需预设固定的输入尺寸。
通过巧妙的设计,它将图像Patch视为跨所有视觉模态(2D图像、3D切片、视频帧)的通用处理单元,使得模型能够将3D体积数据视为切片序列、视频数据视为帧序列。
并在统一的Transformer架构内自然地理解其空间或时间上的连续性与关联性,而无需引入任何特定于3D或视频的复杂模块。
这种统一架构不仅支持任意分辨率的医学影像输入 ,还天然具备了强大的时空理解能力。
基于独立的视觉编码器与大型语言模型(LLM)解码器开展持续预训练和后训练,这提供了极大的灵活性,允许研究者根据具体需求,轻松替换或升级视觉编码器或LLM骨干(如使用不同规模或能力的Qwen系列模型),无需等待新版本通用VLM出现后再做医学场景后训练。
这种“原生”的多模态整合方式,相比于仅仅微调通用VLM的方法,更能保证数据使用的透明性,并强化领域特定的推理能力,是构建可靠临床AI系统的关键。
处理大规模医学数据,尤其是包含大量切片或帧的3D体积和视频数据,对计算资源提出了极高要求。
Hulu-Med通过一系列创新设计,成功实现了高性能与高效率的平衡。
针对3D和视频数据中普遍存在的帧间/层间信息冗余问题,研究团队提出了“医学感知令牌压缩”策略。
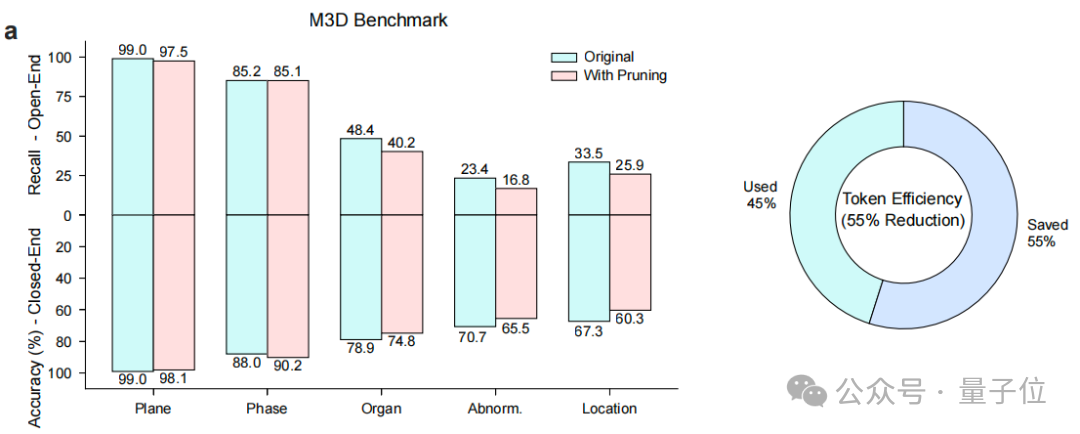
该策略结合了平面内双线性插值降采样和平面间基于L1距离的冗余令牌剪枝(Token Pruning),能够在几乎不损失模型性能的前提下,平均减少约55%的视觉令牌数量(如上图)。
这一显著的效率提升使得处理长达数小时的手术视频成为可能,并且极大地降低了模型推理时的内存和计算开销。
Hulu-Med采用了精心设计的渐进式三阶段训练流程。

第一阶段,冻结LLM,仅训练视觉编码器和Projector,利用海量的2D图像-短文本对建立基础的视觉-语言对齐。
第二阶段,进行持续预训练,引入长文本描述、通用数据,并解冻所有模型参数,旨在注入丰富的医学知识和通用视觉文本理解能力。
第三阶段,进行混合模态指令微调,引入包括3D、视频、多图、图文交错在内的多样化下游任务数据,全面提升模型的指令遵循和复杂推理能力。
这种“先易后难、逐步深入”的策略,充分利用了相对丰富的2D数据资源来构建强大的视觉表征基础,使得模型在后续面对数据量相对较少的3D和视频任务时能更快、更好地学习。
实验证明,这种渐进式训练显著优于将所有模态混合在一起的训练方式。
得益于高效的架构和训练策略,Hulu-Med的训练成本得到了有效控制。
即使是规模最大的32B参数模型,其总训练耗时也仅约4万个A100 GPU小时,而7B模型更是只需约4千GPU小时。
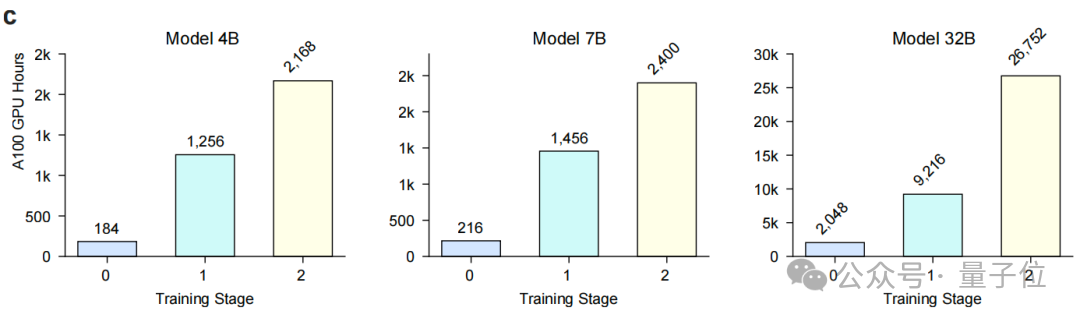
这意味着,在现实可及的计算预算内,即可开发出具备SOTA性能的通用医学VLM,极大地提高了先进医学AI技术的可及性。
为了全面评估Hulu-Med的能力,研究团队在30个公开的医学基准测试上进行了广泛严谨的评估。
这些基准从基础的文本问答、图像分类,到复杂的视觉问答(2D、3D、视频)、医学报告生成(2D、3D),再到需要深度临床知识和推理能力的多语言理解、罕见病诊断、多轮临床对话等各种任务类型,并同时考察了模型在分布内(ID)和分布外(OOD)任务上的泛化能力。
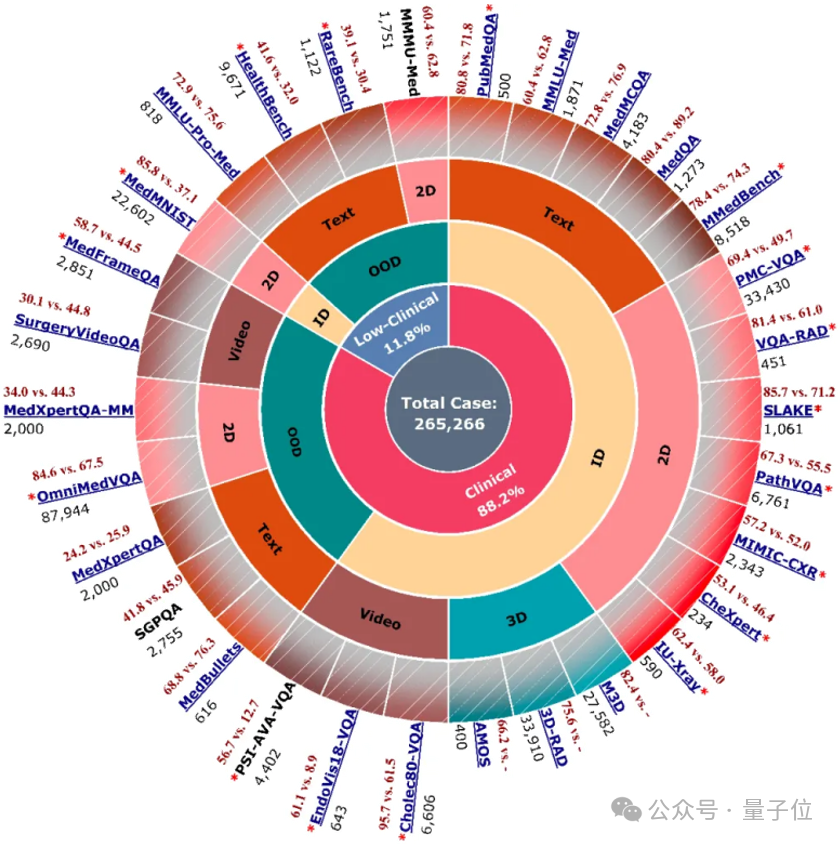
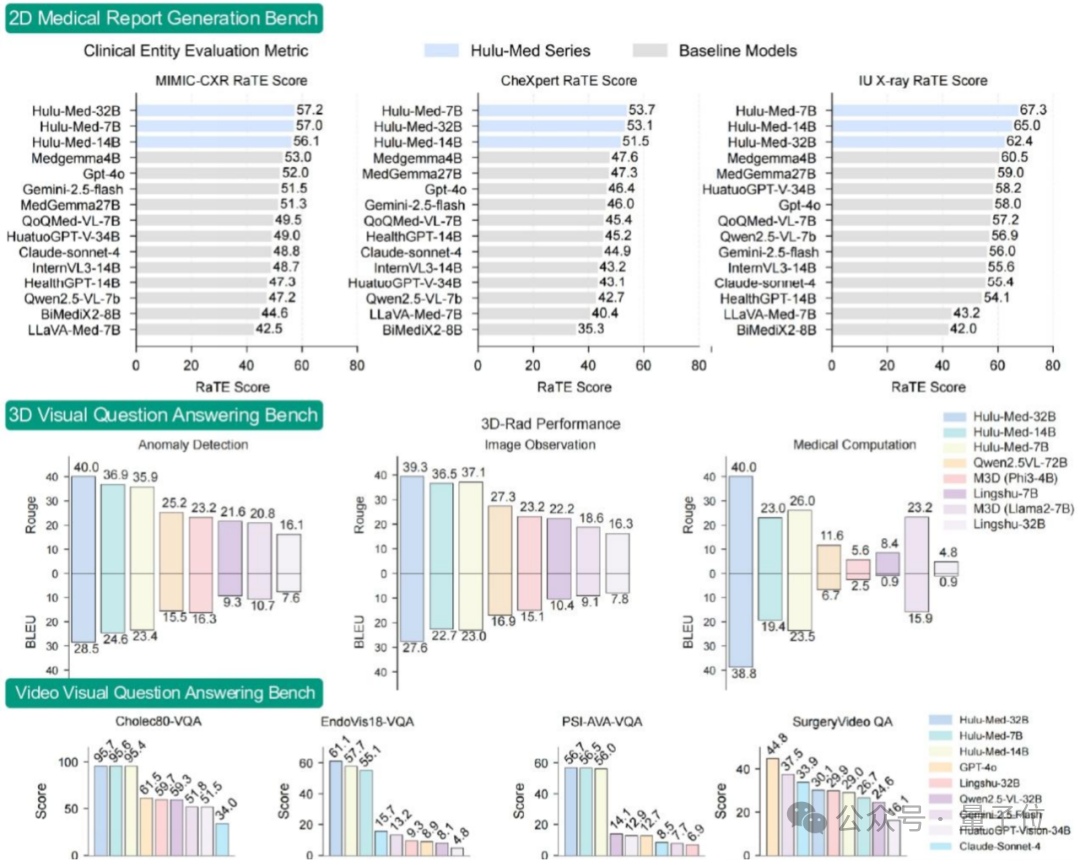
最终Hulu-Med的表现令人瞩目,如上图所示,在参与比较的30项基准中,Hulu-Med在其中27项均超越了现有的开源医学或通用VLM。
而且媲美甚至超越顶尖闭源系统,在其中16项基准中的性能优于强大的闭源模型GPT-4o。
尤其值得一提的是,尽管Hulu-Med是一个视觉语言模型,但在OpenAI最新提出的纯文本临床对话基准HealthBench上,其性能超越了GPT-4o,并与GPT-4.1持平 ,充分证明了其强大的文本理解和推理能力并未因多模态训练而削弱。
此外,无论是在2D医学VQA和报告生成(在体现临床价值的RaTEScore指标上尤为突出),还是在需要空间理解的3D VQA和报告生成(优于专门的3D模型),抑或是需要时序推理的视频理解任务(如MedFrameQA和多种手术VQA),Hulu-Med均展现了领先或极具竞争力的性能。
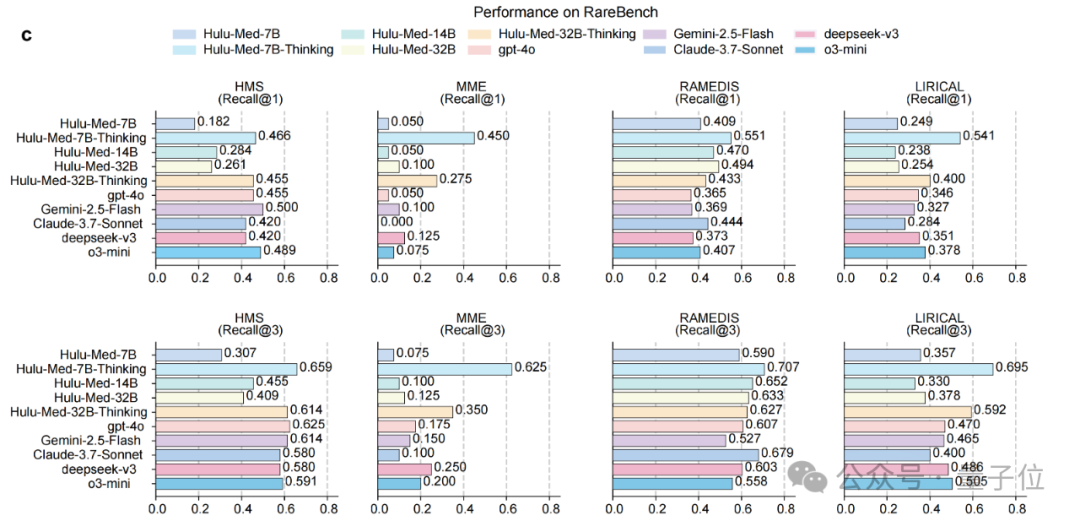
在模拟真实临床挑战的多语言医学理解(MMedBench,六种语言)、罕见病诊断(RareBench)和多轮临床安全对话(HealthBench)等任务上,Hulu-Med同样表现出色。
尤其在结合思维链(CoT)提示时,其在多语言和罕见病诊断上的表现超越了包括GPT-4在内的多个顶尖闭源模型 ,展现了其巨大的临床应用潜力(如上图)。
Hulu-Med的成功验证了通过系统性整合公开数据、采用统一高效架构、坚持完全开放透明的路径,是可以构建出世界一流的通用医学AI模型的。
尽管取得了显著进展,Hulu-Med仍有很多提升空间,未来的研究方向包括:
总的来说,Hulu-Med代表了迈向整体化、透明化、高效能医学AI的重要一步,它不仅是一个高性能的模型,更是一个开源开放的研究起点和一份详尽的技术蓝图。
研究团队坚信,开放与协作是推动医学AI领域可持续发展的关键,Hulu-Med在GitHub和HuggingFace等开源社区获得的初步成功,也印证了这一理念的价值。
同时,该团队也诚挚邀请相关领域的研究者、开发者和临床医生,利用Hulu-Med等开放模型和数据资源,共同探索、构建和验证下一代精准、普惠、个性化的医学人工智能系统!
论文链接:https://arxiv.org/abs/2510.08668
GitHub链接:https://github.com/ZJUI-AI4H/Hulu-Med
HuggingFace链接:https://huggingface.co/ZJU-AI4H/Hulu-Med-32B
文章来自于“量子位”,作者 “Hulu-Med团队”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
